「深度学习之优化算法」笔记(三)之粒子群算法
1. 粒子群算法简介
粒子群算法(Particle Swarm Optimization,PSO)是一种模仿鸟群、鱼群觅食行为发展起来的一种进化算法。其概念简单易于编程实现且运行效率高、参数相对较少,应用非常广泛。粒子群算法于1995年提出,距今(2019)已有24年历史。
粒子群算法中每一个粒子的位置代表了待求问题的一个候选解。每一个粒子的位置在空间内的好坏由该粒子的位置在待求问题中的适应度值决定。每一个粒子在下一代的位置有其在这一代的位置与其自身的速度矢量决定,其速度决定了粒子每次飞行的方向和距离。在飞行过程中,粒子会记录下自己所到过的最优位置 P,群体也会更新群体所到过的最优位置G 。粒子的飞行速度则由其当前位置、粒子自身所到过的最优位置、群体所到过的最优位置以及粒子此时的速度共同决定。
2. 算法流程
上面介绍了粒子群算法来历,过程。没有了解过的小伙伴肯定是一脸萌容。不过这已经是优化算法中最简单、最没有心机的算法了,也是入门优化算法的不二选择。

好了,正篇开始。这是一个根据鸟群觅食行为衍生出的算法。现在,我们的主角是一群鸟。

小鸟们的目标很简单,要在这一带找到食物最充足的位置安家、休养生息。它们在这个地方的搜索策略如下:
1. 每只鸟随机找一个地方,评估这个地方的食物量。
2. 所有的鸟一起开会,选出食物量最多的地方作为安家的候选点G。
3. 每只鸟回顾自己的旅程,记住自己曾经去过的食物量最多的地方P。
4. 每只鸟为了找到食物量更多的地方,于是向着G飞行,但是呢,不知是出于选择困难症还是对P的留恋,或者是对G的不信任,小鸟向G飞行时,时不时也向P飞行,其实它自己也不知道到底是向G飞行的多还是向P飞行的多。
5. 又到了开会的时间,如果小鸟们决定停止寻找,那么它们会选择当前的G来安家;否则继续2->3->4->5来寻找它们的栖息地。
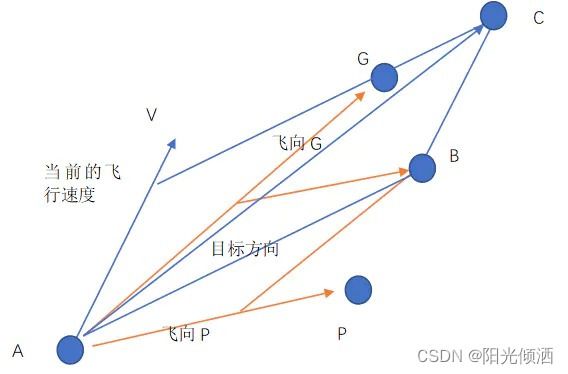
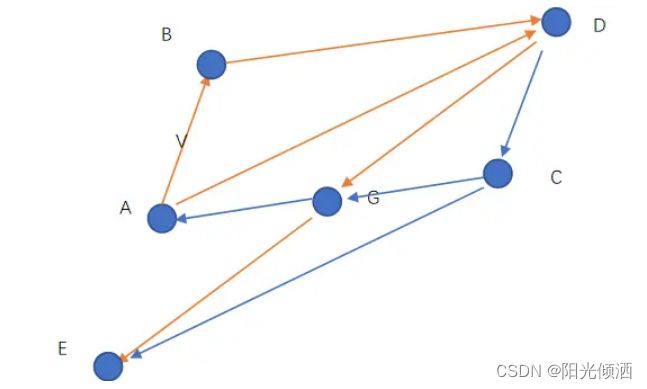
上图描述的策略4的情况,一只鸟在点A处,点G是鸟群们找到过的食物最多的位置,点P是它自己去过的食物最多的地点。V是它现在的飞行速度(速度是矢量,有方向和大小),现在它决定向着P和G飞行,但是这是一只佛系鸟,具体飞多少随缘。如果没有速度V,它应该飞到B点,有了速度V的影响,它的合速度最终使它飞到了点C,这里是它的下一个目的地。如果C比P好那么C就成了下一次的P,如果C比G好,那么就成了下一次的G。
具体的飞行过程如下图所示:
算法的流程如下:

3.粒子群算法模型
介绍完了粒子群算法的流程,再来详细介绍一下粒子群算法的模型。
鸟群有三个决定其搜索结果的参数
C1:自我学习因子
C2:全局学习因子
W:惯性系数
maxV:最大速率。
对于每只鸟,有两个属性:
位置:![]()
速度:![]()
其中t表示第t次迭代(第t次开会),i表是这只鸟的序号是i,D表示搜索空间的维度,对于鸟群来说D=2(在平面内搜寻)。
其速度更新公式如下:
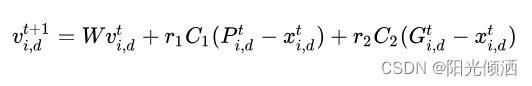
r1,r2表示均匀分布在(0,1)内的随机数。
位置更新公式如下:

4.实验初步
上面都是些什么鬼,完全看不懂……,很正常,下面我们来个例子看看上面那些都是什么东西。
C1:自我学习因子,就是一只鸟飞向自己到过的最优位置的权重,可以理解为C1越大,该鸟飞向自己到过的最优位置的意愿越强烈。
C2:全局学习因子,也叫社会学习因子,即一只鸟飞向群体到过的最优位置的权重, C2越大,该鸟飞向群体到过的最优位置的意愿越强烈。
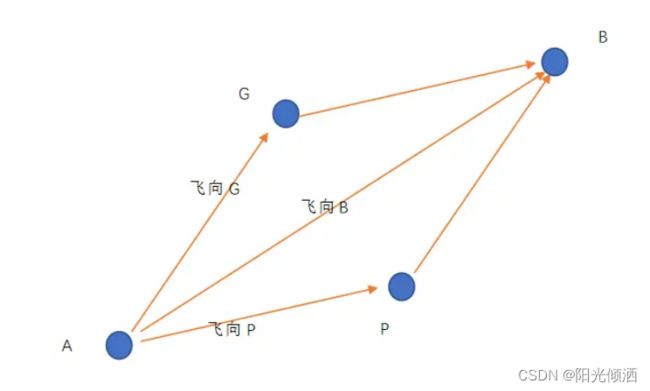
如上图,假设随机变量r1=r2=1,如果该鸟当前速度V=0,C1=C2=1时,,则该鸟的速度为A->B,它将飞到B点,若C1=0,C2=1,则该鸟将飞到G点,若C1=1,C2=0,则鸟将飞到P点。
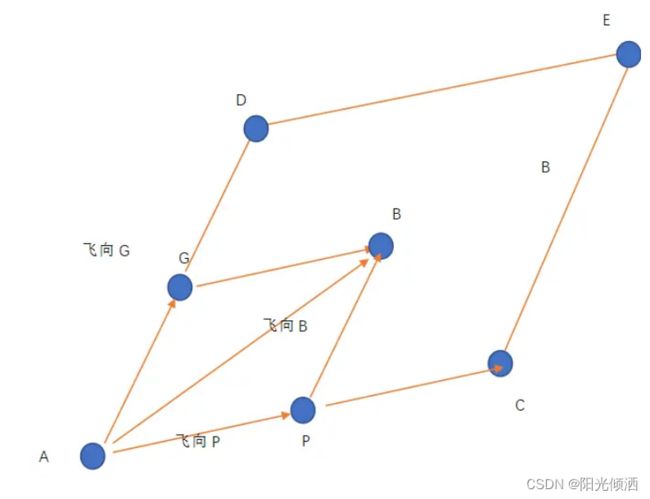
一般,取C1=C2=2,由于r1和r2为(0-1)的随机数,在速度V=0的情况下,该鸟可能从点A飞到平行四边形ADEC内的任一位置,其中AG=GD,AP=PC。点B为该鸟飞向的期望位置。
W为惯性系数,即鸟在下一次飞行时将会以上一次的速度为基础,根据自己的意愿的出最终的速度。
举个简单的例子,搜索平面内距点M最近的点。这是一个二维的问题,假设M的坐标为(a,b),我们可以该问题转化为求使![]() 的值最小的一组解
的值最小的一组解![]() ,那么粒子群算法的适应度函数为
,那么粒子群算法的适应度函数为![]() 。
。
实验开始了
| 参数 |
值 |
| 问题维度(维度) |
2 |
| 鸟的数量(种群数) |
20 |
| 开会次数(最大迭代次数) |
50 |
| C1 |
2 |
| C2 |
2 |
| W |
1 |
| maxV |
5 |
| 取值范围 |
(-100,100) |
为了方便求解我们设M点为原点,即a=b=0。

此时问题为在上图的区域内寻找距原点最近的点的坐标。我们看一下粒子群算法的寻找过程。
可以发现所有的小鸟都向着我们的目标点不断的靠近。它们最终收敛在了一个很小的范围内。我们所得到的最终的结果是(0.01559301434688,-0.113289020661651),该点距原点距离为的平方为0.014876507,虽然很近了,但这可不是一个较好的结果。
虽然小鸟们已经聚集在了最优点附近的小范围内,但却没有进一步向原点靠近。这是为什么呢,下一节我们一起来研究一下。
5.参数实验
上一节中,我们看到小鸟们聚集到一个较小的范围内后,不会再继续集中。这是怎么回事呢?
猜测:
1.与最大速度限制有关,权重w只是方便动态修改maxV。
2.与C1和C2有关,这两个权重限制了鸟儿的搜索行为。
还是上一节的实验, 。现在我们将maxV的值有5修改为50,即maxV=50,其他参数不变。参数如下
。现在我们将maxV的值有5修改为50,即maxV=50,其他参数不变。参数如下
| 参数 |
值 |
| 问题维度(维度) |
2 |
| 鸟的数量(种群数) |
20 |
| 开会次数(最大迭代次数) |
50 |
| C1 |
2 |
| C2 |
2 |
| W |
1 |
| maxV |
50 |
| 取值范围 |
(-100,100) |
此时得到的最优位值的适应度函数值为0.25571,可以看出与maxV=5相比,结果差了很多而且小鸟们聚集的范围更大了。
现在我们设置maxV=1,再次重复上面的实验,实验结果如下:
这次最终的适应度函数值为,比之前的结果都要好0.00273。从图中我们可以看出,小鸟们在向一个点集中,但是他们飞行的速度比之前慢多了,如果问题更复杂,可能无法等到它们聚集到一个点,迭代就结束了。
为什么maxV会影响鸟群的搜索结果呢?
我们依然以maxV=50为例,不过这次为了看的更加清晰,我们的鸟群只有2只鸟,同时将帧数放慢5倍以便观察。
| 参数 |
值 |
| 问题维度(维度) |
2 |
| 鸟的数量(种群数) |
2 |
| 开会次数(最大迭代次数) |
50 |
| C1 |
2 |
| C2 |
2 |
| W |
1 |
| maxV |
50 |
| 取值范围 |
(-100,100) |
可以看出若当前的惯性速度V较大时,且P、G相距较近时(考虑极端情况P与G重合在一个点),我们来看看小鸟的飞行轨迹。

小鸟从A点出发,速度为A->B,这一次飞行过后,小鸟的期望位置为点D,将此次飞行记为第一次飞行。其中AG=GC,由于P=G,故
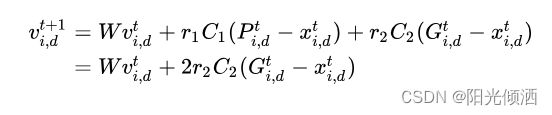
第二次飞行,小鸟由点D为起点,此时小鸟的惯性速度为A->D,而它向目标飞行的速度为D->E,其中DG=GE,此次飞行的合速度为D->C,故C为此次飞行的期望点位置。

第三次飞行,小鸟由点C为起点,此时小鸟的惯性速度为D->C,而它向目标飞行的速度为C->A,其中CG=GA,此次飞行的合速度为C->E,故E为此次飞行的期望点位置。
第四次飞行,小鸟由点E为起点,此时小鸟的惯性速度为C->E,而它向目标飞行的速度为E->D其中EG=GD,此次飞行的合速度为E->A,故A为此次飞行的期望点位置。

可以看出如果G和P重合,那么小鸟的飞行轨迹的期望为A->D->C->E->A,如果这四个位置均差于全局最优点G和自己的历史最优点P,那么小鸟将会一直围着当前最优点打转,这样当然无法继续聚集在同一个点。
问题找到了,那应该如何解决呢?先思考几种方案,能不能行的通,实验之后见分晓。思路一:限制鸟的最大飞行速率,由于惯性系数W的存在,使得控制最大速率和控制惯性系数的效果是等价的,取其一即可。
方案1:使惯性系数随着迭代次数增加而降低,这里使用的是线性下降的方式,即在第1次迭代,惯性系数W=1,最后一次迭代时,惯性系数W=0,当然,也可以根据自己的意愿取其他值。
实验参数如下:
| 参数 |
值 |
| 问题维度(维度) |
2 |
| 鸟的数量(种群数) |
20 |
| 开会次数(最大迭代次数) |
50 |
| C1 |
2 |
| C2 |
2 |
| W |
1->0 |
| maxV |
50 |
| 取值范围 |
(-100,100) |
小鸟们的飞行过程如上图,可以看到效果很好,最后甚至都聚集到了一个点。再看看最终的适应度函数值8.61666413451519E-17,这已经是一个相当精确的值了,说明这是一个可行的方案,但是由于其最后种群过于集中,有陷入局部最优的风险。
方案2:给每只鸟一个随机的惯性系数,那么鸟的飞行轨迹也将不再像之前会出现周期性。每只鸟的惯性系数W为(0,2)中的随机数(保持W的期望为1)。
实验参数如下:
| 参数 |
值 |
| 问题维度(维度) |
2 |
| 鸟的数量(种群数) |
20 |
| 开会次数(最大迭代次数) |
50 |
| C1 |
2 |
| C2 |
2 |
| W |
rand(0,2) |
| maxV |
50 |
| 取值范围 |
(-100,100) |
可以看到小鸟们并没有像上一个实验一样聚集于一个点,而是仍在一个较大的范围内进行搜索。其最终的适应度函数为0.01176,比最初的0.25571稍有提升,但并不显著。什么原因造成了这种情况呢?我想可能是由于惯性系数成了期望为1的随机数,那么小鸟的飞行轨迹的期望可能仍然是绕着一个四边形循环,只不过这个四边形相比之前的平行四边形更加复杂,所以其结果也稍有提升,当然对于概率算法,得到这样的结果可能仅仅是因为运气不好
我们看到惯性系数W值减小,小鸟们聚拢到一处的速度明显提升,那么,如果我们去掉惯性系数这个参数会怎么样呢。
方案3:取出惯性系数,即取W=0,小鸟们只向着那两个最优位置飞行。
| 参数 |
值 |
| 问题维度(维度) |
2 |
| 鸟的数量(种群数) |
20 |
| 开会次数(最大迭代次数) |
50 |
| C1 |
2 |
| C2 |
2 |
| W |
0 |
| maxV |
50 |
| 取值范围 |
(-100,100) |
可以看见鸟群们迅速聚集到了一个点,再看看得到的结果,最终的适应度函数值为2.9086886073362966E-30,明显优于之前的所有操作。
那么问题来了,为什么粒子群算法需要一个惯性速度,它的作用是什么呢?其实很明显,当鸟群迅速集中到了一个点之后它们就丧失了全局的搜索能力,所有的鸟会迅速向着全局最优点飞去,如果当前的全局最优解是一个局部最优点,那么鸟群将会陷入局部最优。所以,惯性系数和惯性速度的作用是给鸟群提供跳出局部最优的可能性,获得这个跳出局部最优能力的代价是它们的收敛速度减慢,且局部的搜索能力较弱(与当前的惯性速度有关)。
为了平衡局部搜索能力和跳出局部最优能力,我们可以人为的干预一下惯性系数W的大小,结合方案1和方案2,我们可以使每只鸟的惯性系数以一个随机周期,周期性下降,若小于0,则重置为初始值。

这样结合了方案1和方案2的惯性系数,也能得到不错的效果,大家可以自己一试。
思路二:改变小鸟们向群体最优飞行和向历史最优飞行的权重。
方案4:让小鸟向全局最优飞行的系数C2线性递减。
| 参数 |
值 |
| 问题维度(维度) |
2 |
| 鸟的数量(种群数) |
20 |
| 开会次数(最大迭代次数) |
50 |
| C1 |
2 |
| C2 |
2->0 |
| W |
1 |
| maxV |
50 |
| 取值范围 |
(-100,100) |
小鸟们的飞行过程与之前好像没什么变化,我甚至怀疑我做了假实验。看看最终结果,0.7267249621552874,这是到目前为止的最差结果。看来这不是一个好方案,让全局学习因子C2递减,势必会降低算法的收敛效率,而惯性系数还是那么大,小鸟们依然会围绕历史最优位置打转,毕竟这两个最优位置是有一定关联的。所以让C1线性递减的实验也不必做了,其效果应该与方案4相差不大。
看来只要是惯性系数不变怎么修改C1和C2都不会有太过明显的效果。为什么实验都是参数递减,却没有参数递增的实验呢?
1.惯性系数W必须递减,因为它会影响鸟群的搜索范围。
2.如果C1和C2递增,那么小鸟的惯性速度V势必会跟着递增,这与W递增会产生相同的效果。
6.总结
上面我们通过一些实验及理论分析了粒子群算法的特点及其参数的作用。粒子群作为优化算法中模型最简单的算法,通过修改这几个简单的参数也能够改变算法的优化性能可以说是一个非常优秀的算法。
上述实验中,我们仅分析了单个参数对算法的影响,实际使用时(创新、发明、写论文时)也会同时动态改变多个参数,甚至是参数之间产生关联。
实验中,为了展现实验效果,maxV取值较大,一般取值为搜索空间范围的10%-20%,按上面(-100,100)的范围maxV应该取值为20-40,在此基础上,方案1、方案2效果应该会更好。
粒子群算法是一种概率算法,所以并不能使用一次实验结果来判断算法的性能,我们需要进行多次实验,然后看看这些实验的效果最终来判断,结果必须使用多次实验的统计数据来说明,一般我们都会重复实验30-50次,为了发论文去做实验的小伙伴们不要偷懒哦。
粒子群算法的学习目前告一段落,如果有什么新的发现,后面继续更新哦!
以下指标纯属个人yy,仅供参考
| 指标 |
星数 |
| 复杂度 |
★☆☆☆☆☆☆☆☆☆ |
| 收敛速度 |
★★★★★☆☆☆☆☆ |
| 全局搜索 |
★★★★☆☆☆☆☆☆ |
| 局部搜索 |
★★★★★★☆☆☆☆ |
| 优化性能 |
★★★★★★☆☆☆☆ |
| 跳出局部最优 |
★★★★☆☆☆☆☆☆ |
| 改进点 |
★★★★☆☆☆☆☆☆ |
参考文献
[1]J. Kennedy and R.C. Eberhart. “Particle swarm optimization.” In IEEE international Conference on Neural Networks, volume 4,IEEE Press, 1995, pp. 1942–1948.