简单介绍一个编译器的结构(上)
文章目录
-
- 一、语言处理器
- 二、编译器的结构
- 三、词法分析
- 四、语法分析
- 五、语义分析
- 六、中间代码生成
- 编译器后端
《编译器结构介绍(上)》主要简单介绍编译器前端所用技术和知识,内容包括源码到中间代码生成这一过程。
《编译器结构介绍(下)》主要简单介绍编译器后端所用技术和知识,内容则会比较多,包括中间代码优化到可执行文件生成这一过程。
一、语言处理器
计算机很笨,只能认识0和1,而人呢,脑子的存储能力又非常有限,很难记住大量无规律的东西。所以人只能通过高级语言或者中低级语言,再或者是汇编语言去永久记忆一些自己的逻辑想法,无法掌握大量、繁杂的机器码;计算机又只认识机器码,而不能辨认其他语言。人若想操纵计算机,就必须有一个第三者的存在,这个第三者就是语言处理器。下图是语言处理器的结构:

源程序: 即源语言所写程序,也就是我们平时用高级语言写的代码。
预处理器: 源程序需要经过预处理操作,这个过程的作用主要有两个,都是在程序编译之前完成的。
- 一个源程序可能会被分割成很多个模块,并存放于独立的文件中,这时候就需要预处理器把存储在不同文件中的源程序聚合在一起。
- 学过C的都知道宏定义,预处理器要把被称为宏的缩写语句转换为原始语句。(C++中的const常量好像也是在这一步转换的,先记下来,等我下来查一下再修改。查了一下C++将用到const常量的地方替换成对应的值这一操作,会因为不同编译器而不同,所以不同于宏替换)
编译器: 主角登场了!将经过预处理的源程序作为输入传递给编译器,编译器可能会产生一个汇编语言程序作为输出。而这个过程对大多数人而言就是一个黑盒子,它能够把源程序映射为语义上面等价的目标程序。
汇编器: 汇编器会对由编译器产生的汇编语言处理,生成可重定位的机器码。那什么是可重定位的机器码?写过LLVM IR的都知道IR是通过br指令在basicblock之间跳转来实现逻辑,这种basicblock被称为逻辑地址空间,而程序在运行的时候,真正用到的是物理地址空间,所以这个时候就需要有一种从逻辑地址到物理地址的映射。由于操作系统给进程分配内存的起始位置L并不固定,所以不能在编译的时候就把逻辑地址和物理地址一一对应写死,要不然程序没法跑了。那怎么办呢?如果在编译时,涉及到有关地址的操作,如某个地址对应数据的读取和写入、地址之间的跳转等有一种动态的方式根据起始位置去调整,这样就可以达到我们的预期(起始位置 +相对地址=绝对地址,根据这个规则调整,感兴趣的可以看看是怎么调整的,挺好理解的,就不展开说了)。而上面的这个根据起始位置动态调整过的代码叫做可重定位代码,它是在加载的时候,也就是系统给进程确定了物理地址时,才生成绝对地址的。
链接器/加载器:
- 链接器,大型程序经常被分为多个部分进行编译,因此可重定位的机器代码有必要和其他可重定位的目标文件以及库文件连接到一起,形成真正在机器上面运行的代码,链接器就是做这件事的。
- 加载器,修改可重定位地址,将修改后的指令和数据放到内存中适当的位置。由汇编器生成可重定位的代码后,逻辑地址和物理地址还并没有生成真实的映射关系,待系统给进程分配了物理地址,根据
起始位置 +相对地址=绝对地址才生成绝对地址。
以上就是一个语言处理器的基本构成,在这里做了个简单的介绍,而我们展开细说的正是编译器。
二、编译器的结构
编译器就是一个程序,他可以阅读以某一种语言(源语言)编写的程序,并把该程序翻译成为一个等价的、用另一种语言(目标语言)编写的程序。编译器一个很重要的任务就是报告他在翻译的过程中发现的源程序中的错误。
之前说编译器对很多人而言是一个黑匣子,但是当你打开这个黑匣子之后就发现,这个黑匣子主要有两部分组成,分析部分(前端)和综合部分(后端)。分析部分主要负责生成中间代码,综合部分主要负责将中间代码转成目标机器代码。注意这里的目标机器代码并不是机器码:如果你要将源语言编译成汇编语言,这里的目标语言就是汇编语言;如果你打算直接编译成机器码,也就是跳过汇编器,那这里的目标语言就是机器码。

从上面编译器的步骤图中可以看出,前端的工作主要包括:词法分析、语法分析、语义检查、生成中间代码。这个过程相对于后端,尤其是优化而言,是相对简单一点,但是也很难,只不过他的所有操作都有了成型的理论支撑,比较好做。当你去给一种复杂的语言从零开始写一个前端的时候(比如基于LLVM做一个语言的编译器),就知道有多酸爽了,写过的人都懂。
后端的主要工作内容:对中间代码优化(也就是机器无关代码优化),生成目标机器语言,对目标语言优化(也就是机器相关代码优化)。
三、词法分析
词法分析(lexical analysis)是编译器的第一个步骤,也叫扫描(scanning),他的主要任务是从左向右逐行扫描源程序的字符,识别出各个单词,确定单词的类型,将识别出的单词转换成统一的机内表示—— 词法单元(token) 形式。等下会通过实例来解释这个概念。下面是词法单元token的组成:
token:<种别码,属性值 >
-
种别码,乍一看还是个很抽象的概念,比如:
if (a > b),词法分析器从左向右逐行按字符读取到的token依次是if、(、a、>、b、)。看过编译器结构就知道,词法分析产生的token是供给语法分析器来进行语法分析的,在语法分析阶段,语法分析器怎么知道前面给的token代表什么内容呢?好办!咋们提前约定好一种对应关系,如果token是if,就给他起个名字叫IF;如果token是(就起个名字叫SLP;如果token是a,就起个名字叫IDN……,当然这个名字你可以随便乱起,但最合理的起名方式就是看到名字知道他代表什么,起的这种名字就叫做种别码。 -
属性值:属性值是指向符号表中关于这个词法单元(token)的符号表条目(我习惯叫符号表项,如果后面叫混了,要知道是一回事),符号表条目的信息会被语义分析和代码生成步骤使用。这里又出现了两个新的概念,符号表和符号表项,现在只需知道这是很重要很重要的两个概念,后面会专门解释。
看下面表格(留意token类型,后面举例会用到):

-
第一行是关键字,高级程序中每个关键字都是确定的,
if就是if,while就是while,所以关键字的种别码是一词一码。 -
第二行是标识符,这就很多了啊!一个程序有若干个变量,若干个函数(学过plsql语言的就知道下表中的记录和过程)等,所以这种就用一个种别码去表示一类标识符就可以,如:用var表示变量,用array表示数组,用func表示函数等。
-
后面几行就按照前面的理解方式理解,一型一码的意思是一种类型对应一个种别码。
-
下面是我们做的语言的部分种别码,这里面的种别码名字和我们后面说到的一些可能不一样,不过不要在意,只需要感受一下就ok:
public enum XcloudTokenType { // 保留字 AND, ARRAY, BEGIN, CASE, CONST, CONTINUE, DELETE, DIV, DO, DOWNTO, ELSE, ELSIF, END, ...... // 表的压缩格式 COMPRESSION, // 伪包名 DBMS_RANDOM, DBMS_UTILITY, // 游标 CURSOR, OPEN, FETCH, CLOSE, // 隐式游标 SQL, NOTFOUND, FOUND, ROWCOUNT, ISOPEN, ROWTYPE, // 分层查询中的伪列 CONNECT_BY_ISCYCLE, CONNECT_BY_ISLEAF, LEVEL, // 分层查询中的一元操作符PRIOR,CONNECT_BY_ROOT PRIOR, CONNECT_BY_ROOT, // DMPP关键字 DMPP_FUNCTION_CALL, DMPP_PROCEDURE_CALL, DMPP_PROCEDURE_SINGLE_CALL, DMPP_FUNCTION_SINGLE_CALL, // 嵌套表 MEMBER, MULTISET, CARDINALITY, // 特殊符号 PLUS("+"), MINUS("-"), STAR("*"), DOUBLE_STAR("**"), SLASH("/"), COLON_EQUALS(":="), DOT("."), COMMA(","), SEMICOLON(";"), COLON(":"), QUOTE("'"), EXCLAMATION_POINTS("!"), EQUALS("="), NOT_EQUALS("<>"), NOT_EQUALS1("!="), NOT_EQUALS2("^="), WAVE_LINE("~"), NOT_EQUALS3("~="), LESS_THAN("<"), LESS_EQUALS("<="), GREATER_EQUALS(">="), GREATER_THAN(">"), LEFT_PAREN("("), RIGHT_PAREN(")"), LEFT_BRACKET("["), DOUBLE_VERTICAL_LINE("||"), VERTICAL_LINE("|"), RIGHT_BRACKET("]"), LEFT_BRACE("{"), RIGHT_BRACE("}"), AT("@"), UP_ARROW("^"), DOT_DOT(".."), QUESTION_MARK("?"), SPECIFIED_PARAM("=>"), }
【举个例子】 词法分析器对下面代码分析时的整个过程,结合下面的图片一起看分析过程。
while(value!=100){
num++;
}
- 词法分析器的位针(我瞎起的一个名称)首先指到第一个字符
w,这是一个字母,什么样的token类型会以字母开始?看上面token表就知道是关键字或标识符,这个时候词法分析器位针向右探一位,但不移动,探取到下一个字符为h,关键字都是由字母组成,标识符也包括字母,所以h不能分割前面的w让其构成一个token,此时词法分析器的位针移到h上面,依次向下探取到i……这样一直重复。直到位针指字母e,向下探取到(,关键字都是由字母组成,所以(不在关键字范畴;标识符是数字、字母下划线(针对一般语言),所以(也不是标识符范畴。此时就可以将前面扫描过得字符串while分割,从而构造成一个token,然后在关键字集合中查找是否有该字符串表示的关键字,一查结果还真有,然后就给该token的设置一个种别码,咋们提前约定好的while关键字的种别码是WHILE,那将其设置上就OK,至于属性值,关键字没有属性值,等后面专门会专门为词法分析开一篇博客,到时候再细讲。 while构造完一个token之后,此时位针在(,分析器一分析,这是一个界限符,包含有(的token就只有左括号本身了,所以(构成一个token,然后再将提前约定好的种别码设置到上面。(构建完成一个token后,位针在v上面,按照构建while的方式,一直向后探取,分析,位针移动,直到位针指向e,此时在向后探取一位字符,发现是!。由于根据目前扫描的字符集构建的token是value,初步分析其是关键字或标识符,但是!并不符合构建这两个的任意一个,所以就此截取value为一个token,将此token在关键字集中查找一下,发现没有value关键字,所以确定此token为标识符,因为标识符是多词一码,所以需要设置一个属性值对其区分。- 再往下走的所有token都在下面这个图中,就不一一分析了,和上面分析方法一样。需要注意,词法分析器在扫描的过程中,遇到空格符、换行符、以及注释等非源码必须的字符时,会将分割当前扫描的字符集构成一个token,然后再跳过空格、换行符、注释等,直到遇到下一个有效字符。这个功能谁来实现?那肯定是你自己呗!其实挺好实现的,这里说就是不要让你在试着分析的时候被其所迷惑。

四、语法分析
语法分析(syntax analysis)是编译器的第二个步骤,也叫解析(parsing)。语法分析器(parser)从词法分析器输出的token序列中识别出各类短语,从而构造语法分析树(syntax tree),并判断源程序在结构上是否正确。
语法分析树其实就是一个树的数据结构,用来描述源程序的语法结构。以一个简单的赋值语句来举例:
position = initial + rate * 60;
赋值语句是计算出等号右边表达式的值,然后再赋值给左边的变量。所以它对应的语法树左子树是个标识符,右子树是个表达式。

加法运算是将加号两边的两个常量或变量相加,所以它对应的语法树左子树和右子树均是标识符或常量。乘法表达式同理。所以上面赋值语句就有了下面的语法树结构:
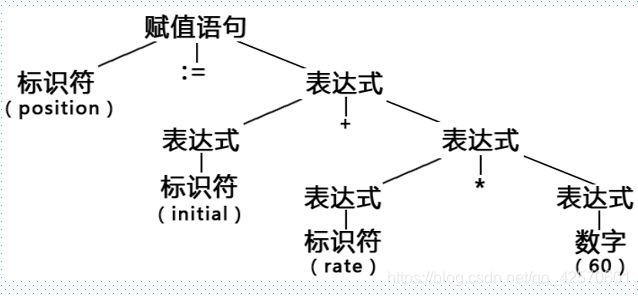
这条赋值语句s = 2 * 3.14 * r * (h + r);相比于上面要复杂些,它对应的语法分析树如下:

可能很多人对于编译器如何解析表达式,从而构建一颗语法树这一过程不甚了解,这里不再做过多的解释,后面会专门开一篇博客来解释。
五、语义分析
语义分析器(semantic analyzer)使用语法树和符号表中的信息来检查源程序是否和语言定义的语义一致。他同时也收集标识符的属性信息,并把这些信息存放在语法树或符号表中(又一次出现了符号表概念),以便在后面中间代码生成过程中使用。
语义分析的一个重要部分是类型检查(type checking)。编译器检查每个运算符是否具有匹配的运算分量,比如数组的下标要求必须是一个整数,如果用浮点数作为数组下标,编译器就应该报错。
所以语义分析主要有两个任务:收集标识符信息、语义检查。收集标识符信息包括标识符的种属 (Kind),如常量、变量、数组、函数等;标识符的类型(type),如整型、实型、字符型等。语义检查主要检查源程序与语言对应的语义是否相一致,一些常用语言的错误语义如下:
- 变量或过程未经声明就使用
- 变量或过程名重复声明
- 运算分量类型不匹配
- 操作符与操作数之间的类型不匹配,如:
- 数组下标不是整数
- 对非数组变量使用数组访问操作符
- 对非过程名使用过程调用操作符
- 过程调用的参数类型或数目不匹配
- 函数返回类型有误
有的编译器是将语法分析和语义分析一起处理的,以下面赋值语句为例解释:
int a = 1;
int sum = 0;
sum = a + 110;
编译器在解析sum = a + 110的语法的时候,就会判断=两边的类型是否相兼容,如果不兼容要报错。在解析a + 110加法表达式的时候,也会判断+两边的表达式是否相兼容,不兼容就会报错,这里注意表达式也会产生一个类型,常见的语言都是int+int产生int,double+int产生double。
而有的编译器是将语法分析和语义分析分成两个部分分别去处理的。编译器首先进行语法解析,在语法解析的时候不做语义检查,而是等语法解析完成后,再基于语法解析生成的语法分析树做语义检查。这两种做法要根据实际情况去选择,之前我们是用的第一种,后面又改了架构,开始用了第二种。
六、中间代码生成
编译器的主要目的就是将高级语言写的源程序翻译成目标机器对应的汇编语言,再交由汇编器去处理生成可重定位的机器码。一般的过程都是:源程序——语法树——中间代码——汇编代码——目标代码,源语言到中间代码一般称为前端,中间代码到目标代码一般成为后端(编译器结构中已说过)。
在这个翻译的过程中,一个编译器可能构造出一个或多个中间表示,且这些中间表示可以有多种形式,比如图IR、线性IR和混合IR。表现为图IR形式的有抽象语法树、偏底层的语法树、有向非循环图等。表现为线性IR形式的有堆栈机代码、三地址码等。混合IR就是将图和线性两种结构混合的IR形式。如果相对IR有进一步认识,可以查阅我总结的《编译器设计(六)——中间代码表示》这边文章。
从源码到AST的过程,我们要进行词法分析、语法分析、语义分析,那为什么要这么做呢?源码呈现给我们的一个文件,解析之前我们不知道它的内容是什么,也就不知道文件中的存放的源码是否符合语言的语法规则。所以我们要一个字符一个字符的去读取文件的内容,判断每个标识符、关键字等是否符合规则,就有了词法分析。然后再判断符合规则的标识符、关键字组合成的文本内容是否符合语法规则,就有了语法分析。最后还要判断语法潜在的语义是否符合规则,就有了语义分析。
而语法树是我们经过前面一系列动作产生的一个中间结果,一般情况下它本身是没有输出的必要的(但可以dump),编译器的输出是汇编代码。所以我们将AST转换为IR时,拿到都是AST在内存中的对象,它的结构肯定都是正确的(不正确前面应该要报语法错误),我们也不用在文件中去读取它。
现在工业界比较流行的一种编译器框架是LLVM,基于LLVM做一些语言的编译器需求也是越来越多,如果感兴趣的话,可以看看LLVM官方文档。我之前参与做过以LLVM作为后端的项目,前端的parse以及生成的完整ast都是我们团队自己做,然后将ast做codeGen生成llvm ir,依靠llvm作为后端。当时做这个项目时我写过几篇LLVM相关的博客,里面有对llvm ir的简单介绍和使用C api生成ir的demo。
下面举了一个简单的例子,从源码到AST再到LLVM IR中间代码的过程如下:
// 常见的高级语言代码:
int a = 10;
int b = 11;
return a + b;
// 生成的AST结构:
assign assign
| | | |
a 10 b 11
return
|
add
| |
a b
// 编译过去之后的IR代码:
%a = alloca i32, align 4 // 为变量a分配内存
store i32 10, i32* %a, align 4 // 将10存入变量a的内存中
%b = alloca i32, align 4
store i32 11, i32* %b, align 4
%0 = load i32, i32* %a, align 4 // 从变量a的地址中取出存放的值
%1 = load i32, i32* %b, align 4
%2 = add nsw i32 %0, %1 // 将a中存放的值和b中存放的值相加
ret i32 %2 // 返回上面相加的结果
编译器后端
后面会再写一篇新的文章,分别介绍:机器无关代码优化、汇编代码生成、目标代码生成、可执行文件生成,也就是优化器、汇编器和链接器所做的事。写完后会在这里附上链接。