Spring Boot单体应用引入sleuth链路追踪
文章目录
- 前言
- 一、问题模拟
- 二、引入sleuth链路跟踪
-
- 1、引入sleuth的maven依赖
- 2、添加属性配置
- 3、logback配置
- 4、日志信息
- 5、通过@NewSpan注解声明新的Span
- 三、引入Sleuth链路跟踪的好处
- 四、Sleuth概念说明
- 五、Logback的MDC特性
前言
最近排查生产环境的异常时发现一个问题,虽然找到了请求入参的日志信息,但是由于生产环境的请求并发量比较大,无法确定后续执行过程中打印的日志以及返回信息和入参的对应关系,无法理清请求的完整链路信息,给定位问题带来了很大的挑战。所以不止在微服务架构,单体应用下也强烈推荐引入sleuth链路跟踪。
一、问题模拟
定义日志切面,采用环绕通知记录请求入参和返回结果。
/**
* Web层日志切面
*/
@Aspect
@Component
@Slf4j
public class WebLogAspect {
/**
* 定义切面
*/
@Pointcut("execution(public * com.laowan.limit.controller..*.*(..))")
public void webLog(){
}
@Around(value = "webLog()")
public Object handleControllerMethod(ProceedingJoinPoint joinPoint) throws Throwable {
StopWatch stopWatch = StopWatch.createStarted();
ServletRequestAttributes attributes = (ServletRequestAttributes) RequestContextHolder.getRequestAttributes();
HttpServletRequest request = attributes.getRequest();
String params = this.getRequestParams(request,joinPoint);
log.info("【请求信息】请求url:{},参数:{} ", request.getServletPath(), params);
//继续下一个通知或目标方法调用,返回处理结果,如果目标方法发生异常,则 proceed 会抛异常.
//如果在调用目标方法或者下一个切面通知前抛出异常,则不会再继续往后走.
Object proceed = joinPoint.proceed(joinPoint.getArgs());
stopWatch.stop();
long watchTime = stopWatch.getTime();
log.info("【响应结果】返回值={},耗时={} (毫秒)", proceed, watchTime);
return proceed;
}
/**
* 异常通知:目标方法发生异常的时候执行以下代码,此时返回通知@AfterReturning不会再触发
* @param jp
* @param ex
*/
@AfterThrowing(pointcut = "webLog()", throwing = "ex")
public void aspectAfterThrowing(JoinPoint jp, Exception ex) {
String methodName = jp.getSignature().getName();
log.error("【后置异常通知】{}方法异常:{}" ,methodName, ex.getMessage());
}
/**
* 获取请求参数
* @param request
* @param joinPoint
*/
private String getRequestParams(HttpServletRequest request, JoinPoint joinPoint) throws JsonProcessingException {
StringBuilder params = new StringBuilder();
// 获取 request parameter 中的参数
Map<String, String[]> parameterMap = request.getParameterMap();
if (parameterMap != null && !parameterMap.isEmpty()) {
for (Map.Entry<String, String[]> entry : parameterMap.entrySet()) {
params.append(entry.getKey()).append(" = ").append(Arrays.toString(entry.getValue())).append(";");
}
}
// 获取非 request parameter 中的参数
Object[] objects = joinPoint.getArgs();
for (Object arg : objects) {
if (arg == null) {
break;
}
String className = arg.getClass().getName().toLowerCase();
String contentType = request.getHeader("Content-Type");
if (contentType != null && contentType.contains("application/json")){
// json 参数
ObjectMapper mapper = new ObjectMapper();
mapper.configure(SerializationFeature.FAIL_ON_EMPTY_BEANS, false);
mapper.setVisibility(PropertyAccessor.FIELD, JsonAutoDetect.Visibility.ANY);
params.append(mapper.writeValueAsString(arg));
}
}
return params.toString();
}
}
单次请求日志信息:
![]()
并发请求下日志信息:

问题说明:
在并发请求下,请求日志的对应关系只能借助请求的执行线程[nio-8080-exec-*]间接实现关联,但是每个执行线程都会一直处理新的HTTP请求,并且在集群环境下,线程名称很可能还会重复。这种情况下,我们很难根据日志信息理清一个请求的完整执行链路信息。
二、引入sleuth链路跟踪
链路跟踪的实现方案有很多,这里我采用的是spring-cloud-starter-sleuth。
Sleuth可以单独使用,也可以整合Zipkin使用。这里我只需要生成日志的链路信息,所以单独使用Sleuth。
官网信息:Only Sleuth (log correlation)
1、引入sleuth的maven依赖
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.4.2</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<dependencies>
<!--引入sleuth依赖-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
……
</dependencies>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>2020.0.1</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
注意:
这里需要主要spring boot和spring-cloud版本之间的兼容关系。
官网的组件版本对应地址:spring cloud官网集成组件版本对应说明
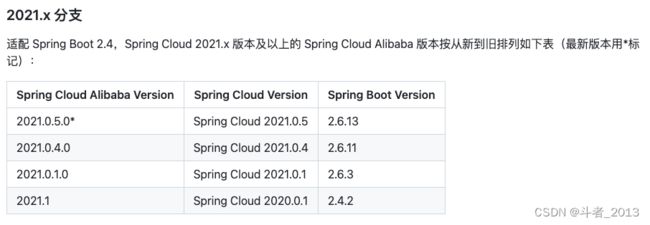
2、添加属性配置
# 开启sleuth链路跟踪,默认为true,所以可以省略配置
spring.sleuth.enabled = true
# 配置服务名称
spring.application.name=Sleuth
3、logback配置
关于sleuth链路跟踪下logback的日志配置信息,可以参考官网的demo:
Logback配置:logback-spring.xml
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<include resource="org/springframework/boot/logging/logback/defaults.xml"/>
<springProperty scope="context" name="springAppName" source="spring.application.name"/>
<!-- Example for logging into the build folder of your project -->
<property name="LOG_FILE" value="${BUILD_FOLDER:-build}/${springAppName}"/>
<!-- You can override this to have a custom pattern -->
<property name="CONSOLE_LOG_PATTERN"
value="%clr(%d{yyyy-MM-dd HH:mm:ss.SSS}){faint} %clr(${LOG_LEVEL_PATTERN:-%5p}) %clr(${PID:- }){magenta} %clr(---){faint} %clr([%15.15t]){faint} %clr(%-40.40logger{39}){cyan} %clr(:){faint} %m%n${LOG_EXCEPTION_CONVERSION_WORD:-%wEx}"/>
<!-- Appender to log to console -->
<appender name="console" class="ch.qos.logback.core.ConsoleAppender">
<filter class="ch.qos.logback.classic.filter.ThresholdFilter">
<!-- Minimum logging level to be presented in the console logs-->
<level>DEBUG</level>
</filter>
<encoder>
<pattern>${CONSOLE_LOG_PATTERN}</pattern>
<charset>utf8</charset>
</encoder>
</appender>
<!-- Appender to log to file -->
<appender name="flatfile" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${LOG_FILE}</file>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${LOG_FILE}.%d{yyyy-MM-dd}.gz</fileNamePattern>
<maxHistory>7</maxHistory>
</rollingPolicy>
<encoder>
<!-- 注意:这里不用使用控制台格式${CONSOLE_LOG_PATTERN}输出 -->
<pattern>${FILE_LOG_PATTERN}</pattern>
<charset>utf8</charset>
</encoder>
</appender>
<root level="INFO">
<appender-ref ref="console"/>
<appender-ref ref="flatfile"/>
</root>
</configuration>
注意:
1、文本日志输出flatfile不要采用彩色日志输出,不然在生成的日志文件中查看会看到很多的乱码信息。
2、如果要进行日志采集,推荐采用logstash将日志以json格式输出,方便字段解析。
4、日志信息

日志的格式为:[application name, traceId, spanId]
- application name — 应用的名称,也就是application.properties中spring.application.name参数配置的属性。
- traceId — 为一个请求分配的ID号,用来标识一条请求链路。
- spanId — 表示一个基本的工作单元,一个请求可以包含多个步骤,每个步骤都拥有自己的spanId。一个请求只会有一个TraceId,但可以有多个SpanId。
5、通过@NewSpan注解声明新的Span
@Slf4j
@Service
public class OrderServiceImpl implements OrderService {
@NewSpan
@Override
public void order(Order order) throws Exception {
Thread.sleep(200);
log.info("下单");
}
}

注意:在同一个类中@NewSpan不生效。
三、引入Sleuth链路跟踪的好处
1、通过日志信息中的traceId,可以轻松的找出单次请求的所有相关日志信息,理清整个请求的完整链路。
2、通过日志信息中的traceId、spanId和日志输出时间信息,可以得出整个请求以及各个阶段span的耗时情况。
四、Sleuth概念说明
Spring Cloud Sleuth采用的是Google的开源项目Dapper的专业术语。
● Span:基本工作单元,例如,在一个新建的span中发送一个RPC等同于发送一个回应请求给RPC,span通过一个64位ID唯一标识,trace以另一个64位ID表示,span还有其他数据信息,比如摘要、时间戳事件、关键值注释(tags)、span的ID、以及进度ID(通常是IP地址)
span在不断的启动和停止,同时记录了时间信息,当你创建了一个span,你必须在未来的某个时刻停止它。
● Trace:一系列spans组成的一个树状结构,例如,如果你正在跑一个分布式大数据工程,你可能需要创建一个trace。
● Annotation:用来及时记录一个事件的存在,一些核心annotations用来定义一个请求的开始和结束
○ cs - Client Sent -客户端发起一个请求,这个annotion描述了这个span的开始
○ sr - Server Received -服务端获得请求并准备开始处理它,如果将其sr减去cs时间戳便可得到网络延迟
○ ss - Server Sent -注解表明请求处理的完成(当请求返回客户端),如果ss减去sr时间戳便可得到服务端需要的处理请求时间
○ cr - Client Received -表明span的结束,客户端成功接收到服务端的回复,如果cr减去cs时间戳便可得到客户端从服务端获取回复的所有所需时间

五、Logback的MDC特性
Logback的MDC特性,即Mapped Diagnostic Contexts (诊断上下文映射)。
Logback的设计目标之一是审计和调试复杂的分布式应用程序。大多数实际的分布式系统需要同时处理来自多个客户端的请求。为了区分开每个客户端的日志,也为了能够快速定位某个请求日志来自哪个客户端,最简单地方式是,给每个客户端的每个日志请求一个唯一标记。为了对每个请求进行惟一的标记,用户将上下文信息放入MDC中。
MDC类仅包含静态方法,它使开发人员可以将信息放置在诊断上下文中,这些环境可以随后通过某些记录组件检索。MDC根据每个线程管理上下文信息。通常,在开始为新客户请求服务时,开发人员将插入相关的上下文信息,例如客户端ID,客户端的IP地址,请求参数等。LOGBACK组件(如果适当配置)将自动在每个日志条目中包含此信息。
package org.slf4j;
public class MDC {
//Put a context value as identified by key
//into the current thread's context map.
public static void put(String key, String val);
//Get the context identified by the key parameter.
public static String get(String key);
//Remove the context identified by the key parameter.
public static void remove(String key);
//Clear all entries in the MDC.
public static void clear();
}
所以sleuth负责生成traceId和spanId信息,并将信息传入到Logback的诊断映射上下文(DMC)中,然后由Logback根据具体的日志格式进行日志输出。
Only Sleuth (log correlation)
logback的MDC特性
Spring-Cloud-Sleuth介绍
spring cloud官网集成组件版本对应说明