利用Jupyter Notebook进行科学计算和数据分析
Jupyter Notebook
Jupyter Notebook 作为一个编辑器,非常的受欢迎。它的代码和输出结果都保存在同一个文件中。需要时直接发一个文件就能在其它电脑快速运行,十分方便。它是ipython开源项目的一部分,而且是完全免费的。
Jupyter Notebook 可以适用不同的编程语言,但主要是Python。
通常使用 Jupyter Notebooks 的最简单方法是安装 Anaconda。Anaconda 是被广泛使用的用于科学计算的 Python 发行版,并且预装了很多常用的库和工具。其中就包括Jupyter。
基本介绍
启动Jupyter后,所展示的工作目录默认是C盘当前用户home目录下。这是我修改启动目录后的结果:

可以看到,其URL是localhost,localhost 不是一个网站,而是表示本地机器中服务的内容。Jupyter notebook 是一个 Web 应用程序,Jupyter 启动了一个本地的 Python 服务,将这些应用提供给浏览器,使其从根本上独立于平台,使得其更容易在 Web 上共享。
ipynb 文件
Jupyter新建的文件后缀为ipynb,例如:myfirstcode.ipynb。每一个 .ipynb 文件是一个文本文件,它以 JSON 的格式来描述 文件 的内容。每个单元格及其内容,包括已被转换成文本字符串的图像附件,都与一些元数据一起列出。Jupyter提供手动编辑元数据,如下图:

编辑元数据,前提是你必须熟悉各个符号的意义,否则可能会出错。Jupyter提供很多接口,可以通过快捷键Ctrl + Shift + P来查看命令列表。如图:

对于Jupyter来说,有两个非常重要的东西:单元格、内核。内核是一个“计算引擎”,它执行一个 notebook 文档中包含的代码。单元格则是一个容器,用于承载文本和代码。
单元格构成一个笔记本的主体。两种主要的单元格类型:
- 代码单元包含要在内核中执行的代码,并在本单元格下方显示输出。
- Markdown 单元包含使用 Markdown 格式化的文本,并在运行时显示其输出。
新建一个文档,其第一个单元格总是代码单元。如下图,我们打印一条语句,点击上面工具栏中的 run 按钮,或者按下 Ctrl + Enter 键,即可运行:
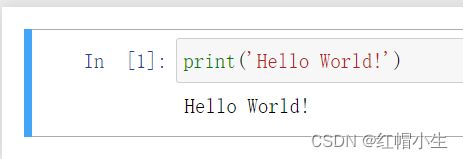
当你运行这个单元格时,它的输出会显示在下方,注意看它的左边,标签从 In [ ] 变为 In [1]。区分代码和 Markdown 单元:代码单元格在左边有标签,而 Markdown 单元没有。
标签的“In”是“输入(input)”的缩写,标签内的数字表示在内核上执行单元格时的顺序 ——In [ 1 ]表示单元格被第一个执行。再次运行单元格,标签将变成 In[2],此时单元格是在内核上运行的第二个单元格。这对内核的深入将非常有用。我们运行以下代码:
import time
time.sleep(3)
这个单元不产生任何输出,但花费3秒时间执行。请注意,运行时标签变成 In[*] ,星号表示单元格正在运行。
一般来说,单元格的输出来自于代码中打印语句,除此外还有单元格中最后一行的值,无论是单独变量,函数调用还是其他内容。例如:
a=1
a
代码没有使用print函数,但依然会输出1。
单元格边框在运行时变成蓝色,在编辑时是绿色的。总有一个“活动”的单元格突出显示其当前模式,绿色表示“编辑模式”,蓝色表示“命令模式”。在编辑和命令模式之间切换,分别使用 Esc 和 Enter。
在命令模式下:
- 用 Up 和 Down 键向上和向下滚动单元格。
- 按 A 或 B 在活动单元上方或下方插入一个新单元。
- M 将会将活动单元格转换为 Markdown 单元格。
- Y 将激活的单元格设置为一个代码单元格。
- D + D(按两次 D)将删除活动单元格。
- Z将撤销单元格删除。
- 按住 Shift,同时按 Up 或 Down ,一次选择多个单元格。
- 选择了 multple,Shift + M 将合并你的选择
- Ctrl + Shift + -,在编辑模式下,将在光标处拆分活动单元格。
内核
在单元格间切换时内核的状态保持不变 —— 它与文档有关,而不是单个的单元格。例如,在一个单元格中导入库或声明变量,可以在另一个单元中使用。 例如:
import numpy as np
def abs(x):
if x>=0:
return x
else:
return -x
一旦我们执行了上面的单元格,就可以在其他单元中直接使用 np库和 abs函数。如果你想要重置一些东西,菜单中有几个选项:
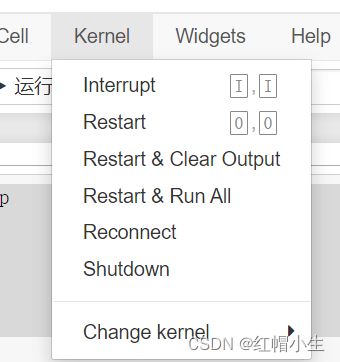
- Restart:重新启动内核,从而清除定义的所有变量。
- Restart & Clear Output:与上面一样,但会擦除代码单元格下面的输出。
- Resatrt & Run All:和上面一样,但会运行所有单元,从第一个到最后。
- 如果内核一直在计算中,我们又希望强行停止,选择 Interupt 选项。
Jupyter 提供更改内核的选项。通过选择 Python 版本创建一个新的笔记,实际上就是在选择使用哪个内核。不仅有不同版本的 Python 的内核,还有(超过 100 种语言),包括 Java 、C ,甚至 Fortran。每个内核都有自己的安装指令。
按 Ctrl + S 键可以通过调用“保存和检查点”命令来保存你的 notebook。每当你创建一个新的 notebook 时,都会创建一个检查点文件以及你的 notebook 文件;它将位于你保存位置的隐藏子目录中称作 .ipynb_checkpoints,也是一个 .ipynb 文件。默认情况下,Jupyter 将每隔 120 秒自动保存你的 notebook,而不会改变你的主 notebook 文件。当你“保存和检查点”时,notebook 和检查点文件都将被更新。因此,检查点使你能够在发生意外事件时恢复未保存的工作。你可以通过 “File > Revert to Checkpoint“ 从菜单恢复到检查点。
数据分析
我们来看这样一道题,分析美国最大公司的利润变化历史。我们有自 1955 年以来,超过 50 年的财富 500 强企业的数据集,这些数据都是从《财富》的公共档案中收集来的。我们已经创建了一个可用数据的 CSV 文件。(数据集获取在文章最下面)
目标:了解美国最大公司的利润在历史上是如何变化的。
%matplotlib inline
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(style="darkgrid")
我们导入 pandas 来处理数据,Matplotlib 绘制图表,Seaborn 美化图表,NumPy 进行矩阵运算。虽然我们使用的是 pandas,但我们不需要显式地使用它。第一行不是 Python 命令,而是使用一种叫做行魔法的东西来指示 Jupyter 捕获 Matplotlib 图并在单元输出中呈现;这是超出本文范围的一系列高级特性之一。
加载数据代码:
df = pd.read_csv('fortune500.csv')
在单独的单元格中编写这行代码,方便我们在任何时候重新加载。我们将数据集 df 加载到最常用的 pandas 数据结构中,叫做 DataFrame(df是DataFrame的缩写,这里表示读取进来的数据) ,看起来就像一张表格。
df.head()
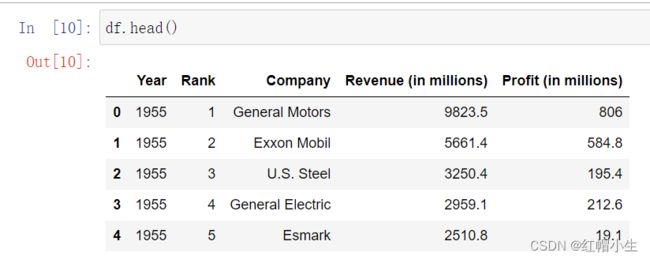
df.head()会将excel表格中的第一行看作列名,并默认输出之后的五行。
df.tail()
df.tail()读取数据表格中的后五项。
df.columns = ['year', 'rank', 'company', 'revenue', 'profit']
我们重命名这些列,方便引用。接下来,我们需要探索这个数据集,包括:是否完整、 pandas 是否按预期方式读取、是否有缺值。
len(df)
输出:25500。说明从 1955 年到 2005 年,每年都有 500 行。数据集完整。接下来检查数据集是否如我们预期的那样被导入。一个简单的检查就是查看数据类型(或 dtypes)是否被正确地解释。
df.dtypes
输出:
year int64
rank int64
company object
revenue float64
profit object
dtype: object
看起来profit这列有点问题,我们希望它是 float64。这说明它可能包含一些非数字值,所以我们要检查一下。
non_numberic_profits = df.profit.str.contains('[^0-9.-]')
df.loc[non_numberic_profits].head()
使用正则表达式来匹配不是数字的行。

从输出结果可以看到,其中一些值是字符串“NA”,用于充填缺失的数据。
set(df.profit[non_numberic_profits])
我们来看缺失了多少个值:
len(df.profit[non_numberic_profits])
输出:369。它只是数据集的一小部分,说它完全无关紧要,但它仍然占1.5% 左右。如果包含 N.A. 的行是简单地、均匀地按年分布的,那最简单的解决方案就是删除它们。所以让我们浏览一下分布。
bin_sizes, _, _ = plt.hist(df.year[non_numberic_profits], bins=range(1955, 2006))
输出如下:
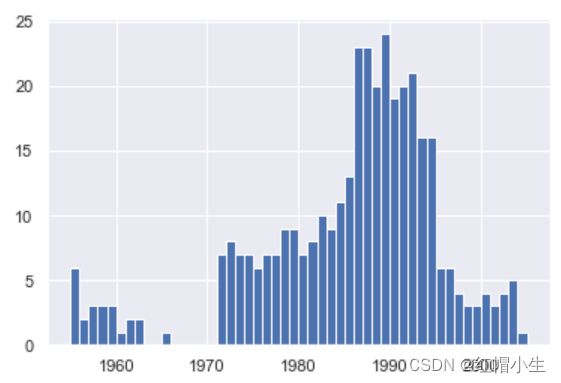
粗略地看,在一年中无效值最多的情况也小于 25,并且由于每年有 500 个数据点,删除这些值在最糟糕的年份中只占不到 4% 的数据。事实上,除了 90 年代的激增,大多数年份的缺失值还不到峰值的50%。我们假设这部分数据缺失是可以接受的,那么只需要删除这些行即可。如下:
df = df.loc[~non_numberic_profits]
df.profit = df.profit.apply(pd.to_numeric)
len(df)输出看看有没有生效。输出:25131。与之前的25500相比,减少了369。再用df.dtypes查看。输出如下:
year int64
rank int64
company object
revenue float64
profit float64
dtype: object
可以看到,我们已经完成了数据集的清理。
matplotlib 进行绘图
接下来,我们可以通过计算年平均利润来解决这个问题。我们不妨把收入也画出来,所以首先我们可以定义一些变量和方法来减少代码冗余。如下:
group_by_year = df.loc[:, ['year', 'revenue', 'profit']].groupby('year')
avgs = group_by_year.mean()
x = avgs.index
y1 = avgs.profit
def plot(x, y, ax, title, y_label):
ax.set_title(title)
ax.set_ylabel(y_label)
ax.plot(x, y)
ax.margins(x=0, y=0)
OK,运行以上代码后,我们接着开始绘图。如下:
fig, ax = plt.subplots()
plot(x, y1, ax, 'Increase in mean Fortune 500 company profits from 1955 to 2005', 'Profit (millions)')
运行结果如图:

观察输出结果,看起来像一个指数趋势,但存在一些大的凹陷。这是对应于上世纪 90 年代初的经济衰退和互联网泡沫。在数据中能看到这一点很有意思。还有一个有趣的现象,就是每次经济衰退之后,利润都能恢复到更高的水平。为了对这一现象进行解释,我们加入收入看看。如下:
y2 = avgs.revenue
fig, ax = plt.subplots()
plot(x, y2, ax, 'Increase in mean Fortune 500 company revenues from 1955 to 2005', 'Revenue (millions)')
输出结果如下图:
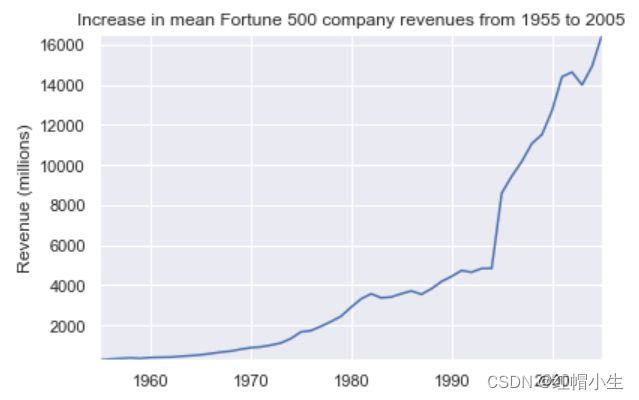
可以看到,收入一直呈增长趋势,几乎没有受到过严重打击。我们用 +/- 它们的标准偏移来叠加这些图(代码参考:传送门):
def plot_with_std(x, y, stds, ax, title, y_label):
ax.fill_between(x, y - stds, y + stds, alpha=0.2)
plot(x, y, ax, title, y_label)
fig, (ax1, ax2) = plt.subplots(ncols=2)
title = 'Increase in mean and std Fortune 500 company %s from 1955 to 2005'
stds1 = group_by_year.std().profit.as_matrix()
stds2 = group_by_year.std().revenue.as_matrix()
plot_with_std(x, y1.as_matrix(), stds1, ax1, title % 'profits', 'Profit (millions)')
plot_with_std(x, y2.as_matrix(), stds2, ax2, title % 'revenues', 'Revenue (millions)')
fig.set_size_inches(14, 4)
fig.tight_layout()
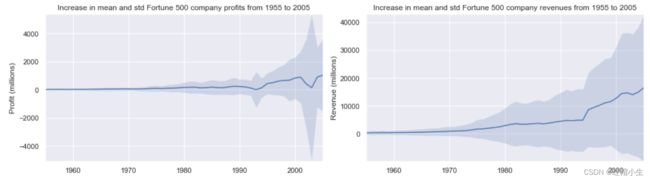
可以看到结果非常惊人,标准偏差十分巨大。一些财富 500 强的公司赚了数十亿,而另一些公司却损失了数十亿美元,而且随着这些年来利润的增长,风险也在增加。前 10% 的利润是否或多或少会比最低的10%稳定一些?
可以看到, notebook 上的工作流程与自己的思维过程相匹配。这一流程帮助我们在无需切换应用程序的情况下轻松地研究我们的数据集,并且可以立即共享和重现。如果我们希望为特定的目标人群创建一个更简洁的报告,我们可以通过合并单元和删除中间代码来快速重构我们的工作。
一些高质量笔记例子:传送门。
共享
我们如果要共享自己的工作成果,在导出或保存时,共享的 notebook 将会以保存那一刻的状态显示,包括所有代码和输出。因此,我们可以在分享之前采取一些步骤:
- 点击 “Cell > All Output > Clear”
- 点击 “Kernel > Restart & Run All”
- 等待代码单元执行完毕,并检查结果是否符合预期。
以上步骤确保你的 notebook 不包含中间输出,不包含陈旧的状态,并在共享时按顺序执行。
Jupyter 内置支持导出 HTML 和 PDF 以及其他几种格式,如图:
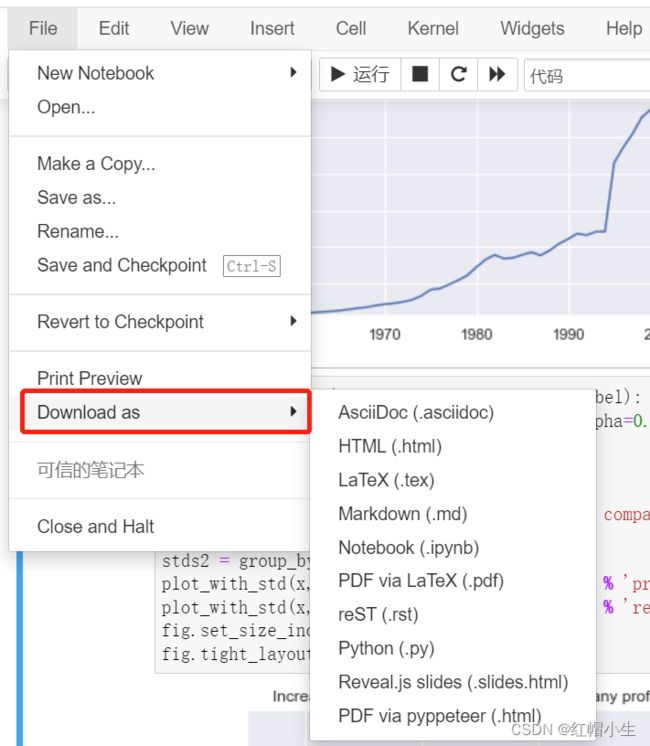
如果你希望与一个私有组共享你的 notebook,这个功能十分有效。但是,如果共享导出的文件不符合你的要求,那么还有一些更流行的方法:共享 .ipynb 文件到网上。
截止到 2018 年初,GitHub 上的公共 notebook 数量超过了 180 万。GitHub 已经集成了对 .ipynb 的文件渲染的支持,你可以直接将其存储在其网站的仓库和 gists 中。在 GitHub 上共享一个 notebook 最简单的方法甚至都不需要 Git。自 2008 年以来, GitHub 为托管和共享代码片段提供了Gist 服务,每个代码段都有自己的存储库。使用 Gists 共享一个 notebook:
- 登录并且访问 gist.github.com。
- 用文件编辑器打开 .ipynb 文件, 全选并且拷贝里面的 JSON 。
- 将笔记的 JSON 粘贴到中 gist 中。
- 给你的 Gist 命名, 记得添加 .iypnb 后缀,否则会出现异常。
- 点击 "Create secret gist"或者 “Create public gist.”
如果你创建了一个公共的 Gist,你就可以和任何人分享它的 URL,其他人将能够 fork 和 clone 你的工作。
Github入门指南:传送门。
更多内容关注笔者公众号:极客随想。回复:财富数据集,即可获取。