python web开发入门_python大佬整理的python web开发从入门到精通学习笔记
原标题:python大佬整理的python web开发从入门到精通学习笔记
Python(发音:英[?pa?θ?n],美[?pa?θɑ:n]),是一种面向对象、直译式电脑编程语言,也是一种功能强大的通用型语言,已经具有近二十年的发展历史,成熟且稳定。它包含了一组完善而且容易理解的标准库,能够轻松完成很多常见的任务。它的语法非常简捷和清晰,与其它大多数程序设计语言不一样,它使用缩进来定义语句。
Python支持命令式程序设计、面向对象程序设计、函数式编程、面向切面编程、泛型编程多种编程范式。与Scheme、Ruby、Perl、Tcl等动态语言一样,Python具备垃圾回收功能,能够自动管理存储器使用。它经常被当作脚本语言用于处理系统管理任务和网络程序编写,然而它也非常适合完成各种高级任务。Python虚拟机本身几乎可以在所有的作业系统中运行。使用一些诸如py2exe、PyPy、PyInstaller之类的工具可以将Python源代码转换成可以脱离Python解释器运行的程序。

首先是web编程的必备知识:HTTP协议。超文本传输协议(HTTP),是一种通信协议,按照定义来直接去看容易一头雾水,但其实只需要了解:web服务器和客户端之间交流,必须要遵守统一的规矩,不然就跟你说汉语我说英文一样,互相不知对方在说什么。这个统一的规矩或者格式就是HTTP协议
而服务器和客户端之间的通信方式简而言之就是,客户端给服务器发了一个请求(request),服务器要根据这个request的内容来返回客户端要的东西(response),其他要学习的一切东西都是将这个过程变得更加细化和完备的过程。
从我们平时上网的过程来看,发生了如下的事情:
首先,我们在地址栏里输入了一个url:
它可以被解析分解为如下的部分:
https
这是我们指定的通信协议,通常有http/https。https是http协议的安全版本,是加密的。
movie.douban.com
这是服务器的主机ip地址(但是其实我们一般看见的都是域名,因为ip地址不好记,所以拿域名指代它。我们输入域名后,电脑会自动到一个叫DNS服务器的地方去查这个域名对应的ip地址)
443
这是指定的服务器端口,与host部分用冒号:分开。http默认80端口,https默认443端口,默认的端口一般不用填写
/top250
这是路径path,指定的是在这个服务器上你需要的文件存放的位置,跟电脑里文件夹的路径是一个道理
start=25&filter=
这是url里传的参数,与path用问号?分隔,它内部的每个参数之间用&符号分隔。(start=25,filter=这样的一对一对的就是“属性=参数”这样的格式,url里传的参数都是用的GET方法,之后会讲到)
嗯。。现在浏览器拿到了我输入的url,它就会解析(解析过程之后讲)我给的这个url,知道了我要拿到指定位置文件的需求。就会给服务器发一个request(是二进制字符串):
’GET /top250?start=25&filter= HTTP/1.1\r\nhost:movie.douban.com\r\n\r\n’
其实它是这样的:
GET /top250?start=25&filter= HTTP/1.1
Host: movie.douban.com
看见的这两行是request请求最基本的部分叫请求行,其实浏览器实际发送request的还有很多东西(
Connection: keep-alive
Cache-Control: max-age=0
Upgrade-Insecure-Requests: 1
......略......
)
等等等等一大堆东西,这些是头部header,不过这都是一些浏览器自身对服务器提的细枝末节的要求,我们现在没必要了解
而以上的这些请求行和头部,其实都在上边那个request二进制字符串里,在最后的那\r\n\r\n之前 。请求行和头部完了之后,会有一个\r\n\r\n,表示这里要空一行出来。之后,会再跟上一块内容,叫body。body里存的是通过POST方法提交的参数,这个之后会讲。

python学习路线分三大阶段:基础-进阶-框架-项目实战
基础第一阶段:基础Python的理解。基础第二阶段面对对象编程(注重编程能力)
基础第三阶段面向对象“设计思想”-封装-继承。基础第四阶段python高级专题。
进阶班第一阶段:linux基础。第二:python web工具。第三python部署工具。
第四关系型数据库。第五Python web框架基础原理。
框架阶段.python web开发第一阶段web.py。基础第二Django基础。
第三flask基础。第四tornado基础,
项目实战:个人博客系统-微信开发-企业OA系统=网盘系统。

以上就是request的全部内容,浏览器把这个request发给了服务器,服务器接收到request,然后拿去解析(解析过程之后讲),解析完之后按照request里的要求,拿出相应的数据,用html模板装好(静态页面直接返回指定文件就好),这一部分就会成为response的body体。response和request的结构一样,都是由 请求行/响应行 + header + 空行 + body组成的。
服务器回复的response如下:
HTTP/1.1 200 OK
这是响应行,后边还有其他一大堆东西(
Date: Sun, 12 Jun 2016 12:06:21 GMT
Content-Type: text/html; charset=utf-8
Transfer-Encoding: chunked
Connection: keep-alive
Keep-Alive: timeout=30
Vary: Accept-Encoding
X-Xss-Protection: 1; mode=block
.......略......
)
这些是resopnse的头部header,他们同样暂时不用了解,只要知道200 是状态码,OK是对于状态码的解释就行了。一般状态码的含义为:200+代表正常,300+代表正常但是需要跳转,400+500+都是出错了,具体的可以细查。
然后服务器把由响应行 + 头部header + 体body组成的response发回给客户端。客户端把接受到的response解析,拿出body体里的内容加载出来,就是我们可以看到的页面了。
以上就是整个从访问到浏览器显示结果的的整个过程的文字描述,接下来我举例分析就其中的关键步骤对应的一些代码:
代码是用python的socket模块来实现的,浏览器(客户端)和服务器之间的联系方式用语言表述如下:
步骤一:服务器会监听自己的一个端口port,并且将自己的主机ip地址和端口通过其他方式告知浏览器。(就比如我们是事先知道豆瓣电影的url的)
步骤二:浏览器知道ip和port之后,就会向这个位置发送连接请求
步骤三:服务器接收连接请求,至此两者之间的通信就已经建立,互相之间可以互相发送数据了
这是客户端:
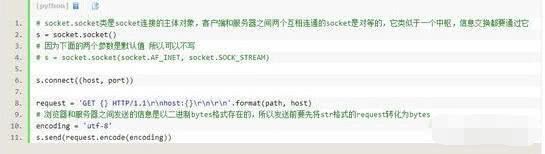
这是服务器端:

至此,关于从客户端到服务器再到客户端,我们传递参数获取页面的整个过程的基本原理已经从底层到框架完全展示了一遍,虽然例子很简单,但是核心很完整。
整个后端程序其实就是,接受从网传来的请求,提交的数据等其他一系列信息,然后在后端代码里解析,然后根据不同的需要,有的要存数据库,有的要表现出来,还有的要从数据库里拿东西 ,然后把需要表达的东西组合起来放到容器里传给模板,模板按照其语法从容器里获取对应的数据,然后表现出来。
只不过规模和复杂程度比这几个例子要大很多很多倍,但是掌握了原理,再去理解一些细节的东西,就很清楚了。

Python可以做什么?
web开发和 爬虫是比较适合 零基础的
自动化运维 运维开发 和 自动化测试 是适合 已经在做运维和测试的人员
大数据 数据分析 这方面 是很需要专业的 专业性相对而言比较强
科学计算 一般都是科研人员 在用
机器学习 和 人工智能 首先 学历 要求高 其次 高数要求高 难度很大返回搜狐,查看更多
责任编辑: