AICG - Stable Diffusion 学习思考踩坑实录
学习路径
- 淘宝拼多多找教程就没必要了,我踩过坑,还跟店主纠缠过,付了钱,不过都退了,淘宝平台介入,啥都能解决,现在卖得都是搬运的 B 站里面的大佬视频,我目前正在不断关注 B 站大佬的各种课程,探索更深入的认识和了解
值的概念
在Stable Diffusion中,有很多要设置的参数,这些参数起到的作用非常重要,直接决定了出图的各种样子和质量,经过实践,我大概搞明白他们遵循的规律,因为程序员是要与AI对话的,所以所谓的指标,应该就是让AI放开在机的意思,就如踩油门一样,所以,所有的数字越大,AI越放飞自己,越小,AI就越收敛。
web-ui 控制台显存满了
- 重启SD
- 点中断次数多了,显存就容易崩
几个比较深入而系统的B站博主,这个博主值得跟呀,已经开始出进阶课程
靠谱的轩轩博客-靠谱的轩轩专栏文章-文集-哔哩哔哩视频
云端部署
- 昨天 Nenly 同学推荐的 阿里云部署教程 很好,程序员比较喜欢阿里云,但是阿里云有坑,目前正在提工单给阿里云售后,学教程最麻烦的也是对方教的时候没事,你搞的时候莫名报错
- 阿里云这个大家坚决不要入坑,扣钱太厉害,还很模糊,建议后来者不要入坑
- 这个应该是老问题,就是不能离线下载,另外就是必须手动上传一个模型后,再去打开,周六再给别人讲时重新给验证一遍过程
- 阿里云这个等待程序员们升级镜像吧,一堆问题,面部修复不能用,outputs 文件夹不存图,还卡死,卡死必须刷新,体验感很差,后面看看下面两个吧。
- 阿里云售后给了一个新的镜像,新镜像的确修复了一些问题:http://registry.cn-hangzhou.aliyuncs.com/serverlessdevshanxie/sd-auto-nas:v3,还能写进去 outputs 了,给的是杭州的,如果需要北京,直接将 hangzhou 改为 beijing 即可
- 另外还有秋叶推荐的 AutoGL,这个要先充 50 元,今晚试下
- 还有就是轩轩推荐的 windows 远程方式,直接可以用秋叶安装包,还未来得及看具体操作;
- 青椒云目前30一天,A4000 16G,速度的确很可以,感觉和轩轩用的4090的生成图速度差不多,很好用,如果有想训练lora的,可以临时租赁搞来用,windows系统,自带SD,但我还是直接用本地的stable diffusion,我本地的sd以后直接做成百度云同步,这样未来再使用青椒云时就可以类似docker的,完全镜像拷贝过去了
画手窍门
- B站闹闹不闹刚出的教程几乎涵盖了各种绘制手的方法,建议多看几遍,里面有个新概念,我还没来得及看,叫LyCORIS C站上也有很多这个文件,估计是个好东西
- 另外大模型画脚的能力很差,昨天在 C 站找到了一个不是太 NSFW 的 Lora,要开 anything,然后搜索feet,效果今天会尝试一下
- 昨天采用了 PS 的方式直接把脚 PS 上去,然后采用 depth 方式,图生图依然画不出来脚,说明大模型里面没有脚的概念是画不出来的,所以找到合适的 Lora 非常重要

C 站如何开通 Everything 过滤,开通这个就会出现很多 NSFW的模型切勿上班时间
- 画手库最新作者搞了个 900 个,大家记得在 C 站下载,自带的好像才 20 个,具体我还没试,等待今晚实践一下
自带脚本
- xyz可以对不同的提示词权重等各类自带的参数进行罗列比对,生成比对图,这个在找文生图理想图时特别方便,不用自己一张一次的生成后再确认
- 提示词矩阵(prompt metrics)非常的有用,在想测试多个提示词效果时,这个可以非常方便的展示给你不同提示词带来的效果,很实用的功能;
- 从文本导入就是提示词和参数这块被文本格式化了,类似于 shell 脚本的方式,--key=value 的方式来把多个 prompt 搞进去,同时生成多张图,来比对多个 prompt 的出图效果,也非常有用
- xyz plot 这个生成图标真得非常方便,在同一个种子的情况下,图片生成的速度也很快,可以一下子看到所有重绘程度下的图像,然后根据自己的需要进行定向选择,不用老是抽卡,而且很容易定位到重绘程度的关键点,这里解决一个坑
- xyz prompt s/r 这个并不想B站课程说得替换值有个key,没有key,替换值的第一个值跟输入框中被替换的变量是相同的,例如
- xyz prompt s/r 这个并不想B站课程说得替换值有个key,没有key,替换值的第一个值跟输入框中被替换的变量是相同的,例如
文生图
- 文生图的意义就是为了给图生图做准备的,所以一开始不能设置太大,只是为了看个样子,真正要挖细节时,再开始搞成图生图
- lora 在文生图的意义在于,将大模型的人物或者服饰,先变成需要的样子,然后在图生图中微调,通过对lora和重绘的设置将样貌和服饰一点点向着自己需要的方向发展.
- 昨天又花费大半夜学习 posex做文生图,搞了一会才知道那几个点代表着脖子根,鼻子头,两只眼睛,两只耳朵,两只耳朵我一度认为是头发,另外是双肩点,手肘点,手腕点,屁股坐点,膝盖点,脚腕点,完全遵守透视图原理,差一点点都不行,例如你两只耳朵距离眼睛太远,就会出现双头,鼻子不在两眼之间,就会发生旋转,躺姿最难画,你理解的和 AI 理解的,不再一个层面,AI 有很多可能性,所以要配合 prompt 进行调节,这个最好自己先找个图,然后标好点,照着在 posex 中调节,不然复杂动作很难搞出来,同时模型有时并不支持你的动作,例如左手放在胸口,左肘抬起,就不好弄出来
- C站的Lora和模型的确突破了我的想象力,好的坏的都有,什么词都可以搜,各种Lora组合能把一个人的样子和动作玩出花,只要你能想象到;
- 与TG群里面的沟通发现,显存越大速度并不一定越快,只是出图的质量可以拉高,拼多多二手魔改22G特斯拉矿卡才600-1000,很值得后期买来跑高清图。
- Additional Network 多 Lora UI 化配置,lora 的目录要放在extensions\sd-webui-additional-networks\models\lora目录下,迹寒 作者,想到将 SD lorg 目录直接发送快捷方式到xtensions\sd-webui-additional-networks\models下,的确挺方便
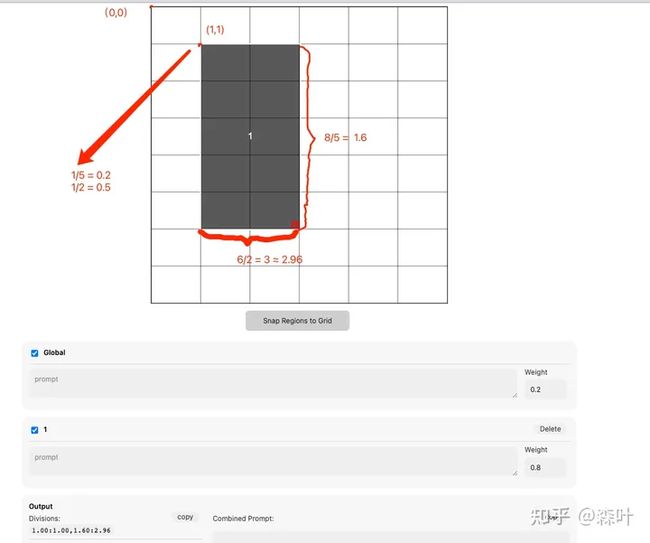
- latent couple 分割区域只能,参考知乎作者:毁图师:嘴里塞饭型Stable Diffusion插件Composable Lora+Latene Couple(长图神器),该作者又找到了https://github.com/CodeZombie/latentcoupleregionmapper,里面给了一个工具:Latent Couple Region Mapper, 我大概猜出计算方式,B站这个视频是错的,纯属误导:https://www.bilibili.com/video/BV1j24y1g749,要避坑
- 计算的是宽高分块,占行总和:占列总和,值是总行/列数除以占比行列数,例如总行是8,占比行是3,总列是6,占比列是3,那就是8/3:6/2 = 2.6:2,位置应该算法更奇葩,好像是定点为为原点,假如还是8行6列,如果左上角为原点(0,0)那么坐标为(1,1)的话,色块宽高为2:5,那么x位置为1/5,y位置为1/2,这是一种信息压缩,否则无法用2位数来定义,固位置等于0.2:0.5 = 2:5,具体还没尝试,但是这个算法应该对的上给的工具,权重据说是提示词的强度。按照这个算法,这个latent couple做得还挺灵活的
图生图
- 图生图的意义比文生图的意义要大的多,通过不断调整prompt和参数将一张图,向着自己要求的方向绘制,同时还可以借助姿势来帮助AI逐渐调整姿势,这个过程需要反复,通过调整重绘幅度提高AI的想象力,才能实现自己的目标
- 重绘值:例如换衣服或者增减衣服,如果选择重绘在0.7以下,AI基本不敢有大动作联想,而达到0.7时,即意味着告诉AI它可以重绘70%的部分,这样AI就可以绽放想象力,所以重绘的概念大家就会很容易理解了,重绘值越低,图片变化幅度越低,如果是0,则不会做任何改变;
- 对于衣服的处理,AI对黑色分辨率不高,即使让AI发挥想象力,AI对黑色仍然处理不太好,我想了个点子,就是将所有的服饰中的黑色全部搞成白色,这样AI就很容易识别出来。
- 另外就是透明的处理,对衣服,尤其是汉服的处理,可以让其透明,透明程度,可以让AI一点点处理,同时提高重绘程度,来达到透明质地的效果。
- lora 在图片重绘时的作用要大些,尤其用lora做局部重绘,效果比较好,我本来想找一下脚的lora,结果训练的人很少,且角度也很少,所以,目前AI虽然能把手画好了,但是脚画起来真是让人痛苦不堪,希望未来有大佬补足这一块。
- 局部重绘,已经被融入PS了,也不知道PS怎么搞成图层的,不过这个创意很好,stable diffusion就是单张图片,之前我就在想,如果stable diffusion能做成图层,每渲染一层都进行模式叠加,那就强无敌了,也不知道底层AI是不是这样做的,但是专业的PS貌似已经解读出来了,我详细你不久的未来就会有大牛会搞出来图层的概念来
- posex 无法画手,而且四肢的对应比较简单,不知道未来火柴人能不能做得更丰富些,openpose无法识别三维世界,虽然posex能输出三维立体的pose,但是AI不理解呀,它没有分层的概念后,还是靠抽象层去猜,一个抬起的手是在前还是在后,AI好像分不清,不知道我们的打开方式是不是不对,后期继续深入,看看别人怎么解决的
- 新版本的controlnet的姿势绘画达到脸部,手指的精准控制,posex插件已经过时了,直接使用poseeditor即可编辑
- lora权重插件还没有研究,但是自己手写lora进行配置,的确多个lora可以组合效果,通过调节它们参数权重,可以将不同的lora风格加入到重绘当中,目前窍门还没有找到,只能下试,但目前来看,可以理解为层的概念,把最核心的大细节加大权重,小细节都比大lora小,就能实现主体风格不变,并且可以一直加细节
- 最终需要微调的图,一定要记得固定住seed,不然AI无法把控在原来的已经形成的模型上,继续追加细节
- AI 能听懂你的修图要求,这个之前没提过修图要求,只是让AI设计图,从无到有,实际上也可以从有到无,只要你提的要求符合模型中的词汇即可,这个还是要对模型怎么训练的,LLM的词如何转化AI能识别的意思,尤其是LLM的词有哪些可用,要了解一下
- 图生图今天又学到了controlnet的depth的方式,之前用了posex来绘制了模型图,这个看起来能处理景深动作,不知道能不能与openpose在多通道中进行组合,这个等显卡到了,再测试
- 答案是完全可以,多通道只要启用,就可以同时起作用
- 今天B站Nenly同学同学出了Controlnet新教程,不过也只是其他教程的拼凑起来的,没有太多新亮点,但对于新手来说,还是值得看看的,讲得挺细,Nenly讲得阿里云服务器部署,还没来得及搞,后台有空部署一下,现在有两个服务器平台可供选择,后期要分析两者那个比较便宜
- 绘图:就是局部重绘的前奏,就是局部重绘,但是问题也会对整张图造成影响,但是蒙版区域的修复幅度更大些,而非蒙版地区的重绘幅度会小些
- 采用局部重绘(上传蒙版)的功能可以做到只改背景,而不重绘任何主体部分,所以该功能已被局部重绘(上传蒙版)取代
- 下个探索方向,多 lora 在不同区域的渲染,lora 分层控制的深入学习
- lora 分层渲染,不是一幅图多风格渲染,而是某一风格的定向加强,例如衣服,身体,面部等几个点,多区域不同风格,理论上局部重绘解决问题的点,例如小柔的脸,绫波丽的服装,就比以前控制起来会好很多,一会试下;
身体
BODY:1,1,1,1,1,1,1,1,0,0,0,1,1,1,1,1,1
BODY0.5:1,1,1,1,1,1,0.2,1,0.2,0,0,0.8,1,1,1,1,1
脸部(脸型、发型、眼型、瞳色等)
FACE:1,0,0,0,0,0,0,0,1,1,1,0,0,0,0,0,0
FACE0.5:1,0,0,0,0,0,0,0,0.8,1,1,0.2,0,0,0,0,0
FACE0.2:1,0,0,0,0,0,0,0,0.2,0.6,0.8,0.2,0,0,0,0,0
修手专用
HAND:1,0,1,1,0.2,0,0,0,0,0,0,0,0,0,0,0,0
服装(搭配tag使用)
CLOTHING:1,1,1,1,1,0,0.2,0,0.8,1,1,0.2,0,0,0,0,0
动作(搭配tag使用)
POSE:1,0,0,0,0,0,0.2,1,1,1,0,0,0,0,0,0,0
上色风格(搭配tag使用)
PALETTE:1,0,0,0,0,0,0,0,0,0,0,0.8,1,1,1,1,1
角色(去风格化)
KEEPCHAR:1,1,1,1,1,0,0,0,1,1,1,1,1,1,1,0,0
背景(去风格化)
KEEPBG:1,1,1,1,1,1,0.2,1,0.2,0,0,0.8,1,1,1,0,0
减弱过拟合(等同于OUTALL)
REDUCEFIT:1,0,0,0,0,0,0,0,1,1,1,1,1,1,1,1,115. 另外一张图不同部位使用不同 lora 其中有一个最简单的教程是 Additional networks+controlnet 结合来处理的,其次就是 latent couple 和 composable lora 下面是附件网络的处理教程,回头补一下 latent couple 的经验
https://www.bilibili.com/video/BV1q84y1g7VX (additional network)
https://www.bilibili.com/video/BV1js4y1E7FS (latent couple)
放大注意事项
- 图生图直接设置 768 或者1024 以上的图,stable diffusion 就会开始出现畸形,所以锁定在 1024 以下出图来保证图的不出现畸形,图细节 OK 之后,再选择放大
- 高清修复R-ESRGEN++算法可以重绘很多细节,将脸部和身体不足之处进行等比放大,所以,这个是最好的方式;
- upscale 插件就是个放大工具,不具备修复能力,原图进行放大,如果图生成的非常好了,可以用该方式进行放大
局部重绘
- 更具细节的lora,对局部优化有质的提升,AI可以通过对整体图片的识别,这是大模型起到的作用,然后分析你要重绘的局部,思考如何将周边的图像融合进来,以达到更好的无缝衔接效果,这个过程需要你对lora参数进行调整,以及给AI重绘的幅度,两者结合就能很好的让AI知道重绘的点在哪里,然后经过多次随机和prompt的组合调整,就能弄出来符合你预想的图像
- 于是商业价值就出来了,谁掌握了大量显卡,快速地给一堆人搞一堆lora,那么这个人以后就可以拿自己的lora搞事情了,甚至未来元宇宙,虚拟世界,都可以拿去用,这是服务于C端客户,同样B端客户的培训和指导,也是商机。
- 局部重绘可以试试 inpaint 插件,今天可以学习一下,另外可以使用 photoshop 来将自己已经觉得不错的地方抹除掉,印章功能更快,用 photoshop 先打补丁,打完补丁,再让 AI 处理接缝不和谐的地方进行重绘,比如拼接胳膊,膝盖等部位,皮肤颜色过渡不均匀,AI 应该可以做的更好;
- 通过靠谱的轩轩的课程讲解,仅模版,并且提高宽高比时就可以避免爆内存,另外 512 的基础上如果出现古神图像之后,则调整仅蒙版模式的边缘预留像素的大小,可以降低蒙版内的密度
- 潜变量噪声(理解为初始噪点)+重绘幅度(幅度可以理解为绘制进度),通过 XYZ 脚本的方式可以看到不同重绘幅度的发生过程,这样对于局部重绘的理解非常友好;
- 局部重绘(手涂模版)根据画笔的细腻情况和颜色选择,可以先手绘出来细节,然后不同颜色你用不同的提示词告诉计算机,计算机就会按照你给的草图,绘制局部的细节,这样我们就可以用不同颜色绘制不同层级的结构,类似与 PS 构图法方式,层层叠加上,就进行了重绘
- 局部重绘(上传蒙版)则是给专业设计师,可以使用PS 中的磁性套索来精确选择模板,可以实现完美换衣的方式,这样结合衣服 LORA,就可以将衣服穿在模型模特身上,局部重绘白色的地方是蒙版,黑色的不分不是蒙版,跟局部重绘是反过来的
- 批量处理,当我有 100 件衣服的时候,如何节省大量的人工处理?
视频重绘
- 视频重绘的原理跟局部重绘的原理一致,差异点应该就像 After Effect 有图片批处理方式,例如局部重绘蒙版可以一次性追加到所有图片,如果人物动作幅度不大,AI 对蒙版区域的要求没那么严格,接下来的事情就是烧显卡,不过也比 3D 重新渲染速度要快?
- 这个已找到有个 movtomov 的插件,这个插件不能进行局部重绘,TG群传播的重绘视频都是用多帧渲染来做的,据说一张图要10分钟,而且显存还得12G,但极客魔法学院并没有说必须12G显存,具体还没来得及看,后期亲自上手后再给结论
- multi frame render enhanced-img2img,名字竟然不一样,粘贴过来
Stable Diffusion 商业化思考
- 文生图可以提高你的想象力,将想象力的成本降到最低
- 然后就是图生图,新设计者可以很快得到原公司设计风格的预览,很多大设计公司都是有自己的设计风格,储备了大量的产品,新进去的设计者要熟悉这种风格,并在这个基础上进行迭代,借助已经训练好的 Lora 可以事半功倍;
- 设计公司训练好大模型,每个项目组再训练自己的lora,这样整个公司的风格整体划一,新的设计者进去后,就可以快速适应,只需要用prompt进行文生图,一天时间,新人就能很好的适应新公司的设计理念,且有很多东西可以直接拿来用,节省的成本可想而知;
- 今天已经在一些群里看有人提供机器训练,并表示要共享Lora版权,说明这个方向已经有人开始在探索了,艺术设计这块最后还是会回到知识产权上面来
Stable Diffusion 对个人影响
- 最近潜意识也开始运用扩散方式来渲染图像,它好像也学到新东西,看来 SD 团队对人脑是有了解的,以前不太清晰的画面,大脑通过这种逐步渲染的方式,可以原来越清楚,其实人真的是一个 AI,只是忘了自己的曾经,被统治的时间太长都失去了原有功能