测试开发面经
操作系统
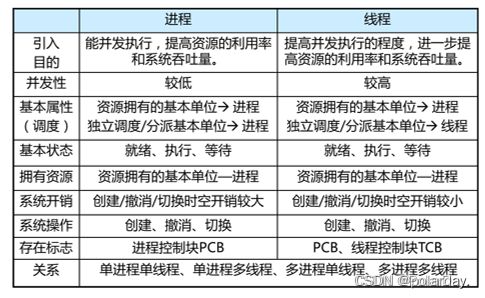
进程与线程
进程间通信方式
进程间的六种通信方式
- 管道
- 消息队列
- 共享内存
- 信号量
- 信号
- 套接字
socket长连接和短连接
长连接与短连接的概念:前者是整个通讯过程,客户端和服务端只用一个Socket对象,长期保持Socket的连接;后者是每次请求,都新建一个Socket,处理完一个请求就直接关闭掉Socket。所以,其实区分长短连接就是:整个客户和服务端的通讯过程是利用一个Socket还是多个Socket进行的
同步和异步的区别
同步,可以理解为在执行完一个函数或方法之后,一直等待系统返回值或消息,这时程序是处于阻塞的,只有接收到返回的值或消息后才往下执行其他的命令。 (打电话)
异步,执行完函数或方法后,不必阻塞性地等待返回值或消息,只需要向系统委托一个异步过程,那么当系统接收到返回值或消息时,系统会自动触发委托的异步过程,从而完成一个完整的流程。(发短信)
计算机网络
HTTP状态码
状态码详解
1xx : 消息,这一类型的状态码,代表请求已被接受,需要继续处理。但是一般服务器禁止向客户端发送此类状态码;
2xx : 成功,这一类型的状态码,代表请求已成功被服务器接收、理解、并接受;
3xx : 重定向,这类状态码代表需要客户端采取进一步的操作才能完成请求;
4xx : 请求错误,这类的状态码代表了客户端看起来可能发生了错误,妨碍了服务器的处理;
5xx : 服务器错误,这类状态码代表了服务器在处理请求的过程中有错误或者异常状态发生,也有可能是服务器意识到以当前的软硬件资源无法完成对请求的处理。
200:(成功) 服务器已成功处理了请求。 通常,这表示服务器提供了请求的网页。
301 – (永久移动) 请求的网页已永久移动到新位置。 服务器返回此响应(对 GET 或 HEAD 请求的响应)时,会自动将请求者转到新位置。
302 – (临时移动) 服务器目前从不同位置的网页响应请求,但请求者应继续使用原有位置来进行以后的请求。
401:请求未通过认证
403:请求通过认证但没有授权
404:服务器找不到请求的网页。
500:表示服务器内部异常
503:表示服务器正处于超负载或者正在进行停机维护,无法处理请求
504:表示服务器请求超时,没有返回结果
体系结构

TCP与UDP的区别
-
TCP 面向连接(如打电话要先拨号建立连接)提供可靠的服务,UDP 是无连接的,即发送数据之前不需要建立连接,UDP 尽最大努力交付,即不保证可靠交付。
-
UDP 具有较好的实时性,工作效率比 TCP 高,适用于对高速传输和实时性有较高的通信或广播通信。
-
每一条 TCP 连接只能是一对一的,UDP 支持一对一,一对多,多对一和多对多的交互通信。
-
UDP 分组首部开销小,TCP 首部开销 20 字节,UDP 的首部开销小,只有 8 个字节。
-
TCP 面向字节流,实际上是 TCP 把数据看成一连串无结构的字节流,UDP 是面向报文的一次交付一个完整的报文,报文不可分割,报文是 UDP 数据报处理的最小单位。
-
UDP 适合一次性传输较小数据的网络应用,如 DNS,SNMP 等。
TCP长连接和短连接
TCP长连接和短链接的区别及应用场景
三次握手四次挥手
面试官,不要再问我三次握手和四次挥手
输入域名后经过了什么

Get和Post的区别
1.get请求一般是去取获取数据(其实也可以提交,但常见的是获取数据);
post请求一般是去提交数据。
2.get因为参数会放在url中,所以隐私性,安全性较差,请求的数据长度是有限制的,
不同的浏览器和服务器不同,一般限制在 2~8K 之间,更加常见的是 1k 以内;
post请求是没有的长度限制,请求数据是放在body中;
3.get请求刷新服务器或者回退没有影响,post请求回退时会重新提交数据请求。
4.get请求可以被缓存,post请求不会被缓存。
5.get请求会被保存在浏览器历史记录当中,post不会。get请求可以被收藏为书签,因为参数就是url中,但post不能。它的参数不在url中。
6.get请求只能进行url编码(appliacation-x-www-form-urlencoded),post请求支持多种(multipart/form-data等)。
Cookie和Session
Cookie和Session的区别(面试必备)
Http和Https
HTTP与HTTPS的区别,详细介绍
Linux
如何查看进程是否存活以及端口号
- ps:ps命令是Process Status的缩写。ps命令用来列出系统中当前运行的那些进程。
- netstat:netstat 命令用于显示网络状态
ps aux命令,通过stat列可以查看进程状态

netstat -anp命令,可以查看端口号及进程

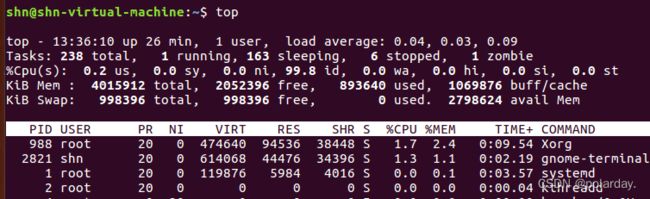
查看Cpu和内存情况
top:能够实时显示系统中Cpu、内存以及各个进程的资源占用状况
cat /proc/cpuinfo:存储Cpu信息
cat /proc/meminfo:存储内存信息
awk、sed、grep
数据库Mysql
左连接右连接
MySQL 有这一篇就够(呕心狂敲37k字,只为博君一点赞!!!)
数据结构与算法
快速排序
func sortArray(nums []int) []int {
quickSort(nums, 0, len(nums)-1)
return nums
}
func quickSort(nums []int, begin int, end int) {
if begin > end {
return
}
randIdx := begin + rand.Intn(end-begin+1)
nums[begin], nums[randIdx] = nums[randIdx], nums[begin]
key := nums[begin]
j := begin
for i := j + 1; i <= end; i++ {
if nums[i] < key {
j++
nums[j], nums[i] = nums[i], nums[j]
}
}
nums[j], nums[begin] = nums[begin], nums[j]
quickSort(nums, begin, j-1)
quickSort(nums, j+1, end)
}
堆排序
哈夫曼编码
哈夫曼编码
堆和栈的区别
(1)管理方式不同。栈由操作系统自动分配释放,无需我们手动控制;堆的申请和释放工作由程序员控制,容易产生内存泄漏;
(2)空间大小不同。每个进程拥有的栈大小要远远小于堆大小。理论上,进程可申请的堆大小为虚拟内存大小,进程栈的大小 64bits 的 Windows 默认 1MB,64bits 的 Linux 默认 10MB;
(3)生长方向不同。堆的生长方向向上,内存地址由低到高;栈的生长方向向下,内存地址由高到低。
(4)存放内容不同。栈存放的内容,函数返回地址、相关参数、局部变量和寄存器内容等。堆存放使用new创建的对象,全局变量
Go/C++
面向对象的三大特征
- 封装
封装就是把同一类事物的共性(包括属性和方法)归到同一类中,方便使用。 - 继承
就是子类继承父类的特征和行为,使得子类对象(实例)具有父类的实例域和方法,或子类从父类继承方法,使得子类具有父类相同的行为 - 多态
在继承基础上,才有多态
多态的实现的必要条件:
存在继承关系
存在方法重写
父类引用指向子类对象
方法的重载与重写
-
方法的重载:
方法名相同,而方法的参数数量不同或数量相同而类型和次序不同。 -
方法的重写:
方法的重写,不能发生在同类中,只能发生在子类中。 若子类中的方法与父类中的某一方法具有相同的方法名、返回类型和参数,则新方法将覆盖原有的方法。 -
重写与重载的区别:
重载实现于一个类中;重写实现于子类中。
测试
如果定位bug出现在前端还是后端
1.通常可以利用抓包工具来进行分析
(1)传参内容是否正确
如果传参内容不正确,定位为前端的bug。
(2)响应内容是否正确
如果响应内容不正确,为后端bug。
2.前后端bug各有什么样的特殊性质
(1)前端bug特性:界面相关,布局相关,兼容性相关,交互相关。
(2)后端bug特性:数据相关,安全性相关,逻辑性相关,性能相关。
3.定位BUG属于前端还是后端,常用的有以下2种方法:
(1)查看http请求参数和响应结果。
(2)查看后端服务log日志有无错误日志信息。
计算机组成原理
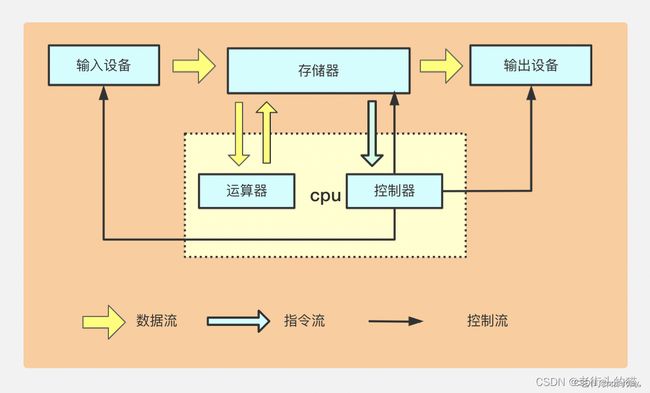
冯·诺依曼体系结构
运算器、控制器、存储器、输入设备、输出设备