Spring Cloud Ribbon源码解析,Ribbon为什么可以实现负载均衡,为什么可以用服务名调用
文章目录
- 一、Ribbon概述
-
- 1、Ribbon简单使用
-
- (1)引包
- (2)使用方式一:RestTemplate+@LoadBalanced
- (3)使用方式二:LoadBalancerClient
- 2、问题来了
- 二、前置知识回顾
-
- 1、复习@Qualifier的作用
- 2、@LoadBalanced分析
- 三、源码分析-关键Bean的自动装配
-
- 1、LoadBalancerAutoConfiguration
-
- (1)注入RestTemplate
- (2)注入SmartInitializingSingleton
- (3)配置LoadBalancerInterceptorConfig
- 2、RibbonAutoConfiguration
-
- (1)注入LoadBalancerClient
- 3、小总结
- 四、源码分析-restTemplate执行拦截的过程
-
- 1、createRequest
- 2、request.execute()
- 3、InterceptingRequestExecution.execute()
- 五、源码分析-RestTemplate拦截器执行过程
-
- 1、了解LoadBalancerClient
- 2、requestFactory.createRequest
- 3、loadBalancer.execute
- 4、getLoadBalancer
- 5、认识ILoadBalancer
-
- (1)ZoneAwareLoadBalancer
- (2)BaseLoadBalancer
- 6、getServer
- 7、小总结
- 六、源码分析-最终执行过程
-
- 1、request.apply(serviceInstance)
- 七、源码分析-服务列表是如何获取的
-
- 1、lb.getAllServers()
- 2、DynamicServerListLoadBalancer的初始化
- 3、定时更新Server列表——enableAndInitLearnNewServersFeature
-
- (1)PollingServerListUpdater的初始化
- 4、updateListOfServers
-
- (1)updateAllServerList
- (2)实现一个Pinger
- (3)自定义一个Ping
- 5、小总结
- 八、源码分析-Ribbon负载均衡策略
-
- 1、默认PredicateBasedRule——轮询算法
- 2、RetryRule——重试算法
- 3、WeightedResponseTimeRule——响应时间权重算法
- 4、自定义Bibbon负载均衡策略
一、Ribbon概述
Spring Cloud Ribbon是基于Netflix Ribbon实现的一套客户端 负载均衡的工具。
简单的说,Ribbon是Neflix发布的开源项目,主要功能是提供客户端的软件负载均衡算法和服务调用。Ribbon客户端组件提供一系列完善的配置项如连接超时,重试等。简单的说,就是在配置文件中列出Load Balancer(简称LB)后面所有的机器,Ribbon会自动的帮助你基于某种规则(如简单轮询,随机连接等)去连接这些机器。我们很容易使用Ribbon实现自定义的负载均衡算法。
注!本文需要一定的Ribbon、Springcloud基础,不是入门级文章
1、Ribbon简单使用
学习ribbon,进来看看吧
(1)引包
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-starter-netflix-ribbonartifactId>
dependency>
需要将项目注册到注册中心,任一注册中心都可,或者手动配置指定服务的提供者的地址列表:
# 配置指定服务的提供者的地址列表
spring-cloud-order-service.ribbon.listOfServers=\
localhost:8080,localhost:8082
(2)使用方式一:RestTemplate+@LoadBalanced
@Bean
@LoadBalanced // 重点
public RestTemplate restTemplate(RestTemplateBuilder restTemplateBuilder){
return restTemplateBuilder.build(); // 直接new RestTemplate() 也可
}
@Autowired
RestTemplate restTemplate;
@GetMapping("/user/{id}")
public String findById(@PathVariable("id")int id){
// 调用订单的服务获得订单信息 spring-cloud-order-service 就是order服务的name
return restTemplate.getForObject("http://spring-cloud-order-service/orders",String.class);
}
(3)使用方式二:LoadBalancerClient
@Autowired
RestTemplate restTemplate;
@Bean
//@LoadBalanced 这个不能加!
public RestTemplate restTemplate(RestTemplateBuilder restTemplateBuilder){
return restTemplateBuilder.build(); // 直接new RestTemplate() 也可
}
@Autowired
LoadBalancerClient loadBalancerClient;
@GetMapping("/user/{id}")
public String findById(@PathVariable("id")int id){
// 调用订单的服务获得订单信息
ServiceInstance serviceInstance=loadBalancerClient.choose("spring-cloud-order-service");
String url=String.format("http://%s:%s",serviceInstance.getHost(),serviceInstance.getPort()+"/orders");
return restTemplate.getForObject(url,String.class);
}
2、问题来了
为什么RestTemplate 加上@LoadBalanced ,就可以解析服务名,并且实现负载均衡了呢?
二、前置知识回顾
1、复习@Qualifier的作用
spring依赖查找、依赖注入深入学习及源码分析
在上面文章中,全面介绍了Spring的依赖注入与依赖查找。其中二、依赖注入(10、限定注入)中,写了@Qualifier的作用,我们在此再复习一次。
@Configuration
public class TestConfiguration {
@Bean("testClass1")
TestClass testClass1(){
return new TestClass("TestClass1");
}
@Qualifier
@Bean("testClass2")
TestClass testClass2(){
return new TestClass("TestClass2");
}
}
@Qualifier // 加了本注解的,只能注入到本注解分组的Bean,也就是只能注入到testClass2
@Autowired
List<TestClass> testClassList= Collections.emptyList();
@Configuration
public class TestConfiguration {
@Bean("testClass1")
TestClass testClass1(){
return new TestClass("TestClass1");
}
@Qualifier
@Bean("testClass2")
TestClass testClass2(){
return new TestClass("TestClass2");
}
@UserGroup
@Bean("testClass3")
TestClass testClass3(){
return new TestClass("TestClass3");
}
}
@Qualifier // 注入加了@Qualifier、@UserGroup的bean,因为@UserGroup被@Qualifier修饰了
@Autowired
List<TestClass> testClassList= Collections.emptyList();
@UserGroup// 注入加了@UserGroup的Bean,虽然@UserGroup被@Qualifier修饰了,但是加了@Qualifier的Bean不会被注入
@Autowired
List<TestClass> testClassList2= Collections.emptyList();
2、@LoadBalanced分析
我们看一下@LoadBalanced的源码,发现被@Qualifier修饰了。
@Target({ ElementType.FIELD, ElementType.PARAMETER, ElementType.METHOD })
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Inherited
@Qualifier
public @interface LoadBalanced {
}
所以,我们用@LoadBalanced标注的RestTemplate这个Bean,肯定后续被分组了。
@Bean
@LoadBalanced
public RestTemplate restTemplate(RestTemplateBuilder restTemplateBuilder){
return restTemplateBuilder.build();
}
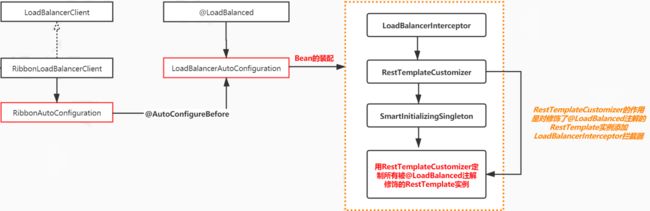
三、源码分析-关键Bean的自动装配
1、LoadBalancerAutoConfiguration
LoadBalancerAutoConfiguration 就是用于LoadBalanced的自动装配。
@Configuration(proxyBeanMethods = false)
@ConditionalOnClass(RestTemplate.class)
@ConditionalOnBean(LoadBalancerClient.class)
@EnableConfigurationProperties(LoadBalancerRetryProperties.class)
public class LoadBalancerAutoConfiguration {
(1)注入RestTemplate
我们发现,此处注入的RestTemplate,是由@LoadBalanced修饰的。
@LoadBalanced
@Autowired(required = false)
private List<RestTemplate> restTemplates = Collections.emptyList();
(2)注入SmartInitializingSingleton
将RestTemplateCustomizer加入被@LoadBalanced修饰的RestTemplate。
RestTemplateCustomizer的作用就是对修饰了@LoadBalanced的RestTemplate实例添加LoadBalancerInterceptor拦截器。
@Bean
public SmartInitializingSingleton loadBalancedRestTemplateInitializerDeprecated(
final ObjectProvider<List<RestTemplateCustomizer>> restTemplateCustomizers) {
return () -> restTemplateCustomizers.ifAvailable(customizers -> {
// 遍历所有RestTemplateCustomizer,将所有的@LoadBalanced修饰的RestTemplate都调用customize方法加入拦截器(customize方法在下面(3)中定义的)
for (RestTemplate restTemplate : LoadBalancerAutoConfiguration.this.restTemplates) {
for (RestTemplateCustomizer customizer : customizers) {
customizer.customize(restTemplate);
}
}
});
}
(3)配置LoadBalancerInterceptorConfig
@Configuration(proxyBeanMethods = false)
@ConditionalOnMissingClass("org.springframework.retry.support.RetryTemplate")
static class LoadBalancerInterceptorConfig {
// 定义拦截器
@Bean
public LoadBalancerInterceptor ribbonInterceptor(
LoadBalancerClient loadBalancerClient,
LoadBalancerRequestFactory requestFactory) {
return new LoadBalancerInterceptor(loadBalancerClient, requestFactory);
}
// RestTemplateCustomizer的作用就是对修饰了@LoadBalanced的RestTemplate实例添加LoadBalancerInterceptor拦截器。
@Bean
@ConditionalOnMissingBean
public RestTemplateCustomizer restTemplateCustomizer(
final LoadBalancerInterceptor loadBalancerInterceptor) {
// 返回一个RestTemplateCustomizer匿名内部类,方法中将上面定义的拦截器放入restTemplate中
return restTemplate -> {
List<ClientHttpRequestInterceptor> list = new ArrayList<>(
restTemplate.getInterceptors());
list.add(loadBalancerInterceptor);
restTemplate.setInterceptors(list);
};
}
}
到这,相当于将@LoadBalanced修饰的RestTemplate加入了拦截器。
2、RibbonAutoConfiguration
RibbonAutoConfiguration用于Ribbon的自动装配。
@Configuration
@Conditional(RibbonAutoConfiguration.RibbonClassesConditions.class)
@RibbonClients
@AutoConfigureAfter(
name = "org.springframework.cloud.netflix.eureka.EurekaClientAutoConfiguration")
@AutoConfigureBefore({ LoadBalancerAutoConfiguration.class,
AsyncLoadBalancerAutoConfiguration.class })
@EnableConfigurationProperties({ RibbonEagerLoadProperties.class,
ServerIntrospectorProperties.class })
public class RibbonAutoConfiguration {
(1)注入LoadBalancerClient
@Bean
@ConditionalOnMissingBean(LoadBalancerClient.class)
public LoadBalancerClient loadBalancerClient() {
return new RibbonLoadBalancerClient(springClientFactory());
}
这也是我们一开始,也可以使用LoadBalancerClient 的方式使用Ribbon了。
3、小总结
自动装配的过程,就是将修饰了@LoadBalanced的RestTemplate的Bean添加LoadBalancerInterceptor拦截器。
同时Ribbon装配了一个关键Bean,就是RibbonLoadBalancerClient。
四、源码分析-restTemplate执行拦截的过程
我们直接进入到RestTemplate这个类的doExecute方法,因为前面部分的代码都比较简单没有太多逻辑。
这段代码中有一个很重要的逻辑,就是createRequest,这个是构建客户端请求的一个方法。
// org.springframework.web.client.RestTemplate#doExecute
@Nullable
protected <T> T doExecute(URI url, @Nullable HttpMethod method, @Nullable RequestCallback requestCallback,
@Nullable ResponseExtractor<T> responseExtractor) throws RestClientException {
Assert.notNull(url, "URI is required");
Assert.notNull(method, "HttpMethod is required");
ClientHttpResponse response = null;
try {
// 创建请求客户端
ClientHttpRequest request = createRequest(url, method);
if (requestCallback != null) {
requestCallback.doWithRequest(request);
}
// 执行
response = request.execute();
handleResponse(url, method, response);
return (responseExtractor != null ? responseExtractor.extractData(response) : null);
}
catch (IOException ex) {
String resource = url.toString();
String query = url.getRawQuery();
resource = (query != null ? resource.substring(0, resource.indexOf('?')) : resource);
throw new ResourceAccessException("I/O error on " + method.name() +
" request for \"" + resource + "\": " + ex.getMessage(), ex);
}
finally {
if (response != null) {
response.close();
}
}
}
1、createRequest
这里个方法是用来创建一个请求对象,其中getRequestFactory(),调用的是InterceptingHttpAccessor中的getRequestFactory方法,因为InterceptingHttpAccessor继承了HttpAccessor这个类,重写了getRequestFactory方法。
// org.springframework.http.client.support.HttpAccessor#createRequest
protected ClientHttpRequest createRequest(URI url, HttpMethod method) throws IOException {
ClientHttpRequest request = getRequestFactory().createRequest(url, method);
initialize(request);
if (logger.isDebugEnabled()) {
logger.debug("HTTP " + method.name() + " " + url);
}
return request;
}
// org.springframework.http.client.support.InterceptingHttpAccessor#getRequestFactory
//其中,getRequestFactory方法代码如下,其中getInterceptors是获得当前客户端请求的所有拦截器,需要注意的是,这里的拦截器,就包含LoadBalancerInterceptor.
@Override
public ClientHttpRequestFactory getRequestFactory() {
// 获取所有拦截器
List<ClientHttpRequestInterceptor> interceptors = getInterceptors();
if (!CollectionUtils.isEmpty(interceptors)) {
ClientHttpRequestFactory factory = this.interceptingRequestFactory;
if (factory == null) {//构建一个InterceptingClientHttpRequestFactory工厂,并且将所有的拦截器作为参数传入
factory = new InterceptingClientHttpRequestFactory(super.getRequestFactory(), interceptors);
this.interceptingRequestFactory = factory;
}
return factory;
}
else {
return super.getRequestFactory();
}
}
// org.springframework.http.client.support.InterceptingHttpAccessor#getInterceptors
public List<ClientHttpRequestInterceptor> getInterceptors() {
return this.interceptors;
}
这个方法中返回的拦截器列表,是从InterceptingHttpAccessor.setInterceptors()方法来设置的,而这个setInterceptors()调用的地方正好是LoadBalancerAutoConfiguration.LoadBalancerInterceptorConfig.restTemplateCustomizer。
上面我们分析到,LoadBalancerAutoConfiguration会定义拦截器,并放入RestTemplate中,这里面调用了restTemplate.setInterceptors这个方法设置拦截器,其中RestTemplate又集成了InterceptingHttpAccessor。
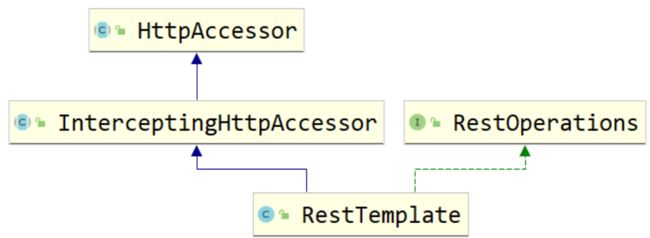
所以,再回到createRequest方法中,getRequestFactory()方法返回的是InterceptingClientHttpRequestFactory,而createRequest方法,最终返回的是InterceptingClientHttpRequest这个类。
2、request.execute()
获取到ClientHttpRequest(实际为InterceptingClientHttpRequest)之后,RestTemplate.doExecute方法中,就会继续往下执行request.execute()方法。
// org.springframework.web.client.RestTemplate#doExecute
// ...
response = request.execute();
// ...
那么这个时候,request.execute调用谁呢?于是我们看一下InterceptingClientHttpRequest的类关系图,我们发现它有两个父类。这是一种模版方法的设计。
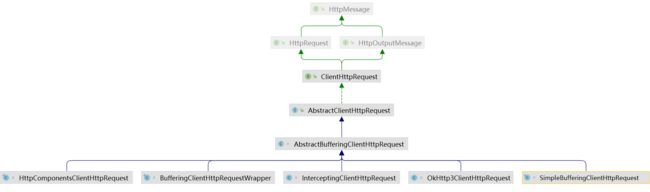
// org.springframework.http.client.AbstractClientHttpRequest#execute
@Override
public final ClientHttpResponse execute() throws IOException {
assertNotExecuted();
ClientHttpResponse result = executeInternal(this.headers);
this.executed = true;
return result;
}
// org.springframework.http.client.AbstractBufferingClientHttpRequest#executeInternal(org.springframework.http.HttpHeaders)
@Override
protected ClientHttpResponse executeInternal(HttpHeaders headers) throws IOException {
byte[] bytes = this.bufferedOutput.toByteArray();
if (headers.getContentLength() < 0) {
headers.setContentLength(bytes.length);
}
ClientHttpResponse result = executeInternal(headers, bytes);
this.bufferedOutput = new ByteArrayOutputStream(0);
return result;
}
// org.springframework.http.client.InterceptingClientHttpRequest#executeInternal
@Override
protected final ClientHttpResponse executeInternal(HttpHeaders headers, byte[] bufferedOutput) throws IOException {
InterceptingRequestExecution requestExecution = new InterceptingRequestExecution();
return requestExecution.execute(this, bufferedOutput);
}
最终,我们进入到InterceptingClientHttpRequest.executeInternal方法。
3、InterceptingRequestExecution.execute()
InterceptingRequestExecution是InterceptingClientHttpRequest的内部类,
在InterceptingRequestExecution.execute方法中,有两个处理逻辑:如果有配置多个客户端拦截器,则调用拦截器方法,对请求进行拦截
否则,按照正常的处理逻辑进行远程调用。
// org.springframework.http.client.InterceptingClientHttpRequest.InterceptingRequestExecution
private class InterceptingRequestExecution implements ClientHttpRequestExecution {
private final Iterator<ClientHttpRequestInterceptor> iterator;
public InterceptingRequestExecution() {
this.iterator = interceptors.iterator();
}
@Override
public ClientHttpResponse execute(HttpRequest request, byte[] body) throws IOException {
if (this.iterator.hasNext()) { // 如果有配置多个客户端拦截器,则调用拦截器方法,对请求进行拦截
ClientHttpRequestInterceptor nextInterceptor = this.iterator.next();
return nextInterceptor.intercept(request, body, this);
}
else { // 按照正常的处理逻辑进行远程调用
HttpMethod method = request.getMethod();
Assert.state(method != null, "No standard HTTP method");
ClientHttpRequest delegate = requestFactory.createRequest(request.getURI(), method);
request.getHeaders().forEach((key, value) -> delegate.getHeaders().addAll(key, value));
if (body.length > 0) {
if (delegate instanceof StreamingHttpOutputMessage) {
StreamingHttpOutputMessage streamingOutputMessage = (StreamingHttpOutputMessage) delegate;
streamingOutputMessage.setBody(outputStream -> StreamUtils.copy(body, outputStream));
}
else {
StreamUtils.copy(body, delegate.getBody());
}
}
return delegate.execute();
}
}
}
我们配置了拦截器,肯定是需要走拦截的那一步。
五、源码分析-RestTemplate拦截器执行过程
我们上面分析到,Bean自动装配会在RestTemplate中装配一个LoadBalancerInterceptor,此时就会进入到LoadBalancerInterceptor的intercept方法,它主要实现了对于请求的拦截。。
// org.springframework.cloud.client.loadbalancer.LoadBalancerInterceptor#intercept
@Override
public ClientHttpResponse intercept(final HttpRequest request, final byte[] body,
final ClientHttpRequestExecution execution) throws IOException {
final URI originalUri = request.getURI();//获得请求的URI :http://spring-cloud-order-service/orders
String serviceName = originalUri.getHost();//获得服务名称:spring-cloud-order-service
Assert.state(serviceName != null,
"Request URI does not contain a valid hostname: " + originalUri);
// 从前面自动装配我们知道this.loadBalancer实际是LoadBalancerClient.
// requestFactory就是LoadBalancerRequestFactory
return this.loadBalancer.execute(serviceName,
this.requestFactory.createRequest(request, body, execution));
}
1、了解LoadBalancerClient
public interface LoadBalancerClient extends ServiceInstanceChooser {
<T> T execute(String serviceId, LoadBalancerRequest<T> request) throws IOException;
<T> T execute(String serviceId, ServiceInstance serviceInstance,
LoadBalancerRequest<T> request) throws IOException;
URI reconstructURI(ServiceInstance instance, URI original);
}
LoadBalancerClient其实是一个接口,我们看一下它的类图,它有两个具体的实现。
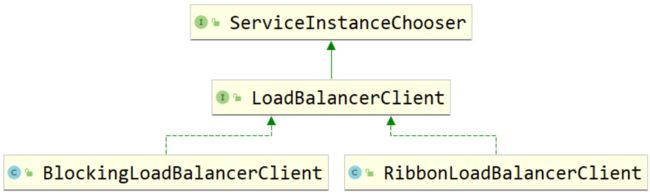
此时,LoadBalancerClient的具体实例应该是RibbonLoadBalancerClient,这个对象实例是在RibbonAutoConfiguration这个类中进行注入的。
2、requestFactory.createRequest
该方法构建了一个LoadBalancerRequest,定义了其apply方法,后续会执行到
// org.springframework.cloud.client.loadbalancer.LoadBalancerRequestFactory#createRequest
public LoadBalancerRequest<ClientHttpResponse> createRequest(
final HttpRequest request, final byte[] body,
final ClientHttpRequestExecution execution) {
return instance -> {
HttpRequest serviceRequest = new ServiceRequestWrapper(request, instance,
this.loadBalancer);
if (this.transformers != null) {
for (LoadBalancerRequestTransformer transformer : this.transformers) {
serviceRequest = transformer.transformRequest(serviceRequest,
instance);
}
}
return execution.execute(serviceRequest, body);
};
}
3、loadBalancer.execute
// org.springframework.cloud.netflix.ribbon.RibbonLoadBalancerClient#execute(java.lang.String, org.springframework.cloud.client.loadbalancer.LoadBalancerRequest)
@Override
public <T> T execute(String serviceId, LoadBalancerRequest<T> request)
throws IOException {
return execute(serviceId, request, null);
}
public <T> T execute(String serviceId, LoadBalancerRequest<T> request, Object hint)
throws IOException {
ILoadBalancer loadBalancer = getLoadBalancer(serviceId); // 根据serviceId获得一个ILoadBalancer
Server server = getServer(loadBalancer, hint); // 调用getServer方法去获取一个服务实例
if (server == null) { // 判断Server的值是否为空。这里的Server实际上就是传统的一个服务节点,这个对象存储了服务节点的一些元数据,比如host、port等
throw new IllegalStateException("No instances available for " + serviceId);
}
RibbonServer ribbonServer = new RibbonServer(serviceId, server,
isSecure(server, serviceId),
serverIntrospector(serviceId).getMetadata(server));
return execute(serviceId, ribbonServer, request);
}
4、getLoadBalancer
// org.springframework.cloud.netflix.ribbon.RibbonLoadBalancerClient#getLoadBalancer
protected ILoadBalancer getLoadBalancer(String serviceId) {
return this.clientFactory.getLoadBalancer(serviceId);
}
// org.springframework.cloud.netflix.ribbon.SpringClientFactory#getInstance
@Override
public <C> C getInstance(String name, Class<C> type) {
C instance = super.getInstance(name, type);
if (instance != null) {
return instance;
}
IClientConfig config = getInstance(name, IClientConfig.class);
return instantiateWithConfig(getContext(name), type, config);
}
// org.springframework.cloud.context.named.NamedContextFactory#getInstance(java.lang.String, java.lang.Class)
public <T> T getInstance(String name, Class<T> type) {
AnnotationConfigApplicationContext context = getContext(name);
if (BeanFactoryUtils.beanNamesForTypeIncludingAncestors(context,
type).length > 0) {
return context.getBean(type);
}
return null;
}
通过工厂模式,获取到ILoadBalancer,最终是从容器中获取的ILoadBalancer。
而ILoadBalancer是在RibbonClientConfiguration这个类中自动装配的,默认就是ZoneAwareLoadBalancer:
// org.springframework.cloud.netflix.ribbon.RibbonClientConfiguration#ribbonLoadBalancer
@Bean
@ConditionalOnMissingBean
public ILoadBalancer ribbonLoadBalancer(IClientConfig config,
ServerList<Server> serverList, ServerListFilter<Server> serverListFilter,
IRule rule, IPing ping, ServerListUpdater serverListUpdater) {
if (this.propertiesFactory.isSet(ILoadBalancer.class, name)) {
return this.propertiesFactory.get(ILoadBalancer.class, config, name);
}
return new ZoneAwareLoadBalancer<>(config, rule, ping, serverList,
serverListFilter, serverListUpdater);
}
5、认识ILoadBalancer
ILoadBalancer这个是一个负载均衡器接口。
public interface ILoadBalancer {
// addServers表示向负载均衡器中维护的实例列表增加服务实例
public void addServers(List<Server> newServers);
// .chooseServer表示通过某种策略,从负载均衡服务器中挑选出一个具体的服务实例
public Server chooseServer(Object key);
// .markServerDown表示用来通知和标识负载均衡器中某个具体实例已经停止服务,否则负载均衡器在下一次获取服务实例清单前都会认为这个服务实例是正常工作的
public void markServerDown(Server server);
// getReachableServers表示获取当前正常工作的服务实例列表
public List<Server> getReachableServers();
// getAllServers表示获取所有的服务实例列表,包括正常的服务和停止工作的服务
public List<Server> getAllServers();
}
我们看一下ILoadBalancer的类关系图
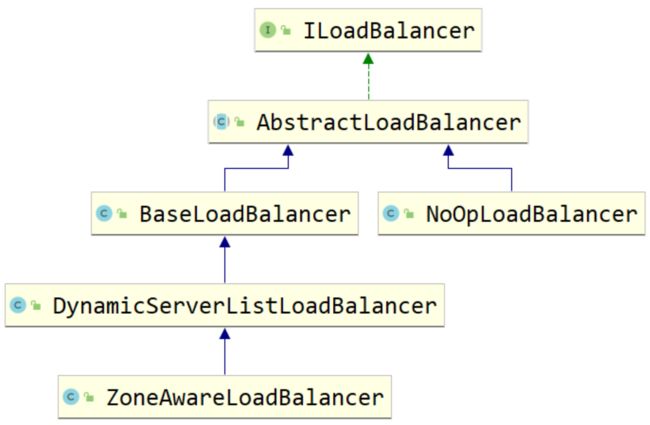
从整个类的关系图来看,BaseLoadBalancer类实现了基础的负载均衡,而DynamicServerListLoadBalancer和ZoneAwareLoadBalancer则是在负载均衡策略的基础上做了一些功能扩展。
- AbstractLoadBalancer实现了ILoadBalancer接口,它定义了服务分组的枚举类/chooseServer(用来选取一个服务实例)/getServerList(获取某一个分组中的所有服务实例)/getLoadBalancerStats用来获得一个LoadBalancerStats对象,这个对象保存了每一个服务的状态信息。
- BaseLoadBalancer,它实现了作为负载均衡器的基本功能,比如服务列表维护、服务存活状态监测、负载均衡算法选择Server等。但是它只是完成基本功能,在有些复杂场景中还无法实现,比如动态服务列表、Server过滤、Zone区域意识(服务之间的调用希望尽可能是在同一个区域内进行,减少延迟)。
- DynamicServerListLoadBalancer是BaseLoadbalancer的一个子类,它对基础负载均衡提供了扩展,从名字上可以看出,它提供了动态服务列表的特性。
- ZoneAwareLoadBalancer 它是在DynamicServerListLoadBalancer的基础上,增加了以Zone的形式来配置多个LoadBalancer的功能。
(1)ZoneAwareLoadBalancer
Zone表示区域的意思,区域指的就是地理区域的概念,一般较大规模的互联网公司,都会做跨区域部署,这样做有几个好处,第一个是为不同地域的用户提供最近的访问节点减少访问延迟,其次是为了保证高可用,做容灾处理。
而ZoneAwareLoadBalancer就是提供了具备区域意识的负载均衡器,它的主要作用是对Zone进行了感知,保证每个Zone里面的负载均衡策略都是隔离的,它并不保证A区域过来的请求一定会发动到A区域对应的Server内。真正实现这个需求的是ZonePreferenceServerListFilter/ZoneAffinityServerListFilter 。
ZoneAwareLoadBalancer的核心功能是:
- 若开启了区域意识,且zone的个数 > 1,就继续区域选择逻辑
- 根据ZoneAvoidanceRule.getAvailableZones()方法拿到可用区们(会T除掉完全不可用的区域们,以及可用但是负载最高的一个区域)
- 从可用区zone们中,通过ZoneAvoidanceRule.randomChooseZone随机选一个zone出来 (该随机遵从权重规则:谁的zone里面Server数量最多,被选中的概率越大)
- 在选中的zone里面的所有Server中,采用该zone对对应的Rule,进行choose
// com.netflix.loadbalancer.ZoneAwareLoadBalancer#chooseServer
@Override
public Server chooseServer(Object key) {
//ENABLED,表示是否用区域意识的choose选择Server,默认是true,
//如果禁用了区域、或者只有一个zone,就直接按照父类的逻辑来进行处理,父类默认采用轮询算法
if (!ENABLED.get() || getLoadBalancerStats().getAvailableZones().size() <= 1) {
logger.debug("Zone aware logic disabled or there is only one zone");
return super.chooseServer(key);
}
Server server = null;
try {
LoadBalancerStats lbStats = getLoadBalancerStats();
Map<String, ZoneSnapshot> zoneSnapshot = ZoneAvoidanceRule.createSnapshot(lbStats);
logger.debug("Zone snapshots: {}", zoneSnapshot);
if (triggeringLoad == null) {
triggeringLoad = DynamicPropertyFactory.getInstance().getDoubleProperty(
"ZoneAwareNIWSDiscoveryLoadBalancer." + this.getName() + ".triggeringLoadPerServerThreshold", 0.2d);
}
if (triggeringBlackoutPercentage == null) {
triggeringBlackoutPercentage = DynamicPropertyFactory.getInstance().getDoubleProperty(
"ZoneAwareNIWSDiscoveryLoadBalancer." + this.getName() + ".avoidZoneWithBlackoutPercetage", 0.99999d);
}
//根据相关阈值计算可用区域
Set<String> availableZones = ZoneAvoidanceRule.getAvailableZones(zoneSnapshot, triggeringLoad.get(), triggeringBlackoutPercentage.get());
logger.debug("Available zones: {}", availableZones);
if (availableZones != null && availableZones.size() < zoneSnapshot.keySet().size()) {
//从可用区域中随机选择一个区域,zone里面的服务器节点越多,被选中的概率越大
String zone = ZoneAvoidanceRule.randomChooseZone(zoneSnapshot, availableZones);
logger.debug("Zone chosen: {}", zone);
if (zone != null) {
//根据zone获得该zone中的LB,然后根据该Zone的负载均衡算法选择一个server
BaseLoadBalancer zoneLoadBalancer = getLoadBalancer(zone);
server = zoneLoadBalancer.chooseServer(key);
}
}
} catch (Exception e) {
logger.error("Error choosing server using zone aware logic for load balancer={}", name, e);
}
if (server != null) {
return server;
} else {
logger.debug("Zone avoidance logic is not invoked.");
return super.chooseServer(key);
}
}
(2)BaseLoadBalancer
根据默认的负载均衡算法来获得指定的服务节点。默认的算法是RoundBin。
// com.netflix.loadbalancer.BaseLoadBalancer#chooseServer
public Server chooseServer(Object key) {
if (counter == null) {
counter = createCounter();
}
counter.increment();
if (rule == null) {
return null;
} else {
try {
// 默认为PredicateBasedRule
return rule.choose(key);
} catch (Exception e) {
logger.warn("LoadBalancer [{}]: Error choosing server for key {}", name, key, e);
return null;
}
}
}
rule就是可以选择的负载均衡规则:
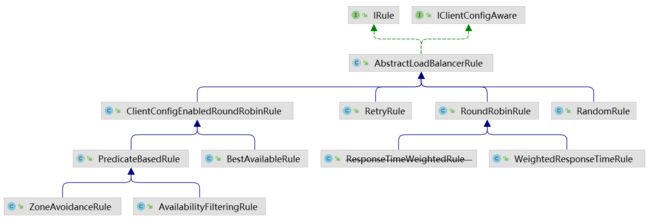
6、getServer
getServer是用来获得一个具体的服务节点,它的实现如下
// org.springframework.cloud.netflix.ribbon.RibbonLoadBalancerClient#getServer(com.netflix.loadbalancer.ILoadBalancer, java.lang.Object)
protected Server getServer(ILoadBalancer loadBalancer, Object hint) {
if (loadBalancer == null) {
return null;
}
// Use 'default' on a null hint, or just pass it on?
return loadBalancer.chooseServer(hint != null ? hint : "default");
}
通过代码可以看到,getServer实际调用了IloadBalancer.chooseServer这个方法,最终获取的Server就是根据负载均衡算法获取的最终Server,最终的Server就是携带者正常的URL的地址了,将原来的服务名给替换掉了。
上面我们也分析了chooseServer方法,最终默认是使用轮询算法。
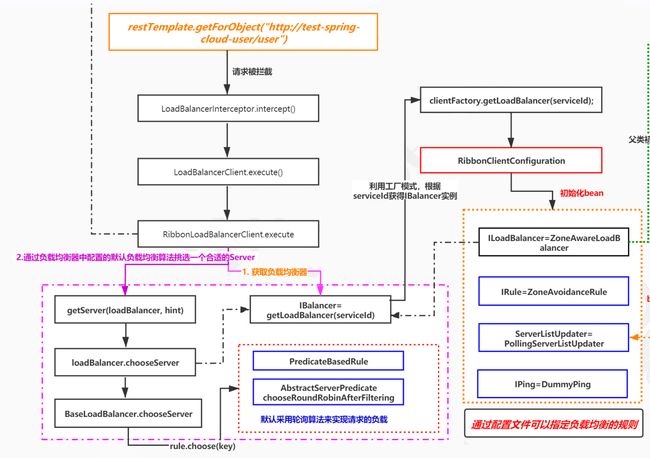
7、小总结
RestTemplate最终是走到了拦截器里面,通过拦截器获取到负载均衡算法,然后将服务名称替换为真正的URL。
六、源码分析-最终执行过程
上面我们分析到,通过getServer,通过负载均衡算法,通过服务id获取到真正的Server。
// org.springframework.cloud.netflix.ribbon.RibbonLoadBalancerClient#execute(java.lang.String, org.springframework.cloud.client.loadbalancer.LoadBalancerRequest, java.lang.Object)
public <T> T execute(String serviceId, LoadBalancerRequest<T> request, Object hint)
throws IOException {
ILoadBalancer loadBalancer = getLoadBalancer(serviceId);
// 获取到Server
Server server = getServer(loadBalancer, hint);
if (server == null) {
throw new IllegalStateException("No instances available for " + serviceId);
}
// 将Server包装
RibbonServer ribbonServer = new RibbonServer(serviceId, server,
isSecure(server, serviceId),
serverIntrospector(serviceId).getMetadata(server));
return execute(serviceId, ribbonServer, request);
}
并且将Server进行包装,最终执行execute方法。
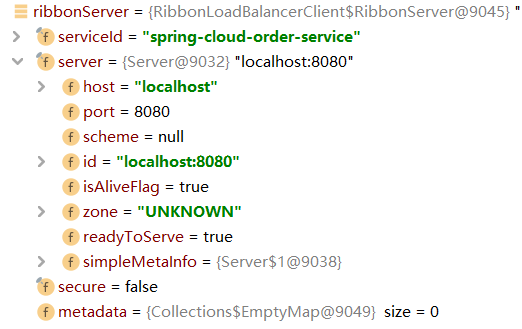
最终调用的是LoadBalancerRequest的apply方法。
// org.springframework.cloud.netflix.ribbon.RibbonLoadBalancerClient#execute(java.lang.String, org.springframework.cloud.client.ServiceInstance, org.springframework.cloud.client.loadbalancer.LoadBalancerRequest)
@Override
public <T> T execute(String serviceId, ServiceInstance serviceInstance,
LoadBalancerRequest<T> request) throws IOException {
Server server = null;
if (serviceInstance instanceof RibbonServer) {
server = ((RibbonServer) serviceInstance).getServer();
}
if (server == null) {
throw new IllegalStateException("No instances available for " + serviceId);
}
RibbonLoadBalancerContext context = this.clientFactory
.getLoadBalancerContext(serviceId);
RibbonStatsRecorder statsRecorder = new RibbonStatsRecorder(context, server);
try {
// 执行动作
T returnVal = request.apply(serviceInstance);
statsRecorder.recordStats(returnVal);
return returnVal;
}
// catch IOException and rethrow so RestTemplate behaves correctly
catch (IOException ex) {
statsRecorder.recordStats(ex);
throw ex;
}
catch (Exception ex) {
statsRecorder.recordStats(ex);
ReflectionUtils.rethrowRuntimeException(ex);
}
return null;
}
1、request.apply(serviceInstance)
在上面我们说到,调用loadBalancer.execute之前,会先调用this.requestFactory.createRequest(request, body, execution)定义一个LoadBalancerRequest。此处就会调用LoadBalancerRequest的apply方法,下面的lambda表达式就是定义的apply方法。
// org.springframework.cloud.client.loadbalancer.LoadBalancerRequestFactory#createRequest
public LoadBalancerRequest<ClientHttpResponse> createRequest(
final HttpRequest request, final byte[] body,
final ClientHttpRequestExecution execution) {
return instance -> {
// ServiceRequestWrapper会对URI进行重构
HttpRequest serviceRequest = new ServiceRequestWrapper(request, instance,
this.loadBalancer);
if (this.transformers != null) {
for (LoadBalancerRequestTransformer transformer : this.transformers) {
serviceRequest = transformer.transformRequest(serviceRequest,
instance);
}
}
// execution就是InterceptingClientHttpRequest$InterceptingRequestExecution
return execution.execute(serviceRequest, body);
};
}
此时,我们再次又回到InterceptingRequestExecution.execute(),上面也已经分析过了。
InterceptingRequestExecution是InterceptingClientHttpRequest的内部类,
在InterceptingRequestExecution.execute方法中,有两个处理逻辑:如果有配置多个客户端拦截器,则调用拦截器方法,对请求进行拦截
否则,按照正常的处理逻辑进行远程调用。
// org.springframework.http.client.InterceptingClientHttpRequest.InterceptingRequestExecution
private class InterceptingRequestExecution implements ClientHttpRequestExecution {
private final Iterator<ClientHttpRequestInterceptor> iterator;
public InterceptingRequestExecution() {
this.iterator = interceptors.iterator();
}
@Override
public ClientHttpResponse execute(HttpRequest request, byte[] body) throws IOException {
if (this.iterator.hasNext()) { // 如果有配置多个客户端拦截器,则调用拦截器方法,对请求进行拦截
ClientHttpRequestInterceptor nextInterceptor = this.iterator.next();
return nextInterceptor.intercept(request, body, this);
}
else { // 按照正常的处理逻辑进行远程调用
HttpMethod method = request.getMethod();
Assert.state(method != null, "No standard HTTP method");
// 创建了HttpComponentsClientHttpRequest,这里调用了getURI方法对URI进行重构
ClientHttpRequest delegate = requestFactory.createRequest(request.getURI(), method);
request.getHeaders().forEach((key, value) -> delegate.getHeaders().addAll(key, value));
if (body.length > 0) {
if (delegate instanceof StreamingHttpOutputMessage) {
StreamingHttpOutputMessage streamingOutputMessage = (StreamingHttpOutputMessage) delegate;
streamingOutputMessage.setBody(outputStream -> StreamUtils.copy(body, outputStream));
}
else {
StreamUtils.copy(body, delegate.getBody());
}
}
return delegate.execute();
}
}
}
这一次,iterator.hasNext()就是false了,并没有其他拦截器了,而创建出来的ClientHttpRequest 就是一个HttpComponentsClientHttpRequest,url也是正常的url没有携带服务名,直接通过http的工具包发出http请求了。

七、源码分析-服务列表是如何获取的
上面分析到,Ribbon内置有多种Rule。我们以PredicateBasedRule为例,进行解析,PredicateBasedRule就用于做轮询。
public abstract class PredicateBasedRule extends ClientConfigEnabledRoundRobinRule {
public abstract AbstractServerPredicate getPredicate();
@Override
public Server choose(Object key) {
ILoadBalancer lb = getLoadBalancer();
// lb.getAllServers() 获取所有的Server
Optional<Server> server = getPredicate().chooseRoundRobinAfterFiltering(lb.getAllServers(), key);
if (server.isPresent()) {
return server.get();
} else {
return null;
}
}
}
// com.netflix.loadbalancer.AbstractServerPredicate#chooseRoundRobinAfterFiltering(java.util.List, java.lang.Object)
public Optional<Server> chooseRoundRobinAfterFiltering(List<Server> servers, Object loadBalancerKey) {
List<Server> eligible = getEligibleServers(servers, loadBalancerKey);
if (eligible.size() == 0) {
return Optional.absent();
}
// 循环不断的做++操作
return Optional.of(eligible.get(incrementAndGetModulo(eligible.size())));
}
1、lb.getAllServers()
我们看lb.getAllServers()的逻辑,其中的allServerList就是所有的Server列表,以下代码都是在BaseLoadBalancer维护的:
// com.netflix.loadbalancer.BaseLoadBalancer#getAllServers
@Override
public List<Server> getAllServers() {
return Collections.unmodifiableList(allServerList);
}
// 服务端地址列表在客户端的缓存
private static final String PREFIX = "LoadBalancer_";
@Monitor(name = PREFIX + "AllServerList", type = DataSourceType.INFORMATIONAL)
protected volatile List<Server> allServerList = Collections
.synchronizedList(new ArrayList<Server>());
@Monitor(name = PREFIX + "UpServerList", type = DataSourceType.INFORMATIONAL)
protected volatile List<Server> upServerList = Collections
.synchronizedList(new ArrayList<Server>());
那么问题来了,这些服务列表是如何进行加载的呢?
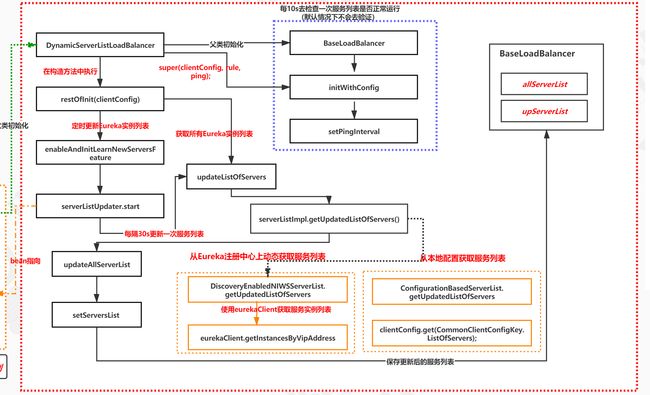
2、DynamicServerListLoadBalancer的初始化
DynamicServerListLoadBalancer是ZoneAwareLoadBalancer的父类,其构造方法中调用了restOfInit方法:
// com.netflix.loadbalancer.DynamicServerListLoadBalancer#DynamicServerListLoadBalancer(com.netflix.client.config.IClientConfig, com.netflix.loadbalancer.IRule, com.netflix.loadbalancer.IPing, com.netflix.loadbalancer.ServerList, com.netflix.loadbalancer.ServerListFilter, com.netflix.loadbalancer.ServerListUpdater)
public DynamicServerListLoadBalancer(IClientConfig clientConfig, IRule rule, IPing ping,
ServerList<T> serverList, ServerListFilter<T> filter,
ServerListUpdater serverListUpdater) {
super(clientConfig, rule, ping);
this.serverListImpl = serverList;
this.filter = filter;
this.serverListUpdater = serverListUpdater;
if (filter instanceof AbstractServerListFilter) {
((AbstractServerListFilter) filter).setLoadBalancerStats(getLoadBalancerStats());
}
restOfInit(clientConfig);
}
// com.netflix.loadbalancer.DynamicServerListLoadBalancer#restOfInit
void restOfInit(IClientConfig clientConfig) {
boolean primeConnection = this.isEnablePrimingConnections();
// turn this off to avoid duplicated asynchronous priming done in BaseLoadBalancer.setServerList()
this.setEnablePrimingConnections(false);
// 定时任务不断的刷新任务列表
enableAndInitLearnNewServersFeature();
// 更新Servers
updateListOfServers();
if (primeConnection && this.getPrimeConnections() != null) {
this.getPrimeConnections()
.primeConnections(getReachableServers());
}
this.setEnablePrimingConnections(primeConnection);
LOGGER.info("DynamicServerListLoadBalancer for client {} initialized: {}", clientConfig.getClientName(), this.toString());
}
3、定时更新Server列表——enableAndInitLearnNewServersFeature
开启定时任务,默认为每30秒更新一次服务列表
protected final ServerListUpdater.UpdateAction updateAction = new ServerListUpdater.UpdateAction() {
@Override
public void doUpdate() {
updateListOfServers();
}
};
// com.netflix.loadbalancer.DynamicServerListLoadBalancer#enableAndInitLearnNewServersFeature
public void enableAndInitLearnNewServersFeature() {
LOGGER.info("Using serverListUpdater {}", serverListUpdater.getClass().getSimpleName());
serverListUpdater.start(updateAction);
}
开启定时任务,最终调用updateAction的doUpdate方法,而doUpdate方法会执行updateListOfServers方法。
// com.netflix.loadbalancer.PollingServerListUpdater#start
@Override
public synchronized void start(final UpdateAction updateAction) {
if (isActive.compareAndSet(false, true)) {
final Runnable wrapperRunnable = new Runnable() {
@Override
public void run() {
if (!isActive.get()) {
if (scheduledFuture != null) {
scheduledFuture.cancel(true);
}
return;
}
try {
updateAction.doUpdate();
lastUpdated = System.currentTimeMillis();
} catch (Exception e) {
logger.warn("Failed one update cycle", e);
}
}
};
scheduledFuture = getRefreshExecutor().scheduleWithFixedDelay(
wrapperRunnable,
initialDelayMs, // 可配置的
refreshIntervalMs,
TimeUnit.MILLISECONDS
);
} else {
logger.info("Already active, no-op");
}
}
(1)PollingServerListUpdater的初始化
在RibbonClientConfiguration配置类中,对PollingServerListUpdater进行了初始化,并传入了配置:
@Bean
@ConditionalOnMissingBean
public ServerListUpdater ribbonServerListUpdater(IClientConfig config) {
return new PollingServerListUpdater(config);
}
而IClientConfig 同样也是在RibbonClientConfiguration配置类中初始化的。
@Bean
@ConditionalOnMissingBean
public IClientConfig ribbonClientConfig() {
DefaultClientConfigImpl config = new DefaultClientConfigImpl();
// name = "client"
config.loadProperties(this.name);
config.set(CommonClientConfigKey.ConnectTimeout, DEFAULT_CONNECT_TIMEOUT); // 1000
config.set(CommonClientConfigKey.ReadTimeout, DEFAULT_READ_TIMEOUT); // 1000
config.set(CommonClientConfigKey.GZipPayload, DEFAULT_GZIP_PAYLOAD); // true
return config;
}
而PollingServerListUpdater有两个,构造方法,其中一个会做一些配置初始化操作
public PollingServerListUpdater(IClientConfig clientConfig) {
// getRefreshIntervalMs初始化定时任务的延迟时间
this(LISTOFSERVERS_CACHE_UPDATE_DELAY, getRefreshIntervalMs(clientConfig));
}
public PollingServerListUpdater(final long initialDelayMs, final long refreshIntervalMs) {
this.initialDelayMs = initialDelayMs;
this.refreshIntervalMs = refreshIntervalMs;
}
// com.netflix.loadbalancer.PollingServerListUpdater#getRefreshIntervalMs
private static long getRefreshIntervalMs(IClientConfig clientConfig) {
//LISTOFSERVERS_CACHE_REPEAT_INTERVAL = 30 * 1000 ms,也就是默认为30秒
return clientConfig.get(CommonClientConfigKey.ServerListRefreshInterval, LISTOFSERVERS_CACHE_REPEAT_INTERVAL);
}
4、updateListOfServers
updateListOfServers是更新Server列表的动作。
// com.netflix.loadbalancer.DynamicServerListLoadBalancer#updateListOfServers
@VisibleForTesting
public void updateListOfServers() {
List<T> servers = new ArrayList<T>();
if (serverListImpl != null) {
// 获取Server列表
servers = serverListImpl.getUpdatedListOfServers();
LOGGER.debug("List of Servers for {} obtained from Discovery client: {}",
getIdentifier(), servers);
if (filter != null) {
servers = filter.getFilteredListOfServers(servers);
LOGGER.debug("Filtered List of Servers for {} obtained from Discovery client: {}",
getIdentifier(), servers);
}
}
// 更新AllServerList
updateAllServerList(servers);
}
其中,getUpdatedListOfServers方法有诸多实现类,如果添加Eureka就会有Eureka实现类,默认有ConfigurationBasedServerList、StaticServerList。我们以ConfigurationBasedServerList为例进行分析,顾名思义就是从配置文件中获取Server列表。
// com.netflix.loadbalancer.ConfigurationBasedServerList#getUpdatedListOfServers
@Override
public List<Server> getUpdatedListOfServers() {
// 从listOfServers配置中获取 这里获取的就是localhost:8080,localhost:8082
String listOfServers = clientConfig.get(CommonClientConfigKey.ListOfServers);
// 生成server,多个server用逗号分隔
return derive(listOfServers);
}
// com.netflix.loadbalancer.ConfigurationBasedServerList#derive
protected List<Server> derive(String value) {
List<Server> list = Lists.newArrayList();
if (!Strings.isNullOrEmpty(value)) {
for (String s: value.split(",")) {
list.add(new Server(s.trim()));
}
}
return list;
}
此时拿到了Server的列表,接下来就需要将Server的列表,赋值到我们上面分析到的,allServerList 缓存中了。
(1)updateAllServerList
// com.netflix.loadbalancer.DynamicServerListLoadBalancer#updateAllServerList
protected void updateAllServerList(List<T> ls) {
// other threads might be doing this - in which case, we pass
// 乐观锁,保证安全
if (serverListUpdateInProgress.compareAndSet(false, true)) {
try {
for (T s : ls) {
s.setAlive(true); // set so that clients can start using these
// servers right away instead
// of having to wait out the ping cycle.
}
// 设置allServerList
setServersList(ls);
// 设置一个Pinger,不断的ping服务,如果服务不可用,直接剔除掉
super.forceQuickPing();
} finally {
serverListUpdateInProgress.set(false);
}
}
}
该方法中,就是往allServerList 中设置Server列表了,具体源码比较长就不贴在这了。
(2)实现一个Pinger
默认是每10秒钟ping一次,如果服务不可用直接剔除。
// com.netflix.loadbalancer.BaseLoadBalancer#forceQuickPing
public void forceQuickPing() {
if (canSkipPing()) {
return;
}
logger.debug("LoadBalancer [{}]: forceQuickPing invoking", name);
try {
// 策略模式
new Pinger(pingStrategy).runPinger();
} catch (Exception e) {
logger.error("LoadBalancer [{}]: Error running forceQuickPing()", name, e);
}
}
最终,会调用ping的isAlive方法判断该Server是不是存活,如果不存活了就剔除,我们看其中一个实现,里面其实就是发了一个http请求,判断响应码。同样的,我们也可以自定义一个Ping的实现:
// com.netflix.loadbalancer.PingUrl#isAlive
public boolean isAlive(Server server) {
String urlStr = "";
if (isSecure){
urlStr = "https://";
}else{
urlStr = "http://";
}
urlStr += server.getId();
urlStr += getPingAppendString();
boolean isAlive = false;
HttpClient httpClient = new DefaultHttpClient();
HttpUriRequest getRequest = new HttpGet(urlStr);
String content=null;
try {
HttpResponse response = httpClient.execute(getRequest);
content = EntityUtils.toString(response.getEntity());
isAlive = (response.getStatusLine().getStatusCode() == 200);
if (getExpectedContent()!=null){
LOGGER.debug("content:" + content);
if (content == null){
isAlive = false;
}else{
if (content.equals(getExpectedContent())){
isAlive = true;
}else{
isAlive = false;
}
}
}
} catch (IOException e) {
e.printStackTrace();
}finally{
// Release the connection.
getRequest.abort();
}
return isAlive;
}
(3)自定义一个Ping
public class MyPing implements IPing{
@Override
public boolean isAlive(Server server) {
System.out.println("isAlive"+server.getHost()+":"+server.getPort());
return true;
}
}
// #配置IPing的实现类
spring-cloud-order-service.ribbon.NFLoadBalancerPingClassName=com.example.springclouduserservice.MyPing
// #配置Ping操作的间隔
spring-cloud-order-service.ribbon.NFLoadBalancerPingInterval=2
5、小总结
大致上,Ribbon会一开始初始化服务列表(从本地配置或者注册中心中获取)到本地缓存,而且会默认每隔30秒重新获取,并且还会默认每隔10秒主动的ping一下服务是否可用。
八、源码分析-Ribbon负载均衡策略
我们上面也分析到,rule就是可以选择的负载均衡规则,通过调用Rule的rule.choose(key)方法,来进行Server的选择:
默认就是轮询算法。
1、默认PredicateBasedRule——轮询算法
// com.netflix.loadbalancer.PredicateBasedRule#choose
@Override
public Server choose(Object key) {
ILoadBalancer lb = getLoadBalancer();
// chooseRoundRobinAfterFiltering是父类的方法,通过轮询方式选择服务器
Optional<Server> server = getPredicate().chooseRoundRobinAfterFiltering(lb.getAllServers(), key);
if (server.isPresent()) {
return server.get();
} else {
return null;
}
}
// com.netflix.loadbalancer.AbstractServerPredicate#chooseRoundRobinAfterFiltering(java.util.List, java.lang.Object)
public Optional<Server> chooseRoundRobinAfterFiltering(List<Server> servers, Object loadBalancerKey) {
List<Server> eligible = getEligibleServers(servers, loadBalancerKey);
if (eligible.size() == 0) {
return Optional.absent();
}
return Optional.of(eligible.get(incrementAndGetModulo(eligible.size())));
}
// com.netflix.loadbalancer.AbstractServerPredicate#incrementAndGetModulo
private int incrementAndGetModulo(int modulo) {
for (;;) {
int current = nextIndex.get();
int next = (current + 1) % modulo;
if (nextIndex.compareAndSet(current, next) && current < modulo)
return current;
}
}
每次选择服务器的时候,会进行++操作,通过轮询的方式选择服务器,而这个算法是在父类中实现的,默认就是使用轮询算法。
2、RetryRule——重试算法
public Server choose(ILoadBalancer lb, Object key) {
long requestTime = System.currentTimeMillis();
long deadline = requestTime + maxRetryMillis;
Server answer = null;
answer = subRule.choose(key);
if (((answer == null) || (!answer.isAlive()))
&& (System.currentTimeMillis() < deadline)) {
InterruptTask task = new InterruptTask(deadline
- System.currentTimeMillis());
// 循环,如果subRule.choose(key)的结果为null的时候,会再次发起重试
while (!Thread.interrupted()) {
answer = subRule.choose(key);
if (((answer == null) || (!answer.isAlive()))
&& (System.currentTimeMillis() < deadline)) {
/* pause and retry hoping it's transient */
Thread.yield();
} else {
break;
}
}
task.cancel();
}
if ((answer == null) || (!answer.isAlive())) {
return null;
} else {
return answer;
}
}
@Override
public Server choose(Object key) {
return choose(getLoadBalancer(), key);
}
3、WeightedResponseTimeRule——响应时间权重算法
每次调用接口时,会通过LoadBalancerStats进行响应时间的缓存,然后WeightedResponseTimeRule中有一个内部类,会定时的计算权重。
// com.netflix.loadbalancer.WeightedResponseTimeRule.DynamicServerWeightTask
class DynamicServerWeightTask extends TimerTask {
public void run() {
ServerWeight serverWeight = new ServerWeight();
try {
serverWeight.maintainWeights();
} catch (Exception e) {
logger.error("Error running DynamicServerWeightTask for {}", name, e);
}
}
}
这里的响应时间权重算法是大致是这样的:
假设:A服务器响应时间为10,B服务器响应时间为20,C服务器响应时间为30,D服务器响应时间为40。我们计算A+B+C+D=150。
这样,分别计算ABCD四个服务器的区间算法:
A = 0 , (150-10) = [0,140]
B = 140 ,(140+(150-20))= 270 = (140,270]
C =270 ,(270+(150-30))= (270,390]
D = 390 , (390 + (150 - 40)) = (390 , 500]
这样的话,我每次从0到500随机生成一个数字,生成的数字落在哪一个区间上,就发送到哪个服务器上。
4、自定义Bibbon负载均衡策略
public class IpHashRule extends AbstractLoadBalancerRule{
@Override
public void initWithNiwsConfig(IClientConfig iClientConfig) {
// 初始化配置
}
public Server choose(ILoadBalancer lb,Object key){
if (lb == null) {
return null;
}
Server server = null;
while(server==null){
// 获取Server列表
List<Server> allList=lb.getAllServers();
System.out.println(allList);
// TODO 使用自定义算法来获取Server
int index=0;
server=allList.get(index);
}
return server;
}
@Override
public Server choose(Object key) {
return choose(getLoadBalancer(),key);
}
}
# 配置指定负载均衡规则
spring-cloud-order-service.ribbon.NFLoadBalancerRuleClassName=com.example.springclouduserservice.GpDefineIpHashRule