基于LinkedList高性能android列表适配器
1、前言
我们大部分的时候都是使用ArrayList作为Android适配器Adapter(无论是ListView或者RecyclerView)下的数据容器。为什么使用ArrayList呢?因为他的内部是由数组实现的,所以访问数组元素速度最快,但是如果数据变化(增加、删除、顺序变更)速度较慢,而且需要开辟连续大空间。
对应的LinkedList双向链表效果跟ArrayList相反,更新更快;查询速度更慢一些。不要求内存数据是连续的。
2、背景
目前在维护小说书架需求。这个场景下 其实 展示的书籍场景不是很频繁,但是用户点击书籍之后,会重新排序 然后进行展示出来,用户加入书架、删除书架书籍的情况还是比较多的。想做滑动速度优化。所以我感觉是不是可以优化一下LinkedList的访问速度,从而达到一种完美的方案呢?
3、解决方案
幸亏我们应用的场景是一个一块屏幕内的列表,每次获取数据的时候 也不是都从0开始获取。
我们知道一个列表(无论是RecyclerView或者ListView),获取数据的都是一个方法
@Override
public View getView(int position, View convertView, ViewGroup parent) {
T holder;
if (convertView == null) {
int viewType = getItemViewType(position);
int layoutId = getLayoutId(viewType);
convertView = LayoutInflater.from(context.getContext()).inflate(layoutId, parent, false);
holder = getViewHolder(convertView);
convertView.setTag(holder);
} else {
holder = (T) convertView.getTag();
}
holder.setViewHolderData(position, getItem(position));
return convertView;
}每一次都是从getView中获取指定的position,而这个position都是有规律的:
如果向上滑动,那么这个position值从0开始 到展示的最下面的点位。
如果向下滑动,那么这个position值从下底部开始,往上数到上点位
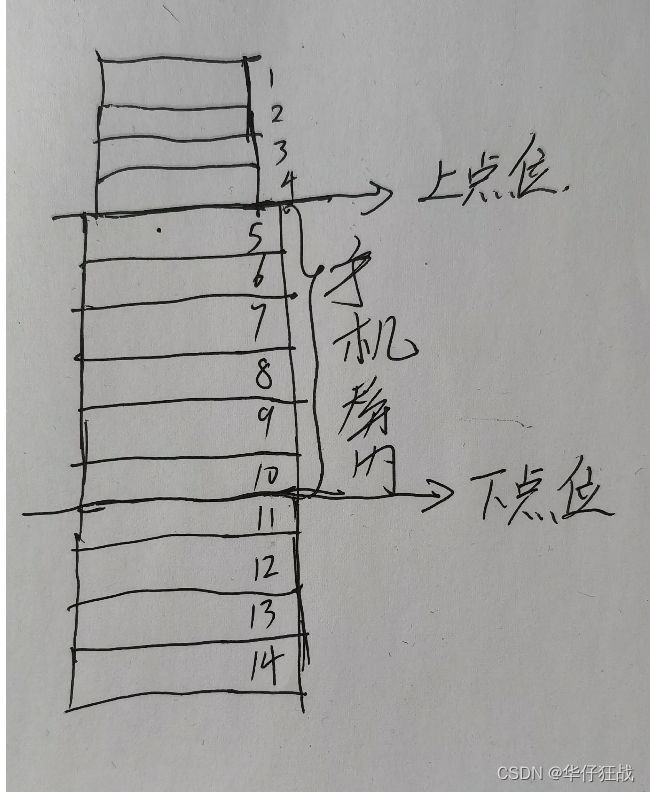
为了快速的找到我们的数据,我们利用 上点位的数据和下点位的数据。快读定位我们下一个展示的数据值
比如我们现在的下点位是10,我想向上滑动一个item,那么这个位置就是11,我们可以从下点位的node值为10,快读找到他的next的node值11,而不用从0开始数到这个位置。
向下滑动也是一样的,比如目前上点位是5,再向下滑动一个item,向拿到4的位置数据,可以从5这个node找到前驱pre值。
每次滑动的时候更新这两个位置的node 就可以快读在链表LinkedList中找到对应的值了。几乎可以达到O(0),而不是O(n)的目的。
4、实施方案
4.1、适配器获取数据改造-getItem()
@Override
public LinkedBean getItem(int position) {
if (isOptim) {
if (realList != null) {
// 如果有notify刷新的话 那么重新去构建数据
if (isChange) {
lastPositon = -1;
}
if (listView != null) {
// 获取当前最上面的那个view 是位置号,
int currentFirstPositon = listView.getFirstVisiblePosition();
// 但是listview有一个问题 getFirstVisiblePosition方法获取的是展示的第一个完整的位置;
// 如果出现一部分 就出现了位置不准问题 因此增加一个兼容
if (position < currentFirstPositon) {
currentFirstPositon = position;
}
// 如果是刷新notifydata 或者首次进入 那么需要重头开始查询位置
if (lastPositon == currentFirstPositon || lastPositon == -1) {
isChange = false;
lastPositon = currentFirstPositon;
if (isChange || lastNode == null) {
lastNode = realList.getNode(position);
return lastNode.item;
} else {
// 如果没有滑动 那么通过headBeanNode这个基准 就不变
// lastFirstPositon和headBeanNode是一堆映射 ;通过diff去链表上查询
int diff = position - lastPositon;
MyLinkedList.Node item = realList.getNode(lastNode, diff);
if (item != null) {
return item.item;
}
}
} else {
// 如果如果滑动了 那么需要更新基准的lastFirstPositon和headBeanNode基准
int diff1 = currentFirstPositon - lastPositon;
MyLinkedList.Node diffItem = realList.getNode(lastNode, diff1);
lastNode = diffItem;
lastPositon = currentFirstPositon;
// 基准更新完了 重复上面的相同的方法 通过diff去查找
int diff2 = position - lastPositon;
MyLinkedList.Node item = realList.getNode(lastNode, diff2);
if (item != null) {
return item.item;
}
}
}
LinkedBean bean = super.getItem(position);
return bean;
} else {
LinkedBean bean = super.getItem(position);
return bean;
}
} else {
LinkedBean bean = super.getItem(position);
return bean;
}
} 我们的方案就是记住上次展示的position和对应的Node数据;当用户滑动的时候 获取新的postion的时候,我们通过链表去找当前的node向前或者向后diff个节点值,就是我们想要的node数据了。
4.2、改造LinkedList
public Node getNode(int index){
checkElementIndex(index);
return node(index);
}
public Node getNode(Node node,int index){
// checkElementIndex(index);
return node(node,index);
}
/**
* Returns the (non-null) Node at the specified element index.
*/
Node node(Node node,int diff) {
// assert isElementIndex(index);
if (diff > 0) {
Node x = node;
for (int i = 0; i < diff; i++) {
if (x != null) {
x = x.next;
}
}
return x;
} else {
diff = -diff;
Node x = node;
for (int i = 0; i < diff; i++) {
if (x != null) {
x = x.prev;
}
}
return x;
}
} 由于LinkedList里面没有我们想要的这种方法getNode的方法;
原版的LinkedList只能拿到Node里面的值,但是我们想获取这个Node,所以只能自己重写LinkedList。拷贝一份,然后添加这两个方法就可以了
5、性能对比
5.1、获取数据
每次获取数据的时间进行对比:我们使用的是累计时间处于请求次数,求取的平均时间。
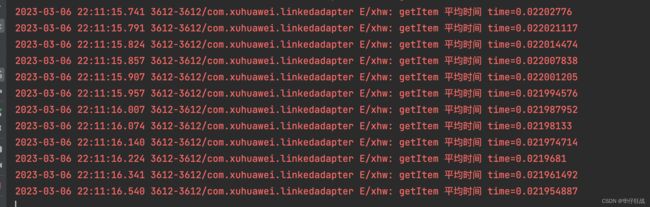
5.1.1、优化前的时间:
滑动到了第3323条数据的时候情况;达到了0.02195毫秒;随着数据的增大,每次获取的时间会越来越长!
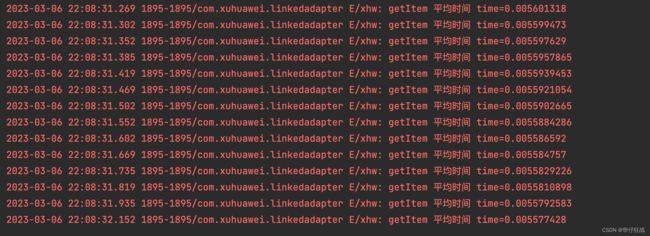
5.1.2、优化后的时间:
每一次的时间差不多都在0.0055毫秒左右
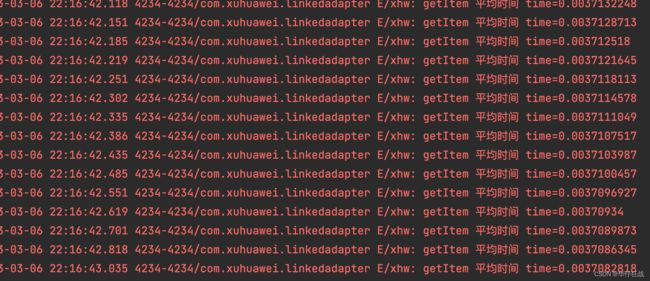
5.1.3、如果使用ArrayList的话
耗费的时间 0.0037毫秒,数据阅读,时间趋近于0 ,这里是滑动到10515条数据
5.2、修改时间
LinkedList:删除了25400次,平均时间0.00429毫秒左右

ArrayList:删除了25400次,平均耗时0.22728346号码

差距真的很明显啊!
删除的速度LinkedList是ArrayList的52.9倍!
读取的速度LinkedList是ArrayList的0.672倍! 但是这个意义不大 每次读取的速度差不多为0.0055毫秒 已经很短了!
附上源码地址:
https://download.csdn.net/download/huazai30000/87541606