MySQL-正则表达式的使用
MySQL-正则表达式的使用
正则表达式的作用是匹配文本,将一个模式与一个文本串进行比较。例如,从一个文件中提取电话号码,查找一篇文章中重复的单词、替换文章中的敏感语汇等,这些地方都可以使用正则表达式。正则表达式强大且灵活,常用于非常复杂的查询。
MySQL 中,使用 REGEXP 关键字指定正则表达式的字符匹配模式,其中where字句提供了对正则表达式的初步支持,其基本语法格式如下:
属性名 REGEXP '匹配方式'
“属性名”表示需要查询的字段名称;“匹配方式”表示以哪种方式来匹配查询。“匹配方式”中有很多的模式匹配字符,它们分别表示不同的意思。下表列出了 REGEXP 操作符中常用的匹配方式。
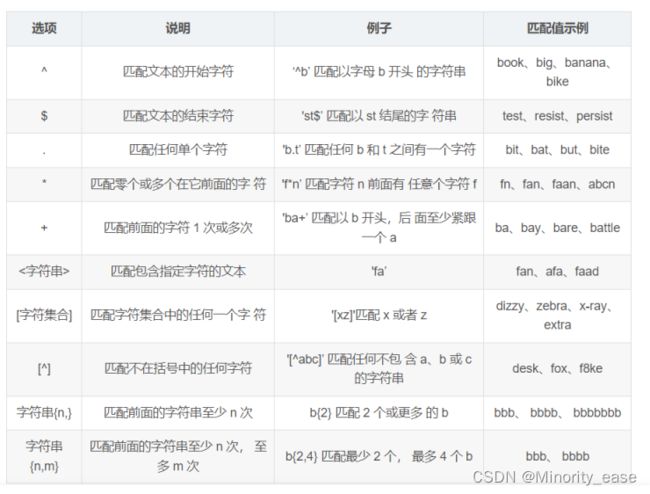
基本字符的匹配
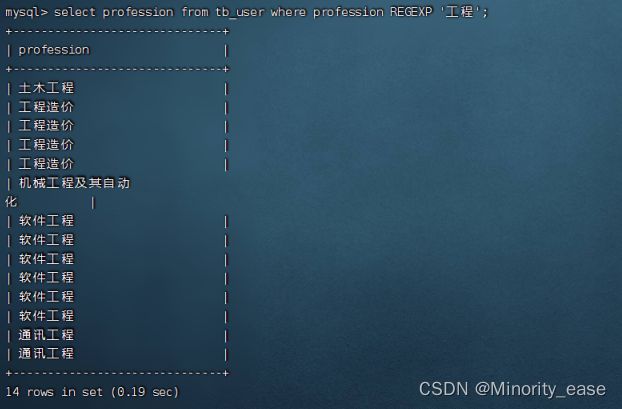
先从一个非常简单的例子看起,检索文本中包含‘工程’文本的所有行,此语句看起来与模糊匹配非常相似,仅仅是将like用REGEXP代替,那为什么有时候会要用正则表达式代替like进行匹配呢,现在先暂时按下不表,最后笔者会对此两种匹配方式做一个对比总结。
select profession from tb_user where profession REGEXP '工程';
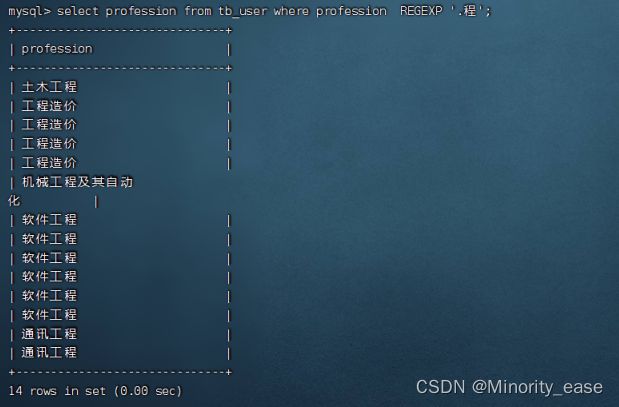
匹配单个字符
"."是正则表达式中用来匹配文本中任意一个字符的特殊字符,可以替换字母数字以及中文文本。
select profession from tb_user where profession REGEXP '.程';
进行OR匹配
当你的搜索条件是两个及以上文本串中的一个(或者为这个串,或者为其他串),那么就要用到或匹配,其中使用的字符为:“|”。
select email from tb_user where email REGEXP 'qq|sina';
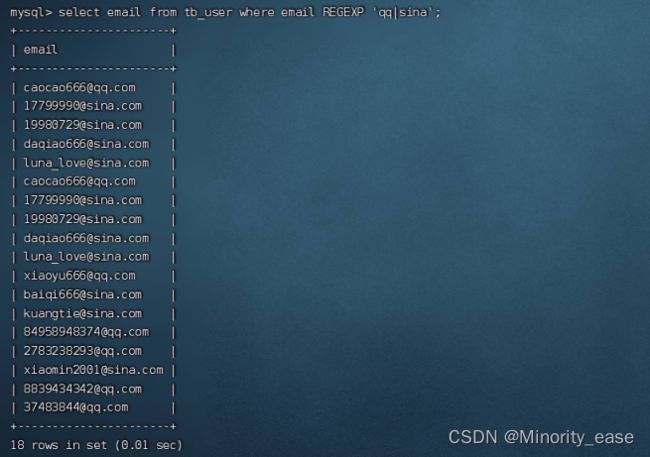
上述语句是用来匹配表中使用qq或者sina邮箱的邮箱号码。如果想匹配两个以上的or条件,也是按以上示例添加“|”符号进行匹配相应串。
如果你想匹配的仅仅是任意一个单一字符,那么就要用到“[]”符号进行实现。
select email from tb_user where email REGEXP '[abc]ao';
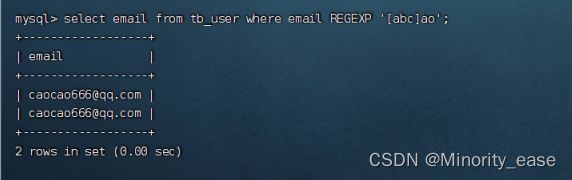
此代码作用是匹配email数据段中存在a/b/c开头并后续连接‘ao‘的邮箱号。
实际上“[]”是“|”的另一种表达形式,那什么时候要用前者替代后者呢?以下用一个实例来说明情况。
select email from tb_user where email REGEXP 'a|b|cao';
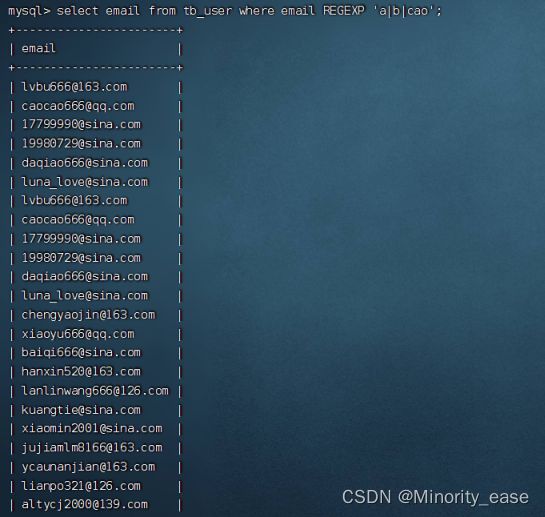
上述命令想表达出来的意思是和用“[]”时一样,但为什么得到的结果是不一样的呢? 这是因为这条语句MySQL假定你是想匹配存在“a”或“b”或“cao”的邮箱号码,因此得到的不是我们想要的结果,这时就要用“[]”将每个字符括在一个集合中,否则它将应用于这个串。
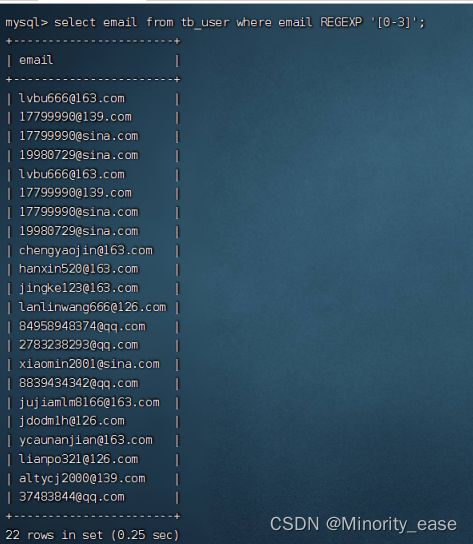
集合也可以定义用来匹配一个或多个字符例如[0-9]表示匹配任意数字,[a-Z]表示匹配任意字母字符。
select email from tb_user where email REGEXP '[0-3]';
匹配特殊字符
正则表达式由具有特定含义的特殊字符构成,例如“.”,“[]”,"|"等,那么如果想在文本中匹配这些特殊字符应该怎么实现呢?
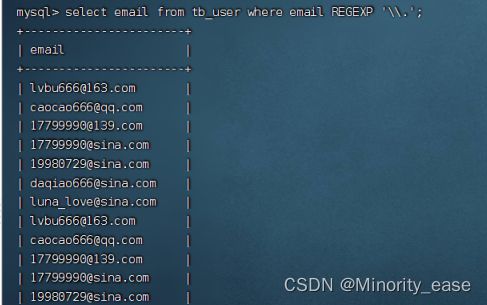
当要匹配一些特殊字符时,必须要用\\作为前导,例如\\-表示在文本段中查找-。这种处理就是所谓的转义,正则表达式中具有特殊意义的所有字符都必须以这种方式进行转义。(如果想匹配\那么就要使用”\\”进行匹配匹配)
select email from tb_user where email REGEXP '\\.';
匹配多个实例
之前使用的所有匹配模式都是匹配单次出现的情况,如果说想对匹配的数目进行更强的控制,那么就需要重复元字符来进行完成,这些字符在开头的表格中都有列出。
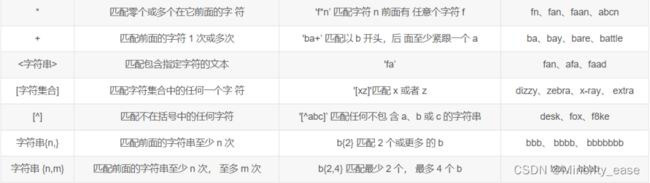
例如想要查找文本中是否存在“[666] eng”时,就可以使用重复元字符表示,下列示例中列出了三种不同的查找方法,对照上述表格即可知道相应含义,这里就不一一解释了。 不过要注意,重复元字符是用来匹配它前面出现的字符出现次数,也就是说只对其前面一个字符有效。
1:select profession from tb_user where profession REGEXP '\\[[0-9]+ eng\\]';
2:select profession from tb_user where profession REGEXP '\\[[0-9]* eng\\]';
3:select profession from tb_user where profession REGEXP '\\[[0-9]{3,} eng\\]';

定位符
如果你想匹配特定位置的文本,那么就需要使用到定位符。
^匹配文本的开始位置,$匹配文本的结尾
select profession from tb_user where profession REGEXP '^软';

^在正则表达式中有双重用途,如果在集合"[]"中使用表示否定该集合中的内容,其他情况的话就是表示定位符的作用。
正则表达式与like模糊匹配的比较
like是用来比较整个列值是否匹配,如果用like来匹配的文本在列值中出现过,但不是完整的列值形式存在,那么like将不会找到它(除非使用通配符%)。
正则表达式则是在列值内进行匹配,如果被匹配的文本在列值中出现,那么就可以找到它。
简单来说就是like必须匹配整个串内容而regexp可以匹配子串,这是非常重要的区别。