MySQL小白教程来了
文章目录
- 前言
- 一、MySQL与Python的连接
- 二、基本语法
-
- 1.创建表
- 2.删除表
- 3.增
- 4.删
- 5.改
- 6.查
- 7.连接
- 三、高级语法
-
- 1.null值处理
- 2.正则表达式
- 3.事务
- 4.复制表
- 5.处理重复数据
- 6.导出数据
- 7.函数
- 总结
前言
sql已经满足不了,所以mysql就来了!
一、MySQL与Python的连接
已安装了pymysql模块
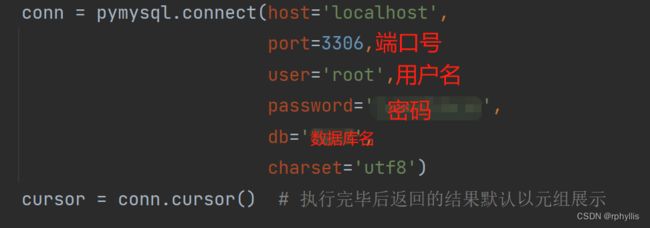
sql = ‘select * from ...’
cursor.execute(sql)
conn.commit()
cursor.close()
conn.close()
二、基本语法
1.创建表
create table if not exits 表名(
列名 数据类型 ..;
..
);
AUTO_INCREMENT定义列为自增的属性
PRIMARY KEY关键字用于定义列为主键
2.删除表
drop table 表名;
3.增
insert into 表名 (字段1,字段2...)values(值1,值2...);
4.删
delete table 表名
where ..
(参考ilavac)
delete,drop,truncate 都有删除表的作用,区别在于:
1、delete 和 truncate 仅仅删除表数据,drop 连表数据和表结构一起删除,打个比方,delete 是单杀,truncate 是团灭,drop 是把电脑摔了。
2、delete 是 DML 语句,操作完以后如果没有不想提交事务还可以回滚,truncate 和 drop 是 DDL 语句,操作完马上生效,不能回滚,打个比方,delete 是发微信说分手,后悔还可以撤回,truncate 和 drop 是直接扇耳光说滚,不能反悔。
3、执行的速度上,drop>truncate>delete,打个比方,drop 是神舟火箭,truncate 是和谐号动车,delete 是自行车。
5.改
- update
update 表名 SET 字段1=新值, 字段2=新值..
where ...
~ UPDATE替换某个字段中的某个字符
update 表名 set 字段 = replace(字段,旧值,新值)
where…
- alter 删除,添加或修改表字段
~ 删除表字段
alter table 表 drop 字段名
~向表增加列
alter table 表 add 字段名 数据类型
~修改字段类型及名称
修改字段类型
alter table 表 modify 字段 新类型
修改字段名+数据类型
alter table 表 change 旧字段名 新字段名 数据类型
6.查
通用语法
select .. from ..
where ...
group by ..
order by...
limit n offset m
(limit n 表示返回的记录数,offset m表示跳过前m条)
- where子句
binary关键字,设定 where子句的字符串比较是区分大小写的
where子句本身不区分大小写
select .. from .. where binary ..
like模糊查询
%:表示任意 0 个或多个字符
_:表示任意单个字符
- order by
SELECT field1, field2,...fieldN
FROM table_name1, table_name2...
ORDER BY field1 [ASC [DESC][默认 ASC]], [field2...] [ASC [DESC][默认 ASC]]
mysql拼音排序
1.如果字符集采用的是 gbk(汉字编码字符集),直接在查询语句后边添加 ORDER BY:
2.如果字符集采用的是 utf8(万国码),需要先对字段进行转码然后排序:
order by convert(... using gbk)
- group by
SELECT column_name, function(column_name)
FROM table_name
WHERE column_name operator value
GROUP BY column_name;
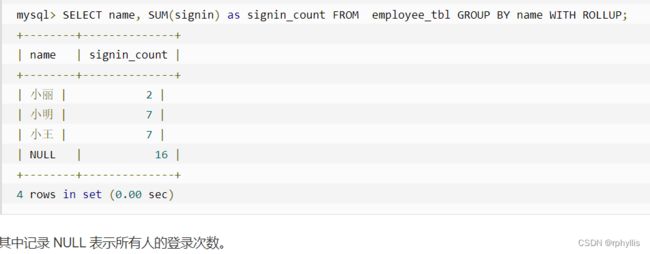
使用with rollup 实现在分组统计数据基础上再进行相同的统计(SUM,AVG,COUNT…)
#参考菜鸟教程如下
我们将以上的数据表按名字进行分组,再统计每个人登录的次数
可以使用 coalesce 来设置一个可以取代 NUll 的名称,coalesce 语法
select coalesce(a,b,c);
参数说明:如果a=null,则选择b;如果b==null,则选择c;如果a!=null,则选择a;如果a b c 都为null ,则返回为null(没意义)


7.连接
- union
MySQL UNION 操作符用于连接两个以上的 SELECT 语句的结果组合到一个结果集合中。多个 SELECT 语句会删除重复的数据。
select .. from ...
where ...
union [all/distinct]
select .. from ...
where ...
distinctc 删除结果集中重复的数据。但默认就是删除重复数据
all 返回所有结果集,包含重复数据
- inner join(内连接/等值连接)
- left join 左连接
- right 右连接
select .. from 表1 inner join/left join/right join
表2 on 两张表相同的列名
三、高级语法
1.null值处理
IS NULL: 当列的值是 NULL,此运算符返回 true。
IS NOT NULL: 当列的值不为 NULL, 运算符返回 true。
<=>: 比较操作符(不同于 = 运算符),当比较的的两个值相等或者都为 NULL 时返回 true。
ifnull函数()
ifnull(列名,0) --> 如果列为null,则将null值处理为0
2.正则表达式
使用 REGEXP 操作符来进行正则表达式匹配
-
^ 匹配输入字符串的开始位置。如果设置了 RegExp 对象的 Multiline 属性,^ 也匹配 ‘\n’ 或 ‘\r’ 之后的位置。
-
$ 匹配输入字符串的结束位置。如果设置了RegExp 对象的 Multiline 属性,$ 也匹配 ‘\n’ 或 ‘\r’ 之前的位置。
-
. 匹配除 “\n” 之外的任何单个字符。要匹配包括 ‘\n’ 在内的任何字符,请使用像 ‘[.\n]’ 的模式。
-
[…] 字符集合。匹配所包含的任意一个字符。例如, ‘[abc]’ 可以匹配 “plain” 中的 ‘a’。
-
[^…] 负值字符集合。匹配未包含的任意字符。例如, ‘[^abc]’ 可以匹配 “plain” 中的’p’。
-
p1|p2|p3 匹配 p1 或 p2 或 p3。例如,‘z|food’ 能匹配 “z” 或 “food”。‘(z|f)ood’ 则匹配 “zood” 或 “food”。
-
{n} n 是一个非负整数。匹配确定的 n 次。例如,‘o{2}’ 不能匹配 “Bob” 中的 ‘o’,但是能匹配 “food” 中的两个 o。
-
{n,m} m 和 n 均为非负整数,其中n <= m。最少匹配 n 次且最多匹配 m 次。
、* 匹配前面的子表达式零次或多次。例如,zo* 能匹配 “z” 以及 “zoo”。* 等价于{0,}。
3.事务
以python代码为例
try:
conn = pymysql.connect()
cursor = conn.cursor() # 执行完毕后返回的结果默认以元组展示
sql='....'
conn.commit()
except:
traceback.print_exc()
finally:
cursor.close()
conn.close()
4.复制表
create table 新表名 as(
select .. from .. where ..
)
5.处理重复数据
- 防止表中出现重复数据 (设置主键或unique约束)
create table 表名(
列名1 数据类型,
列名2 数据类型,
...
PRIMARY KEY (要设置主键的列名)
)
- 统计重复数据
select count(*) as num,列名1,列名2 from table
group by 列名1,列名2
having num>1
- 过滤重复数据 distinct
select distinct .. from ..
- 删除重复数据
6.导出数据
select ... from ...
into outfile '路径';

7.函数
菜鸟教程有各种函数的介绍
点击这里
总结
学会这篇,mysql就基本掌握
多学多练多敲