CMU-Multimodal SDK Version 1.2.0(mmsdk)Windows配置与使用+pytorch代码demo
最近做实验要用到CMU-MOSI数据集,网上搜到的教程很少,经过一天时间的探索,最终成功安装配置数据集,这篇文章完整地整理一下该数据集的下载与使用方法。
配置环境:
window10,anaconda
1. 需要下载的内容
步骤1:下载官方github的SDK包:CMU-MultiComp-Lab/CMU-MultimodalSDK (github.com)
步骤2:解压的路径需要保存
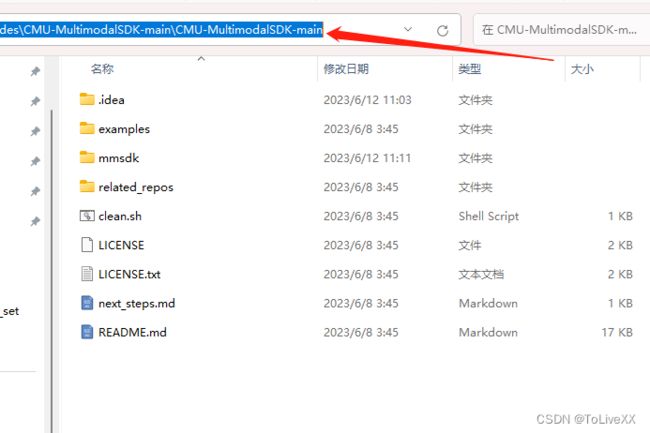
2.anaconda环境配置
官方github的readme中写了需要配置环境,但该命令是基于linux系统,windows系统需要按照以下步骤设置。
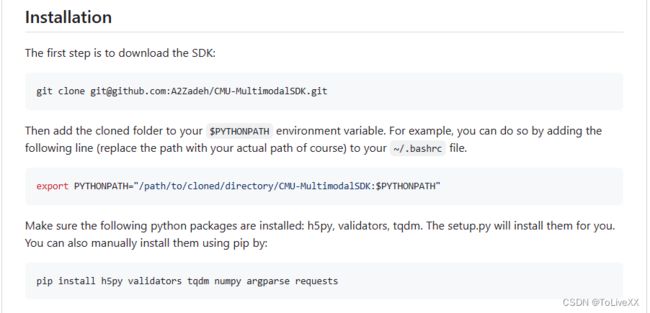
步骤1:在anaconda的虚拟环境 路径下的Lib\site-packages,创建一个文本文档,命名为’mypkpath‘,在该文档中添加上一步的SDK路径,保存之后将文件后缀改为“pth”。

步骤2:用下面的命令安装mmsdk的依赖包:
pip install h5py validators tqdm numpy argparse requests步骤3:因为win10和Linux的文件路径分隔符不同,所以这里要修改mmsdk里的文件:
修改文件1:路径如下:
****CMU-MultimodalSDK-main\mmsdk\mmdatasdk\computational_sequence\download_ops.py在文档最后修改为:(read和URL中间加一个'_')

修改文件2:和上一个文件同级的不同文件:computational_sequence.py
****CMU-MultimodalSDK-main\mmsdk\mmdatasdk\computational_sequence\computational_sequence.py文档第68行左右,把分隔符从'os.sep'改为'/':

步骤4:启动conda的虚拟环境,导入mmsdk包验证是否安装成功,没报错就安装成功
from mmsdk import mmdatasdk as md3. 下载数据集
步骤一:下载数据集,DATA_PATH是将下载的csd文件存放的目录,
from mmsdk import mmdatasdk as md
DATASET = md.cmu_mosi
DATA_PATH = './data'
try:
md.mmdataset(DATASET.highlevel,DATA_PATH)
except:
print('have been downloaded')步骤2:加载csd文件并对齐
from mmsdk import mmdatasdk as md
DATASET = md.cmu_mosi
DATA_PATH = './data'
data_files = os.listdir(DATA_PATH)
print('\n'.join(data_files))
visual_field = 'CMU_MOSI_Visual_Facet_41'
acoustic_field = 'CMU_MOSI_COVAREP'
text_field = 'CMU_MOSI_ModifiedTimestampedWords'
features = [
text_field,
visual_field,
acoustic_field
]
recipe = {feat: os.path.join(DATA_PATH, feat) + '.csd' for feat in features}
dataset = md.mmdataset(recipe)
print(list(dataset[text_field].keys())[55])
print('done!')步骤3:对齐csd文件并保存对齐之后的结果。保存的csd文件会存储到'./deployed'文件夹中,下一次使用数据时直接从deployed文件中加载数据就ok,这样就不用重复下载和对齐。
def avg(intervals: np.array, features: np.array) -> np.array:
try:
return np.average(features, axis=0)
except:
return features
# first we align to words with averaging, collapse_function receives a list of functions
dataset.align(text_field, collapse_functions=[avg])
label_field = 'CMU_MOSI_Opinion_Labels'
# we add and align to lables to obtain labeled segments
# this time we don't apply collapse functions so that the temporal sequences are preserved
label_recipe = {label_field: os.path.join(DATA_PATH, label_field + '.csd')}
dataset.add_computational_sequences(label_recipe, destination=None)
dataset.align(label_field, replace=True)
print(list(dataset[text_field].keys())[55])
print('done!')
###保存
deploy_files={x:x for x in dataset.computational_sequences.keys()}
dataset.deploy("./deployed",deploy_files)
aligned_cmumosi_highlevel=md.mmdataset('./deployed')4. 一次小小的完整训练
from mmsdk import mmdatasdk
import os, re
import numpy as np
from torch.utils.data import DataLoader
from collections import defaultdict
import torch
import torch.nn as nn
from tqdm import tqdm_notebook
from torch.optim import Adam, SGD
from sklearn.metrics import accuracy_score
import torch, os
from torch.nn.utils.rnn import pad_sequence, pack_padded_sequence, pad_packed_sequence
from torch.utils.data import DataLoader, Dataset
from tqdm import tqdm_notebook
word2id = defaultdict(lambda: len(word2id))
UNK = word2id['']
PAD = word2id['']
# def return_unk():
# return UNK
# word2id.default_factory = return_unk
def splittraindevtest(train_split, dev_split, test_split, dataset, features):
EPS = 0
text_field, visual_field, acoustic_field, label_field = features
# construct a word2id mapping that automatically takes increment when new words are encountered
# place holders for the final train/dev/test dataset
train = []
dev = []
test = []
# define a regular expression to extract the video ID out of the keys
pattern = re.compile('(.*)\[.*\]')
num_drop = 0 # a counter to count how many data points went into some processing issues
for segment in dataset[label_field].keys():
# get the video ID and the features out of the aligned dataset
vid = re.search(pattern, segment).group(1)
label = dataset[label_field][segment]['features']
_words = dataset[text_field][segment]['features']
_visual = dataset[visual_field][segment]['features']
_acoustic = dataset[acoustic_field][segment]['features']
# if the sequences are not same length after alignment, there must be some problem with some modalities
# we should drop it or inspect the data again
if not _words.shape[0] == _visual.shape[0] == _acoustic.shape[0]:
print(
f"Encountered datapoint {vid} with text shape {_words.shape}, visual shape {_visual.shape}, acoustic shape {_acoustic.shape}")
num_drop += 1
continue
# remove nan values
label = np.nan_to_num(label)
_visual = np.nan_to_num(_visual)
_acoustic = np.nan_to_num(_acoustic)
# remove speech pause tokens - this is in general helpful
# we should remove speech pauses and corresponding visual/acoustic features together
# otherwise modalities would no longer be aligned
words = []
visual = []
acoustic = []
for i, word in enumerate(_words):
if word[0] != b'sp':
words.append(word2id[word[0].decode('utf-8')]) # SDK stores strings as bytes, decode into strings here
visual.append(_visual[i, :])
acoustic.append(_acoustic[i, :])
words = np.asarray(words)
visual = np.asarray(visual)
acoustic = np.asarray(acoustic)
# z-normalization per instance and remove nan/infs
visual = np.nan_to_num((visual - visual.mean(0, keepdims=True)) / (EPS + np.std(visual, axis=0, keepdims=True)))
acoustic = np.nan_to_num(
(acoustic - acoustic.mean(0, keepdims=True)) / (EPS + np.std(acoustic, axis=0, keepdims=True)))
if vid in train_split:
train.append(((words, visual, acoustic), label, segment))
elif vid in dev_split:
dev.append(((words, visual, acoustic), label, segment))
elif vid in test_split:
test.append(((words, visual, acoustic), label, segment))
else:
print(f"Found video that doesn't belong to any splits: {vid}")
def return_unk():
return UNK
word2id.default_factory = return_unk
print(f"Total number of {num_drop} datapoints have been dropped.")
return train, dev, test
def multi_collate(batch):
'''
Collate functions assume batch = [Dataset[i] for i in index_set]
'''
# for later use we sort the batch in descending order of length
batch = sorted(batch, key=lambda x: x[0][0].shape[0], reverse=True)
# get the data out of the batch - use pad sequence util functions from PyTorch to pad things
labels = torch.cat([torch.from_numpy(sample[1]) for sample in batch], dim=0)
sentences = pad_sequence([torch.LongTensor(sample[0][0]) for sample in batch], padding_value=PAD)
visual = pad_sequence([torch.FloatTensor(sample[0][1]) for sample in batch])
acoustic = pad_sequence([torch.FloatTensor(sample[0][2]) for sample in batch])
# lengths are useful later in using RNNs
lengths = torch.LongTensor([sample[0][0].shape[0] for sample in batch])
return sentences, visual, acoustic, labels, lengths
class LFLSTM(nn.Module):
def __init__(self, input_sizes, hidden_sizes, fc1_size, output_size, dropout_rate):
super(LFLSTM, self).__init__()
self.input_size = input_sizes
self.hidden_size = hidden_sizes
self.fc1_size = fc1_size
self.output_size = output_size
self.dropout_rate = dropout_rate
# defining modules - two layer bidirectional LSTM with layer norm in between
self.embed = nn.Embedding(len(word2id), input_sizes[0])
self.trnn1 = nn.LSTM(input_sizes[0], hidden_sizes[0], bidirectional=True)
self.trnn2 = nn.LSTM(2 * hidden_sizes[0], hidden_sizes[0], bidirectional=True)
self.vrnn1 = nn.LSTM(input_sizes[1], hidden_sizes[1], bidirectional=True)
self.vrnn2 = nn.LSTM(2 * hidden_sizes[1], hidden_sizes[1], bidirectional=True)
self.arnn1 = nn.LSTM(input_sizes[2], hidden_sizes[2], bidirectional=True)
self.arnn2 = nn.LSTM(2 * hidden_sizes[2], hidden_sizes[2], bidirectional=True)
self.fc1 = nn.Linear(sum(hidden_sizes) * 4, fc1_size)
self.fc2 = nn.Linear(fc1_size, output_size)
self.relu = nn.ReLU()
self.dropout = nn.Dropout(dropout_rate)
self.tlayer_norm = nn.LayerNorm((hidden_sizes[0] * 2,))
self.vlayer_norm = nn.LayerNorm((hidden_sizes[1] * 2,))
self.alayer_norm = nn.LayerNorm((hidden_sizes[2] * 2,))
self.bn = nn.BatchNorm1d(sum(hidden_sizes) * 4)
def extract_features(self, sequence, lengths, rnn1, rnn2, layer_norm):
packed_sequence = pack_padded_sequence(sequence, lengths.cpu())
packed_h1, (final_h1, _) = rnn1(packed_sequence)
padded_h1, _ = pad_packed_sequence(packed_h1)
normed_h1 = layer_norm(padded_h1)
packed_normed_h1 = pack_padded_sequence(normed_h1, lengths.cpu())
_, (final_h2, _) = rnn2(packed_normed_h1)
return final_h1, final_h2
def fusion(self, sentences, visual, acoustic, lengths):
batch_size = lengths.size(0)
sentences = self.embed(sentences)
# extract features from text modality
final_h1t, final_h2t = self.extract_features(sentences, lengths, self.trnn1, self.trnn2, self.tlayer_norm)
# extract features from visual modality
final_h1v, final_h2v = self.extract_features(visual, lengths, self.vrnn1, self.vrnn2, self.vlayer_norm)
# extract features from acoustic modality
final_h1a, final_h2a = self.extract_features(acoustic, lengths, self.arnn1, self.arnn2, self.alayer_norm)
# simple late fusion -- concatenation + normalization
h = torch.cat((final_h1t, final_h2t, final_h1v, final_h2v, final_h1a, final_h2a),
dim=2).permute(1, 0, 2).contiguous().view(batch_size, -1)
return self.bn(h)
def forward(self, sentences, visual, acoustic, lengths):
batch_size = lengths.size(0)
h = self.fusion(sentences, visual, acoustic, lengths)
h = self.fc1(h)
h = self.dropout(h)
h = self.relu(h)
o = self.fc2(h)
return o
def load_emb(w2i, path_to_embedding, embedding_size=300, embedding_vocab=2196017, init_emb=None):
if init_emb is None:
emb_mat = np.random.randn(len(w2i), embedding_size)
else:
emb_mat = init_emb
f = open(path_to_embedding, 'r')
found = 0
for line in tqdm_notebook(f, total=embedding_vocab):
content = line.strip().split()
vector = np.asarray(list(map(lambda x: float(x), content[-300:])))
word = ' '.join(content[:-300])
if word in w2i:
idx = w2i[word]
emb_mat[idx, :] = vector
found += 1
print(f"Found {found} words in the embedding file.")
return torch.tensor(emb_mat).float()
def run(train_loader, dev_loader, test_loader):
torch.manual_seed(123)
torch.cuda.manual_seed_all(123)
CUDA = True # torch.cuda.is_available()
MAX_EPOCH = 5
text_size = 300
visual_size = 47
acoustic_size = 74
# define some model settings and hyper-parameters
input_sizes = [text_size, visual_size, acoustic_size]
hidden_sizes = [int(text_size * 1.5), int(visual_size * 1.5), int(acoustic_size * 1.5)]
fc1_size = sum(hidden_sizes) // 2
dropout = 0.25
output_size = 1
curr_patience = patience = 8
num_trials = 3
grad_clip_value = 1.0
weight_decay = 0.1
CACHE_PATH = r'D:\Speech\jupyter_notes_zyx\CMU-MultimodalSDK-Tutorials-master\CMU-MultimodalSDK-Tutorials-master\data\embedding_and_mapping.pt'
if os.path.exists(CACHE_PATH):
pretrained_emb, word2id = torch.load(CACHE_PATH)
else:
pretrained_emb = None
model = LFLSTM(input_sizes, hidden_sizes, fc1_size, output_size, dropout)
if pretrained_emb is not None:
model.embed.weight.data = pretrained_emb
model.embed.requires_grad = False
optimizer = Adam([param for param in model.parameters() if param.requires_grad], weight_decay=weight_decay)
if CUDA:
model.cuda()
criterion = nn.L1Loss(reduction='sum')
criterion_test = nn.L1Loss(reduction='sum')
best_valid_loss = float('inf')
lr_scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=1, gamma=0.1)
lr_scheduler.step() # for some reason it seems the StepLR needs to be stepped once first
train_losses = []
valid_losses = []
for e in range(MAX_EPOCH):
model.train()
train_iter = tqdm_notebook(train_loader)
train_loss = 0.0
for batch in train_iter:
model.zero_grad()
t, v, a, y, l = batch
batch_size = t.size(0)
if CUDA:
t = t.cuda()
v = v.cuda()
a = a.cuda()
y = y.cuda()
l = l.cuda()
y_tilde = model(t, v, a, l)
loss = criterion(y_tilde, y)
loss.backward()
torch.nn.utils.clip_grad_value_([param for param in model.parameters() if param.requires_grad], grad_clip_value)
optimizer.step()
train_iter.set_description(f"Epoch {e}/{MAX_EPOCH}, current batch loss: {round(loss.item() / batch_size, 4)}")
train_loss += loss.item()
train_loss = train_loss / len(train)
train_losses.append(train_loss)
print(f"Training loss: {round(train_loss, 4)}")
model.eval()
with torch.no_grad():
valid_loss = 0.0
for batch in dev_loader:
model.zero_grad()
t, v, a, y, l = batch
if CUDA:
t = t.cuda()
v = v.cuda()
a = a.cuda()
y = y.cuda()
l = l.cuda()
y_tilde = model(t, v, a, l)
loss = criterion(y_tilde, y)
valid_loss += loss.item()
valid_loss = valid_loss / len(dev)
valid_losses.append(valid_loss)
print(f"Validation loss: {round(valid_loss, 4)}")
print(f"Current patience: {curr_patience}, current trial: {num_trials}.")
if valid_loss <= best_valid_loss:
best_valid_loss = valid_loss
print("Found new best model on dev set!")
torch.save(model.state_dict(), 'model.std')
torch.save(optimizer.state_dict(), 'optim.std')
curr_patience = patience
else:
curr_patience -= 1
if curr_patience <= -1:
print("Running out of patience, loading previous best model.")
num_trials -= 1
curr_patience = patience
model.load_state_dict(torch.load('model.std'))
optimizer.load_state_dict(torch.load('optim.std'))
lr_scheduler.step()
print(f"Current learning rate: {optimizer.state_dict()['param_groups'][0]['lr']}")
if num_trials <= 0:
print("Running out of patience, early stopping.")
break
model.load_state_dict(torch.load('model.std'))
y_true = []
y_pred = []
model.eval()
with torch.no_grad():
test_loss = 0.0
for batch in test_loader:
model.zero_grad()
t, v, a, y, l = batch
if CUDA:
t = t.cuda()
v = v.cuda()
a = a.cuda()
y = y.cuda()
l = l.cuda()
y_tilde = model(t, v, a, l)
loss = criterion_test(y_tilde, y)
y_true.append(y_tilde.detach().cpu().numpy())
y_pred.append(y.detach().cpu().numpy())
test_loss += loss.item()
print(f"Test set performance: {test_loss / len(test)}")
y_true = np.concatenate(y_true, axis=0)
y_pred = np.concatenate(y_pred, axis=0)
y_true_bin = y_true >= 0
y_pred_bin = y_pred >= 0
bin_acc = accuracy_score(y_true_bin, y_pred_bin)
print(f"Test set accuracy is {bin_acc}")
if __name__=='__main__':
visual_field1 = 'CMU_MOSI_Visual_Facet_41'
acoustic_field1 = 'CMU_MOSI_COVAREP'
text_field1 = 'CMU_MOSI_ModifiedTimestampedWords'
label_field1 = 'CMU_MOSI_Opinion_Labels'
features1 = [
text_field1,
visual_field1,
acoustic_field1,
label_field1
]
DATA_PATH1 = './mymydeployed'
recipe1 = {feat: os.path.join(DATA_PATH1, feat) + '.csd' for feat in features1}
dataset1 = mmdatasdk.mmdataset(recipe1)
print(list(dataset1[text_field1].keys())[55])
tensors = dataset1.get_tensors(seq_len=25, non_sequences=["Opinion Segment Labels"], direction=False,
folds=[mmdatasdk.cmu_mosi.standard_folds.standard_train_fold, mmdatasdk.cmu_mosi.
standard_folds.standard_valid_fold,
mmdatasdk.cmu_mosi.standard_folds.standard_test_fold])
fold_names = ["train", "valid", "test"]
train, dev, test = splittraindevtest(mmdatasdk.cmu_mosi.standard_folds.standard_train_fold, mmdatasdk.cmu_mosi.
standard_folds.standard_valid_fold, mmdatasdk.cmu_mosi.standard_folds.standard_test_fold,
dataset1, features1)
batch_sz = 56
train_loader = DataLoader(train, shuffle=True, batch_size=batch_sz, collate_fn=multi_collate)
dev_loader = DataLoader(dev, shuffle=False, batch_size=batch_sz * 3, collate_fn=multi_collate)
test_loader = DataLoader(test, shuffle=False, batch_size=batch_sz * 3, collate_fn=multi_collate)
run(train_loader, dev_loader, test_loader)