mask rcnn 将mask 转json数据01
目的:存在 图片及其对应的mask 文件 ,通过Python代码转化为json 数据,无需手工制作


1、首先准备好 图片和及其对应的mask ,使用的mask为黑底白色
#!/usr/bin/env python3
#把 mask和原图 集合到一个json 文件中
import datetime
import json
import os
import re
import fnmatch
from PIL import Image
import numpy as np
from pycococreatortools import pycococreatortools
ROOT_DIR = 'train'
IMAGE_DIR = os.path.join(ROOT_DIR, "shapes_train2018")
ANNOTATION_DIR = os.path.join(ROOT_DIR, "annotations")
INFO = {
"description": "Example Dataset",
"url": "https://github.com/waspinator/pycococreator",
"version": "0.1.0",
"year": 2018,
"contributor": "waspinator",
"date_created": datetime.datetime.utcnow().isoformat(' ')
}
LICENSES = [
{
"id": 1,
"name": "Attribution-NonCommercial-ShareAlike License",
"url": "http://creativecommons.org/licenses/by-nc-sa/2.0/"
}
]
#适当修改类别
CATEGORIES = [
{
'id': 1,
'name': 'square',
'supercategory': 'shape',
},
{
'id': 2,
'name': 'circle',
'supercategory': 'shape',
},
{
'id': 3,
'name': 'triangle',
'supercategory': 'shape',
},
]
#返回rgb文件路径 不做修改
def filter_for_jpeg(root, files):
file_types = ['*.jpeg', '*.jpg']
file_types = r'|'.join([fnmatch.translate(x) for x in file_types])
files = [os.path.join(root, f) for f in files]
files = [f for f in files if re.match(file_types, f)]
return files
#返回mask文件路径 不做修改
def filter_for_annotations(root, files, image_filename):
file_types = ['*.png']
file_types = r'|'.join([fnmatch.translate(x) for x in file_types])
basename_no_extension = os.path.splitext(os.path.basename(image_filename))[0]
file_name_prefix = basename_no_extension + '.*'
files = [os.path.join(root, f) for f in files]
files = [f for f in files if re.match(file_types, f)]
files = [f for f in files if re.match(file_name_prefix, os.path.splitext(os.path.basename(f))[0])]
return files
def main():
coco_output = {
"info": INFO,
"licenses": LICENSES,
"categories": CATEGORIES,
"images": [],
"annotations": []
}
image_id = 1
segmentation_id = 1
# filter for jpeg images
for root, _, files in os.walk(IMAGE_DIR):
image_files = filter_for_jpeg(root, files)
# go through each image
for image_filename in image_files:
image = Image.open(image_filename)
image_info = pycococreatortools.create_image_info(
image_id, os.path.basename(image_filename), image.size)
coco_output["images"].append(image_info)
# filter for associated png annotations
for root, _, files in os.walk(ANNOTATION_DIR):
annotation_files = filter_for_annotations(root, files, image_filename)
# go through each associated annotation
for annotation_filename in annotation_files:
print(annotation_filename)
class_id = [x['id'] for x in CATEGORIES if x['name'] in annotation_filename][0]
category_info = {'id': class_id, 'is_crowd': 'crowd' in image_filename}
binary_mask = np.asarray(Image.open(annotation_filename)
.convert('1')).astype(np.uint8)
annotation_info = pycococreatortools.create_annotation_info(
segmentation_id, image_id, category_info, binary_mask,
image.size, tolerance=2)
if annotation_info is not None:
coco_output["annotations"].append(annotation_info)
segmentation_id = segmentation_id + 1
image_id = image_id + 1
with open('{}/instances_shape_train2018.json'.format(ROOT_DIR), 'w') as output_json_file:
json.dump(coco_output, output_json_file)
if __name__ == "__main__":
main()
上面代码是 多个标注数据 数据集合到一个json文件中的
{"info": {"description": "Example Dataset", "url": "https://github.com/waspinator/pycococreator", "version": "0.1.0", "year": 2018, "contributor": "waspinator", "date_created": "2021-03-13 06:54:48.550064"}, "licenses": [{"id": 1, "name": "Attribution-NonCommercial-ShareAlike License", "url": "http://creativecommons.org/licenses/by-nc-sa/2.0/"}], "categories": [{"id": 1, "name": "square", "supercategory": "shape"}], "images": [{"id": 1, "file_name": "0.jpg", "width": 256, "height": 384, "date_captured": "2021-03-13 04:34:17.084304", "license": 1, "coco_url": "", "flickr_url": ""}, {"id": 2, "file_name": "1.jpg", "width": 256, "height": 384, "date_captured": "2021-03-13 04:34:17.084304", "license": 1, "coco_url": "", "flickr_url": ""}, {"id": 3, "file_name": "2.jpg", "width": 384, "height": 256, "date_captured": "2021-03-13 04:34:17.084304", "license": 1, "coco_url": "", "flickr_url": ""}], "annotations": [{"id": 1, "image_id": 1, "category_id": 1, "iscrowd": 0, "area": 130, "bbox": [106.0, 109.0, 31.0, 15.0], "segmentation": [[126.0, 123.5, 113.0, 121.5, 105.5, 109.0, 118.0, 120.5, 136.5, 115.0, 126.0, 123.5]], "width": 256, "height": 384}, {"id": 2, "image_id": 2, "category_id": 1, "iscrowd": 0, "area": 1734, "bbox": [51.0, 158.0, 41.0, 69.0], "segmentation": [[74.0, 226.5, 54.5, 213.0, 50.5, 194.0, 70.5, 160.0, 76.0, 157.5, 81.5, 161.0, 82.5, 171.0, 91.5, 177.0, 91.5, 185.0, 84.5, 210.0, 74.0, 226.5]], "width": 256, "height": 384}, {"id": 3, "image_id": 3, "category_id": 1, "iscrowd": 0, "area": 2444, "bbox": [233.0, 127.0, 33.0, 104.0], "segmentation": [[254.0, 230.5, 237.5, 229.0, 244.5, 220.0, 242.5, 191.0, 232.5, 175.0, 236.5, 171.0, 232.5, 166.0, 235.5, 150.0, 245.0, 126.5, 254.5, 130.0, 264.5, 149.0, 264.5, 224.0, 254.0, 230.5]], "width": 384, "height": 256}]}2 下面的代码是 ,每对数据 对应一个json 文件(只能实现mask中 只有一个类的情况)
#!/usr/bin/env python3
#功能批量将mask 转单个json
import datetime
import json
import os
import io
import re
import fnmatch
import json
from PIL import Image
import numpy as np
from pycococreatortools import pycococreatortools
from PIL import Image
import base64
from base64 import b64encode
ROOT_DIR = 'train1'
IMAGE_DIR = os.path.join(ROOT_DIR, "pic")
ANNOTATION_DIR = os.path.join(ROOT_DIR, "annotations")
def img_tobyte(img_pil):
# 类型转换 重要代码
# img_pil = Image.fromarray(roi)
ENCODING='utf-8'
img_byte=io.BytesIO()
img_pil.save(img_byte,format='PNG')
binary_str2=img_byte.getvalue()
imageData = base64.b64encode(binary_str2)
base64_string = imageData.decode(ENCODING)
return base64_string
annotation_files=os.listdir(ANNOTATION_DIR)
for annotation_filename in annotation_files:
coco_output = {
"version": "3.16.7",
"flags": {},
"fillColor": [255, 0,0,128],
"lineColor": [0,255,0, 128],
"imagePath": {},
"shapes": [],
"imageData": {},
"imageHeight": 512,
"imageWidth": 512
}
print(annotation_filename)
class_id = 1
name = annotation_filename.split('.',3)[0]
name1=name+'.jpg'
coco_output["imagePath"]=name1
image = Image.open(IMAGE_DIR+'/'+ name1)
imageData=img_tobyte(image)
coco_output["imageData"]= imageData
binary_mask = np.asarray(Image.open(ANNOTATION_DIR+'/'+annotation_filename)
.convert('1')).astype(np.uint8)
segmentation=pycococreatortools.binary_mask_to_polygon(binary_mask, tolerance=3)
list1=[]
for i in range(0, len(segmentation[0]), 2):
list1.append( [segmentation[0][i],segmentation[0][i+1]])
seg_info = {'points': list1, "fill_color":'null' ,"line_color":'null' ,"label": "1", "shape_type": "polygon","flags": {}}
coco_output["shapes"].append(seg_info)
full_path='{}/'+name+'.json'
with open( full_path.format(ROOT_DIR), 'w') as output_json_file:
json.dump(coco_output, output_json_file)
3 需要自己改写成 自己需要的文件
#!/usr/bin/env python3
#功能批量将多个同类mask 转单个json
#筛选多余的点集合 可能mask制作的不规范,产生多余的点,这样的话,利用点的数量,做一个限制
#我这里设置的是10 可根据具体效果改动
for item in segmentation:
if(len(item)>10):
list1=[]
for i in range(0, len(item), 2):
list1.append( [item[i],item[i+1]])
seg_info = {'points': list1, "fill_color":'null' ,"line_color":'null' ,"label": "1", "shape_type": "polygon","flags": {}}
coco_output["shapes"].append(seg_info)
coco_output[ "imageHeight"]=binary_mask.shape[0]
coco_output[ "imageWidth"]=binary_mask.shape[1]
full_path='{}/'+name+'.json'
with open( full_path.format(ROOT_DIR), 'w') as output_json_file:
json.dump(coco_output, output_json_file)
完善的代码
#!/usr/bin/env python3
#功能批量将多个同类mask 转单个json
import datetime
import json
import os
import io
import re
import fnmatch
import json
from PIL import Image
import numpy as np
from pycococreatortools import pycococreatortools
from PIL import Image
import base64
from base64 import b64encode
ROOT_DIR = 'C:/Users/11549/Desktop/pycococreator-master/examples/shapes/train2/pic/'
IMAGE_DIR = os.path.join(ROOT_DIR, "pic")
ANNOTATION_DIR = os.path.join(ROOT_DIR, "mask")
def img_tobyte(img_pil):
# 类型转换 重要代码
# img_pil = Image.fromarray(roi)
ENCODING='utf-8'
img_byte=io.BytesIO()
img_pil.save(img_byte,format='PNG')
binary_str2=img_byte.getvalue()
imageData = base64.b64encode(binary_str2)
base64_string = imageData.decode(ENCODING)
return base64_string
annotation_files=os.listdir(ANNOTATION_DIR)
for annotation_filename in annotation_files:
coco_output = {
"version": "3.16.7",
"flags": {},
"fillColor": [255, 0,0,128],
"lineColor": [0,255,0, 128],
"imagePath": {},
"shapes": [],
"imageData": {} }
print(annotation_filename)
class_id = 1
name = annotation_filename.split('.',3)[0]
name1=name+'.jpg'
coco_output["imagePath"]=name1
image = Image.open(IMAGE_DIR+'/'+ name1)
imageData=img_tobyte(image)
coco_output["imageData"]= imageData
binary_mask = np.asarray(Image.open(ANNOTATION_DIR+'/'+annotation_filename)
.convert('1')).astype(np.uint8)
segmentation=pycococreatortools.binary_mask_to_polygon(binary_mask, tolerance=3)
#筛选多余的点集合
for item in segmentation:
if(len(item)>10):
list1=[]
for i in range(0, len(item), 2):
list1.append( [item[i],item[i+1]])
seg_info = {'points': list1, "fill_color":'null' ,"line_color":'null' ,"label": "1", "shape_type": "polygon","flags": {}}
coco_output["shapes"].append(seg_info)
coco_output[ "imageHeight"]=binary_mask.shape[0]
coco_output[ "imageWidth"]=binary_mask.shape[1]
full_path='{}/'+name+'.json'
with open( full_path.format(ROOT_DIR), 'w') as output_json_file:
json.dump(coco_output, output_json_file)
4 生成的json文件,效果如下
{
"version": "3.20.0",
"flags": {},
"shapes": [
{
"label": "1",
"line_color": null,
"fill_color": null,
"points": [
[
362.59375,
166.1875
],
[
357.90625,
216.96875
],
[
429.78125,
216.96875
],
[
436.03125,
171.65625
]
],
"shape_type": "polygon",
"flags": {}
}
],
"lineColor": [
0,
255,
0,
128
],
"fillColor": [
255,
0,
0,
128
],
"imagePath": "3.jpg",
"imageData": "/9j/4AAQSkZJRgABAQAAAQABAAD/2wBDAAgGBgcGBQgHBwcJCQgKDBQNDAsLDBkSEw8UHRofHh0aHBwgJC4nICIsIxwcKDcpLDAxNDQ0Hyc5PTgyPC4zNDL/2wBDAQkJCQwLDBgNDRgyIRwhMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjL/wAARCAIAAgADASIAAhEBAxEB/8QAHwAAAQUBAQEBAQEAAAAAAAAAAAECAwQFBgcICQoL/8QAtRAAAgEDAwIEAwUFBAQAAAF9AQIDAAQRBRIhMUEGE1FhByJxFDKBkaEII0KxwRVS0fAkM2JyggkKFhcYGRolJicoKSo0NTY3ODk6Q0RFRkdISUpTVFVWV1hZWmNkZWZnaGlqc3R1dnd4eXqDhIW QS+trmElPmVv057GpFfU//9k=",
"imageHeight": 512,
"imageWidth": 512
}这样我们就有了 json数据和图片数据了,可以安装步骤生成 coco格式的数据l
5 把json数据和图片数据放在一起,利用各bat脚本 生成labelme_json 数据 如下图所示。
@echo off
for %%i in (*.json) do labelme_json_to_dataset "%%i"
pause
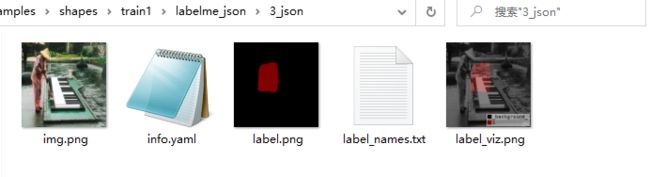
6 然而 其中的label.png 文件,并不可用 需要转为8位的数据 才可以使用
下面是批量的代码
import numpy as np
from PIL import Image
import os
YourFile_path='labelme_json/'
files = os.listdir(YourFile_path)
path1='cv2_mask/'
for item in files:
src=YourFile_path+item+'/label.png'
img= Image.open(src)
img = Image.fromarray(np.uint8(img))
name = item.split("_")[0]
name=name+'.png'
img.save( path1+name)最终生成 可以使用的数据 输入mask -rcnn中,
7 零碎的代码
#针对一个box的检测程序,输出x , y, w, h 文件名
#统计bbox的程序
import cv2
import os
import operator
path='mask/'
def takeSecond1(elem):
return list(elem)[2]*list(elem)[3]
list1=[ ]
filelist = os.listdir(path)
for item in filelist:
bgr_img = cv2.imread(path+item)
gray_img = cv2.cvtColor(bgr_img, cv2.COLOR_BGR2GRAY)
gray_img = cv2.blur(gray_img, (5,5))
th, binary = cv2.threshold(gray_img, 125, 255, cv2.THRESH_OTSU)
contours, hierarchy = cv2.findContours(binary, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
bounding_boxes = [cv2.boundingRect(cnt) for cnt in contours]
bounding_boxes.sort(key=takeSecond1)
list1.append([item,bgr_img.shape,bounding_boxes[-1]])
# cv2.drawContours(bgr_img, contours, -1, (0, 0, 255), 3)
# for i in range(len(bounding_boxes)):
# print(i)
# cv2.imshow("name", bgr_img)
# cv2.waitKey(6000)
# cv2.destroyAllWindows()#coco 可视化代码
from pycocotools.coco import COCO
import numpy as np
import skimage.io as io
import matplotlib.pyplot as plt
import pylab
image_directory = 'train/shapes_train2018/'
annotation_file = 'C:/Users/11549/Desktop/pycococreator-master/examples/shapes/train/instances_shape_train2018.json'
example_coco = COCO(annotation_file)
categories = example_coco.loadCats(example_coco.getCatIds())
category_names = [category['name'] for category in categories]
print('Custom COCO categories: \n{}\n'.format(' '.join(category_names)))
category_names = set([category['supercategory'] for category in categories])
print('Custom COCO supercategories: \n{}'.format(' '.join(category_names)))
category_ids = example_coco.getCatIds(catNms=['square'])
image_ids = example_coco.getImgIds(catIds=category_ids)
image_data = example_coco.loadImgs(image_ids[np.random.randint(0, len(image_ids))])[0]
image_data
# load and display instance annotations
image = io.imread(image_directory + image_data['file_name'])
plt.imshow(image); plt.axis('off')
pylab.rcParams['figure.figsize'] = (8.0, 10.0)
annotation_ids = example_coco.getAnnIds(imgIds=image_data['id'], catIds=category_ids, iscrowd=None)
annotations = example_coco.loadAnns(annotation_ids)
example_coco.showAnns(annotations)#重命名代码
import os
path = 'C:/Users/11549/Desktop/pycococreator-master/examples/shapes/train1/shapes_train2018/cv2mask/'
filelist = os.listdir(path)
for i in range(len(filelist)):
print(i)
src = os.path.join(os.path.abspath(path),filelist[i])
dst = os.path.join(os.path.abspath(path),str(i) + '.png')
os.rename(src,dst)
import os
import cv2
path = 'pic/'
path1 = '1/'
# os.access(path+'0002-01.jpg', os.F_OK)
filelist = os.listdir(path)
for item in filelist:
src = os.path.join(os.path.abspath(path),item)
img = cv2.imread(src)
res=cv2.resize(img,(757,568))
cv2.imwrite(path1+item, res)
8 相应的安装包 下载地址:https://download.csdn.net/download/weixin_44576543/15806642
last one 由于时间比较急 ,所以比较粗糙 大家不懂的可以留言评论