pandas中分组聚合groupby()
groupby分组聚合
df.groupby(属性)[计算属性].mean().reset_index(drop=False)
- 属性可以是多个 需要列表格式[]
- 计算属性指要计算的维度 也可以多个
- mean() 计算公式 count sum 等都可以
- reset_index 可以将数据还原回数据框
例子:
import pandas as pd
#创建一个数据集
data = {'姓名': ['Tom', 'Jack', 'Steve', 'Ricky', 'Sam', 'Mia', 'Leo', 'Emily', 'Sophia', 'Oliver'],
'性别': ['M', 'M', 'M', 'M', 'M', 'F', 'M', 'F', 'F', 'M'],
'年龄': [25, 30, 18, 22, 35, 28, 40, 27, 29, 32],
'城市': ['New York', 'London', 'Paris', 'London', 'Paris', 'New York', 'Paris', 'New York', 'London', 'New York'],
'薪水': [5000, 7000, 3000, 4000, 8000, 6000, 9000, 5500, 6500, 7500]}
df = pd.DataFrame(data)
输出结果:

# 按照Gender列进行分组,并计算平均年龄
df.groupby('姓名')['年龄'].mean()
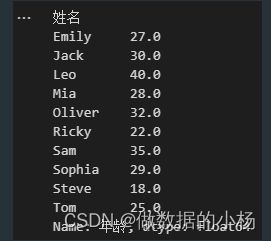
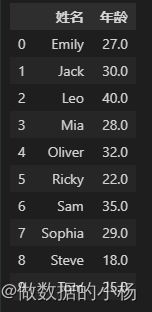
#在后面加一个reset_index()进行重置索引 美化显示
df.groupby('姓名')['年龄'].mean()
#可以分组多个项目 以列表形式,查看每个城市不同性别的平均年龄
df.groupby(['城市','性别'])['年龄'].mean().reset_index()

grpupby可以和agg apply 传入函数联用 lambda可以自定义公式函数类似 def
- apply一般和lambda合用 apply可以传入函数 数组 字典 索引
- agg agg和apply相同 对于聚合应用更灵活
- map map也是传入函数但是只适合单列计算 不能聚合 以传入函数 数组 字典 索引
例:
#年龄差
df.groupby(['城市','性别'])['年龄'].apply(lambda x: x.max()-x.min()).reset_index()

#年龄差
df.groupby(['城市','性别'])['年龄'].agg(['count','max','min'])#.reset_index()
