【框架源码】Spring源码解析之Bean创建源码流程

问题:Spring中是如何初始化单例bean的?
我们都知道Spring解析xml文件描述成BeanDefinition,解析BeanDefinition最后创建Bean将Bean放入单例池中,那么Spring在创建Bean的这个过程都做了什么。
Spring核心方法refresh()中最最重要的一个方法 finishBeanFactoryInitialization() 方法,该方法负责初始化所有的单例bean。
finishBeanFactoryInitialization()方法位于refresh()中第11步。

走到这一步的时候,Spring容器中所有的BeanFactory都已经实例化完成了,也就是实现BeanFactoryPostProcessor接口的 Bean 都已经初始化完成了。剩下的就是初始化singleton beans,在我们的业务bean中大多数都是单例的,finishBeanFactoryInitialization这一步就是去实例化单例的并且没有设置懒加载的Bean。
Spring会在finishBeanFactoryInitialization这个方法里面初始化所有的singleton bean。
Ok,我们先来看一下finishBeanFactoryInitialization方法内部的逻辑。这个方法的核心就在于完成BeanFactory的配置。该阶段完成了上下文的实例化,包含所有单例Bean对象已经实例化。
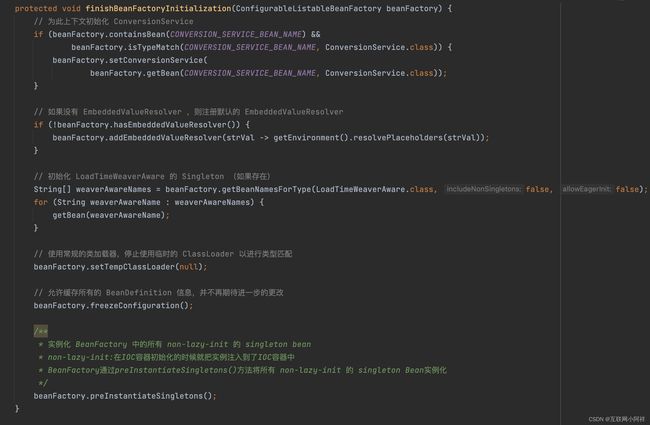
核心在于 preInstantiateSingletons() 方法,preInstantiateSingletons方法主要任务是进行初始化,在初始化前同样是一系列判断,如,是否是懒加载的,是否是一个factorybean(一个特别的bean,负责工厂创建的bean),最后调用getBean()方法。
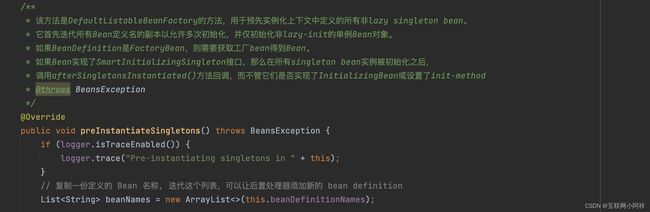
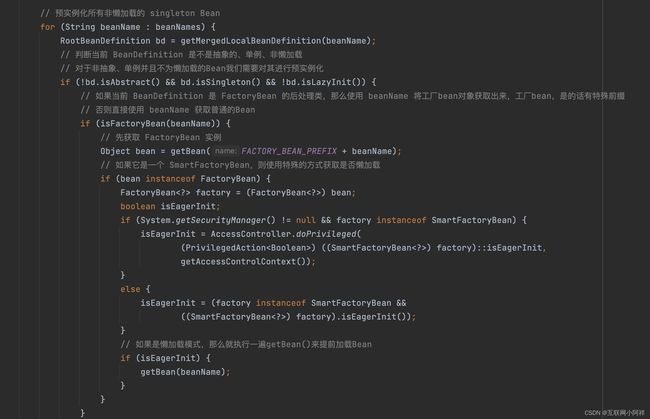
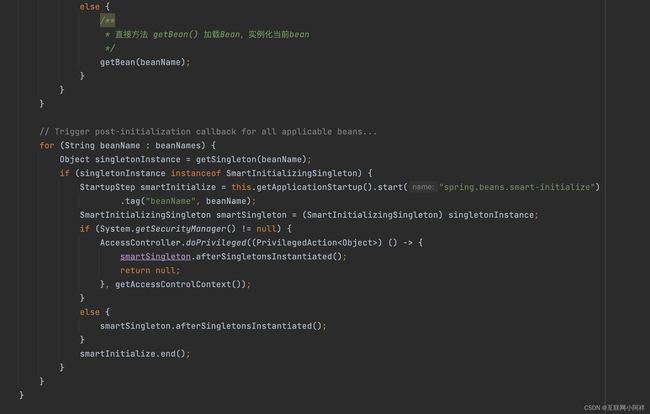
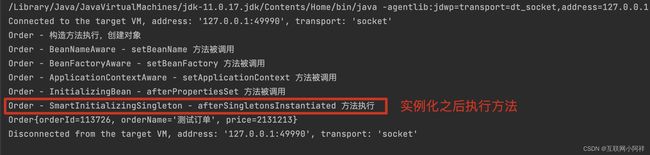
注释中提到的SmartInitializingSingleton接口,是让bean初始化后做一些操作。

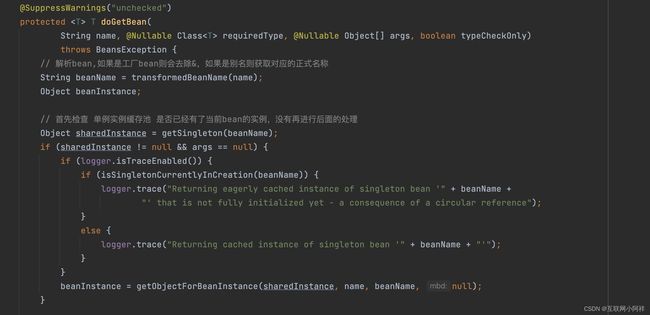
OK,那么主要的方法还是getBean()方法,getBean()方法的作用就是加载、实例化Bean。方法内部调用了doGetBean(),我们直接看**doGetBean()**方法内部。


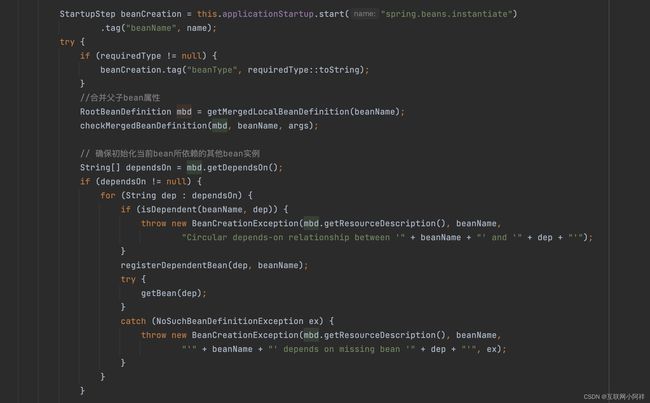
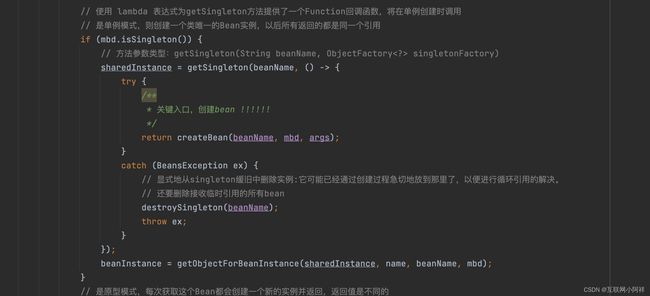
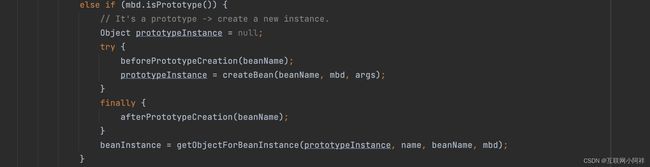
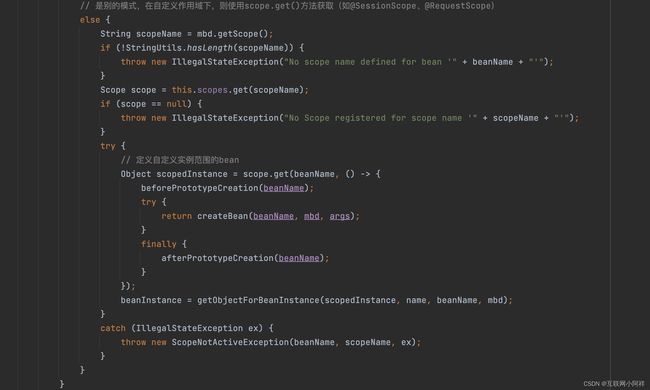
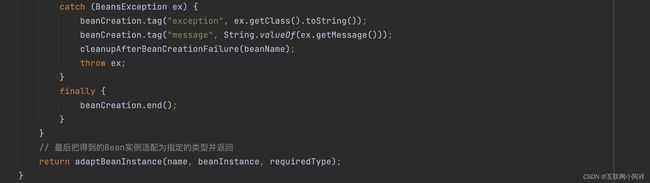
代码很多,我们主要看createBean()方法。
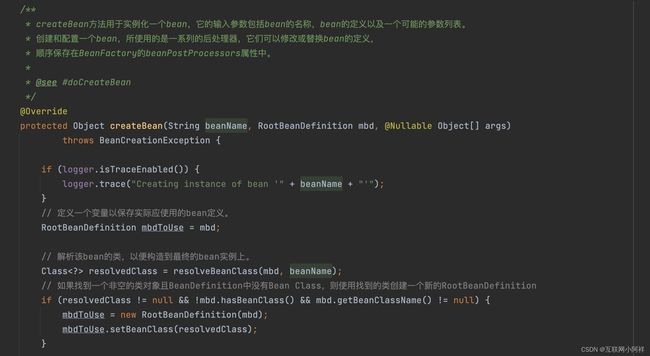
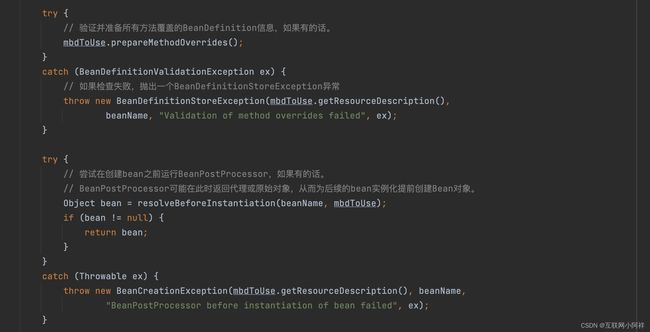
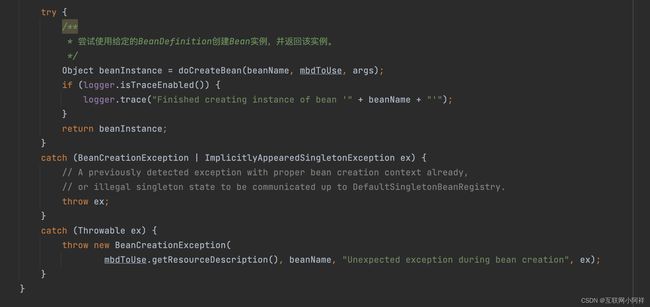
我们继续往doCreateBean 这个方法里面看。
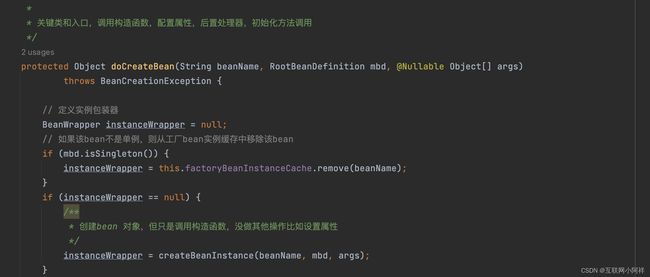
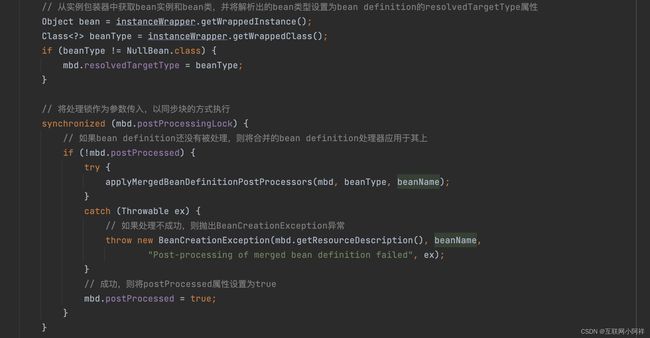
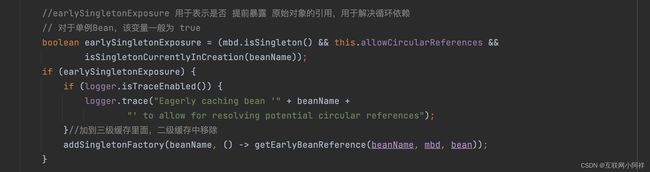
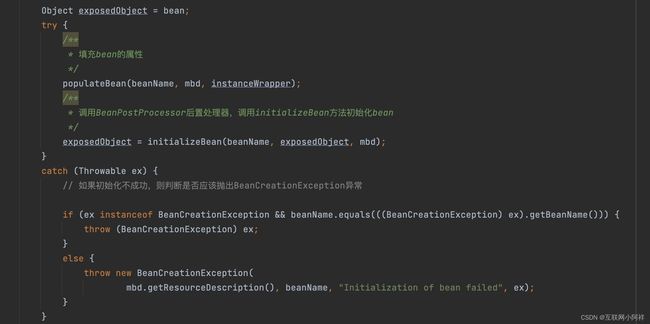
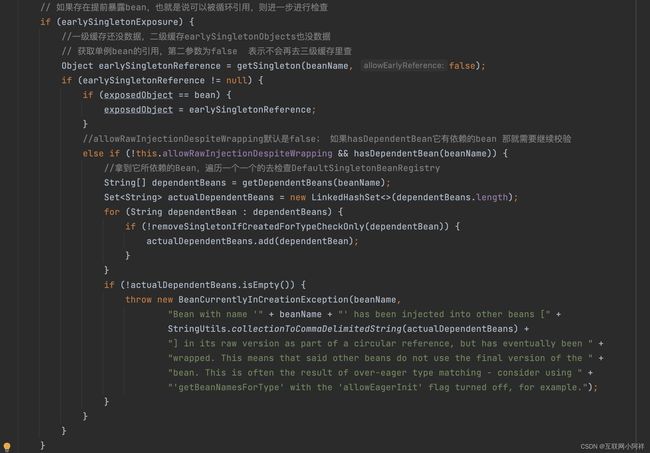

方法很多,我们主需要关注三个方法即可。
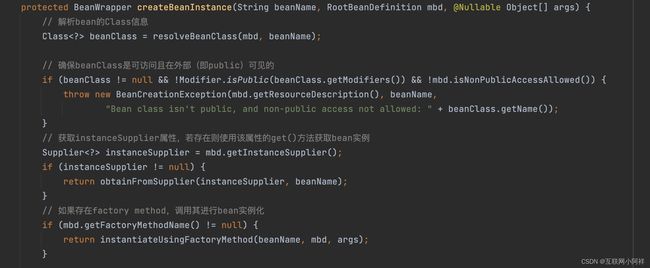
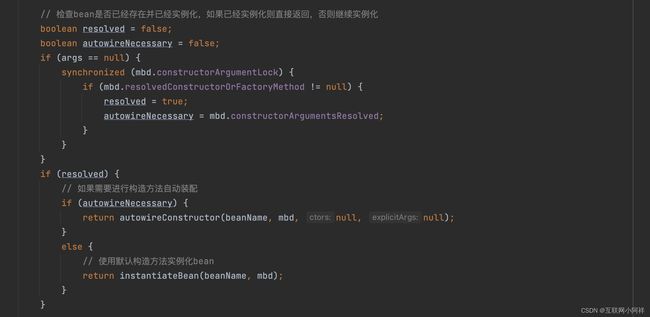
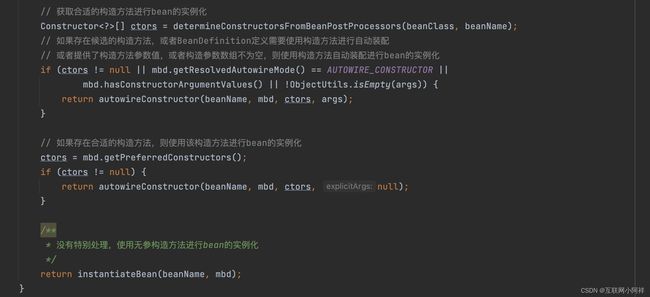
- createBeanInstance:实例化,其实也就是调用对象的构造方法实例化对象
- populateBean:填充属性,这一步主要是多bean的依赖属性进行填充
- initializeBean:调用spring xml中的init 方法。
从上面讲述的单例bean初始化步骤我们可以知道,循环依赖主要发生在第一、第二步。也就是构造器循环依赖和field循环依赖。
那么我们要解决循环引用也应该从初始化过程着手,对于单例来说,在Spring容器整个生命周期内,有且只有一个对象,所以很容易想到这个对象应该存在Cache中,Spring为了解决单例的循环依赖问题,使用了三级缓存。
什么是Spring的三级缓存?
Spring的IOC容器里面的三级缓存都是Map结构。
- 一级缓存(成熟的bean)
singletonObjects单例池 ,存放完全初始化好的 bean,从该缓存中取出的 bean 可以直接使用
- 二级缓存
earlySingletonObjects提前曝光的单例对象的cache,存放原始的 bean 对象(尚未填充属性),用于解决循环依赖
- 三级缓存
singletonFactories单例对象工厂的cache,存放 bean 工厂对象,用于解决循环依赖

OK,了解完三级缓存我们再来看下 getSingleton() 这个方法。这个方法主要是用于从单例池中获取指定名称的单例Bean实例,方法内部实现了三级缓存查找机制,通过三级查找的机制来获取指定名称的单例Bean实例对象,同时该方法会使用同步代码块保证多线程环境下的线程安全性。
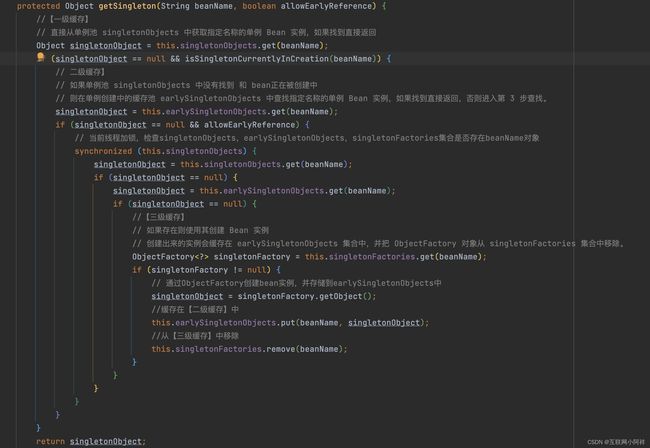
OK,那么到这里我们会有一个疑问,Spring为什么要用三级缓存来解决循环依赖的问题。
首先我们要明确一点,Spring可以解决setter的依赖注入,但是不能解决构造器的依赖注入。
假如我们现在有个A对象和B对象,A的某个field或者setter依赖了B的实例对象,同时B的某个field或者setter依赖了A的实例对象”这种循环依赖的情况。
A首先完成了初始化的第一步,并且将自己提前曝光到singletonFactories中,此时进行初始化的第二步,发现自己依赖对象B,此时就尝试去get(B),发现B还没有被create,所以走create流程,B在初始化第一步的时候发现自己依赖了对象A,于是尝试get(A),尝试一级缓存singletonObjects(肯定没有,因为A还没初始化完全),尝试二级缓存earlySingletonObjects(也没有),尝试三级缓存singletonFactories,由于A通过ObjectFactory将自己提前曝光了,所以B能够通过ObjectFactory.getObject拿到A对象(虽然A还没有初始化完全,但是总比没有好呀),B拿到A对象后顺利完成了初始化阶段1、2、3,完全初始化之后将自己放入到一级缓存singletonObjects中。
此时返回A中,A此时能拿到B的对象顺利完成自己的初始化阶段2、3,最终A也完成了初始化,进去了一级缓存singletonObjects中,而且更加幸运的是,由于B拿到了A的对象引用,所以B现在hold住的A对象完成了初始化。

知道了这个原理时候,肯定就知道为啥Spring不能解决"A的构造方法中依赖了B的实例对象,同时B的构造方法中依赖了A的实例对象"这类问题啦!因为加入singletonFactories三级缓存的前提是执行了构造器,所以构造器的循环依赖没法解决。
下面一个案例带大家体验下构造器注入和set注入的演示
编写类A类B
public class A {
private B b;
public A() {}
public B getB() {
return b;
}
public void setB(B b) {
this.b = b;
}
public void method(){
System.out.println("A方法调用");
}
}
public class B {
private A a;
public B(){}
public A getA() {
return a;
}
public void setA(A a) {
this.a = a;
}
public void method(){
System.out.println("B方法调用");
}
}
编写xml
<bean id="b" class="com.lixiang.demo.B">
<property name="a" ref="a">property>
bean>
<bean id="a" class="com.lixiang.demo.A">
<property name="b" ref="b">property>
bean>
测试
修改xml配置
<bean id="b" class="com.lixiang.demo.B">
<constructor-arg name="a" ref="a">constructor-arg>
bean>
<bean id="a" class="com.lixiang.demo.A">
<property name="b" ref="b">property>
bean>
代码调整
public class B {
private A a;
public B(A a){
this.a = a;
}
public A getA() {
return a;
}
public void setA(A a) {
this.a = a;
}
public void method(){
System.out.println("B方法调用");
}
}
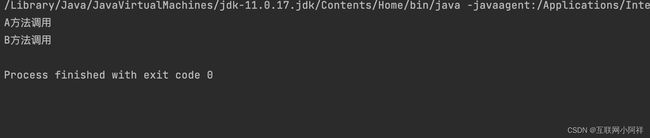
测试

可以发现用构造器注入是发生异常的。
Spring引入了“提前暴露Bean”的机制,在创建A对象时,会先创建一个A的空对象并将其添加到缓存池中。
即“提前暴露Bean”,然后继续创建B对象,将其注入A对象中。在创建B对象时,由于A对象已经在缓存池中,可以直接获取到A对象,接着将B对象注入到A对象中,完成Bean的初始化。

好的,到现在整一个Bean的创建流程,就已经完成啦。我们在看一下以下三个方法的具体实现。
首先第一个就是 createBeanInstance() 方法
然后是 populateBean() 方法
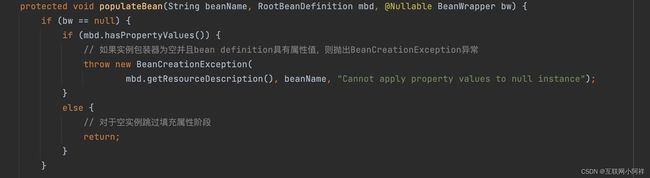
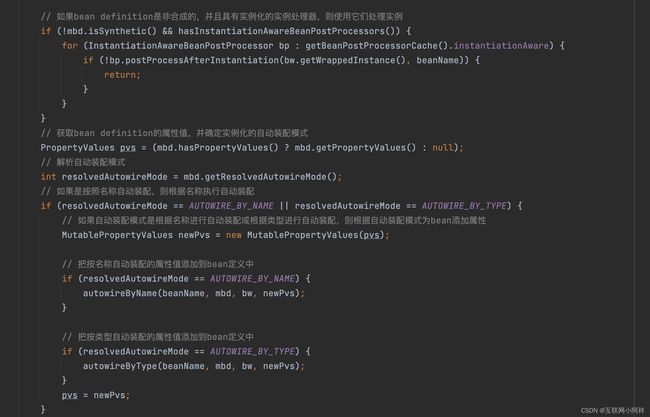
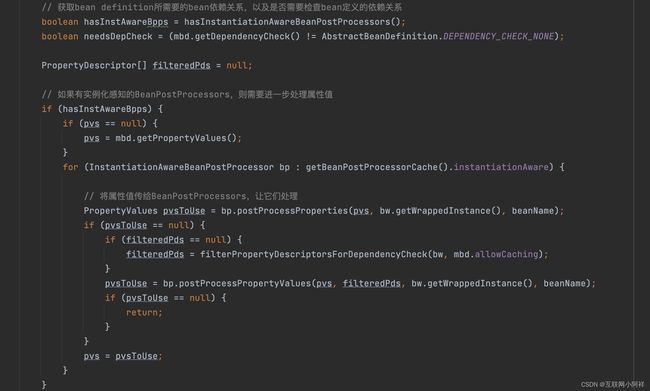
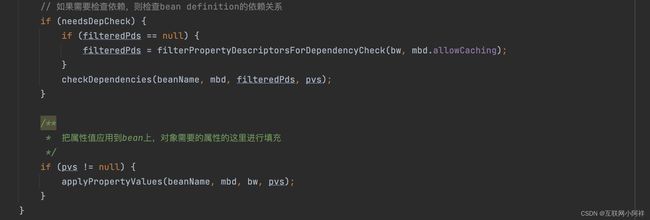
最后是 initializeBean() 方法
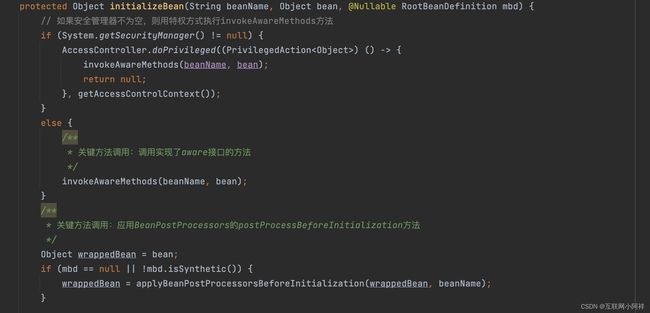
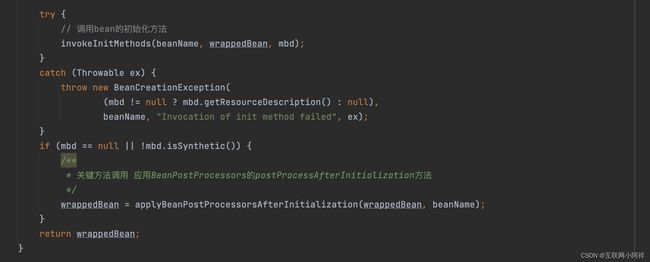
ok,到这里Spring的bean的创建过程就已经梳理完成啦。
记得点个赞+关注哦!
