数据库SQL实战
这里写目录标题
- SQL1 查找最晚入职员工的所有信息
-
- 题目
- 解法
- SQL2 查找最晚入职员工的所有信息
-
- 题目
- 解法
- SQL3 查找最晚入职员工的所有信息
-
- 题目
- 解法
- SQL4 查找所有已经分配部门的员工的last_name和first_name
-
- 题目
- 解法
- SQL5 查找所有员工的last_name和first_name以及对应部门编号dept_no
-
- 题目
- 解法
- SQL7 查找薪水涨幅超过15次的员工号emp_no以及其对应的涨幅次数t
-
- 题目
- 解法
- SQL8 找出所有员工当前具体的薪水salary情况
-
- 题目
- 解法
- SQL10 获取所有非manager的员工emp_no
-
- 题目
- 解法
- SQL11 获取所有员工当前的manager
-
- 题目
- 解法
- SQL12 获取所有部门中当前员工薪水最高的相关信息
-
- 题目
- 解法1
- SQL15 查找employees表所有emp_no为奇数
-
- 题目
- 解法1
- SQL16 统计出当前各个title类型对应的员工当前薪水对应的平均工资
-
- 题目
- 解法1
- SQL17 获取当前薪水第二多的员工的emp_no以及其对应的薪水salary
-
- 题目
- 解法1
- 解法2
- SQL18 查找当前薪水排名第二多的员工编号emp_no
-
- 解法1
- 解法2
SQL1 查找最晚入职员工的所有信息
题目
有一个员工employees表简况如下:

建表语句如下:
CREATE TABLE employees (
emp_no int(11) NOT NULL,
birth_date date NOT NULL,
first_name varchar(14) NOT NULL,
last_name varchar(16) NOT NULL,
gender char(1) NOT NULL,
hire_date date NOT NULL,
PRIMARY KEY (emp_no));
请你查找employees里最晚入职员工的所有信息,以上例子输出如下:

解法
# 使用limit关键字
SELECT * FROM employees ORDER BY hire_date DESC limit 1;
# 使用limit关键字
SELECT * FROM employees ORDER BY hire_date DESC limit 0,1;
# 使用limit和offset关键字
SELECT * FROM employees ORDER BY hire_date DESC limit 1 OFFSET 0;
# 使用子查询
SELECT * FROM employees WHERE hire_date = (SELECT MAX(hire_date) FROM employees);
SQL2 查找最晚入职员工的所有信息
题目
有一个员工employees表简况如下:
建表语句如下:
CREATE TABLE employees (
emp_no int(11) NOT NULL,
birth_date date NOT NULL,
first_name varchar(14) NOT NULL,
last_name varchar(16) NOT NULL,
gender char(1) NOT NULL,
hire_date date NOT NULL,
PRIMARY KEY (emp_no));
请你查找employees里最晚入职员工的所有信息,以上例子输出如下:
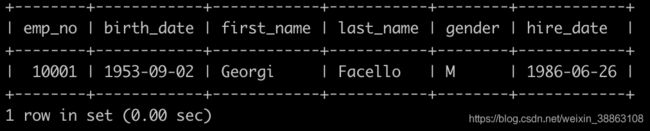
解法
# 由于入职时间相同的员工可能不止一人,所以入职时间排名倒数第三的员工的数目和排序位置都是未知的
# 使用子查询
SELECT *
FROM employees
WHERE hire_date = (
SELECT DISTINCT hire_date
FROM employees
ORDER BY hire_date DESC #从大到小排列
LIMIT 1 OFFSET 2 #只取倒数第三大的数字
);
SQL3 查找最晚入职员工的所有信息
题目
有一个全部员工的薪水表salaries简况如下:

有一个各个部门的领导表dept_manager简况如下:

建表语句如下:
CREATE TABLE salaries (
emp_no int(11) NOT NULL,
salary int(11) NOT NULL,
from_date date NOT NULL,
to_date date NOT NULL,
PRIMARY KEY (emp_no,from_date));
CREATE TABLE dept_manager (
dept_no char(4) NOT NULL,
emp_no int(11) NOT NULL,
to_date date NOT NULL,
PRIMARY KEY (emp_no,dept_no));
请你查找各个部门领导薪水详情以及其对应部门编号dept_no,输出结果以salaries.emp_no升序排序,并且请注意输出结果里面dept_no列是最后一列,以上例子输入如下:

解法
# 使用左外连接,on语句限定连接条件,查询按emp_no升序排列
select sa.emp_no,sa.salary,sa.from_date,sa.to_date,de.dept_no
from dept_manager de left join salaries sa
on de.emp_no=sa.emp_no
order by emp_no ASC
# 使用左内连接,on语句限定连接条件,查询按emp_no升序排列
select sa.emp_no,sa.salary,sa.from_date,sa.to_date,de.dept_no
from dept_manager de left join salaries sa
on de.emp_no=sa.emp_no
order by emp_no ASC
SQL4 查找所有已经分配部门的员工的last_name和first_name
题目
有一个员工表,employees简况如下:
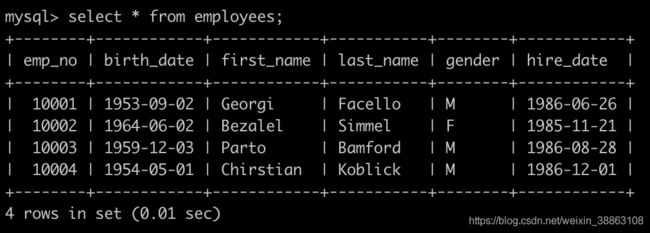
有一个部门表,dept_emp简况如下:
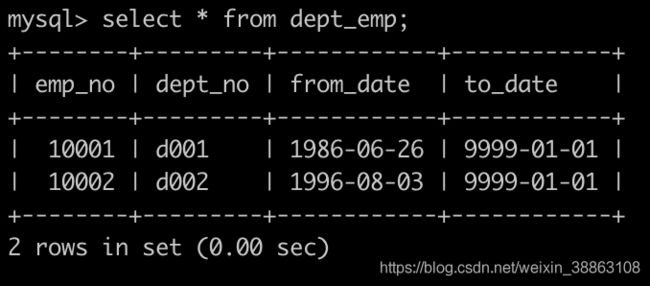
建表语句如下:
CREATE TABLE employees (
emp_no int(11) NOT NULL,
birth_date date NOT NULL,
first_name varchar(14) NOT NULL,
last_name varchar(16) NOT NULL,
gender char(1) NOT NULL,
hire_date date NOT NULL,
PRIMARY KEY (emp_no));
CREATE TABLE dept_emp (
emp_no int(11) NOT NULL,
dept_no char(4) NOT NULL,
from_date date NOT NULL,
to_date date NOT NULL,
PRIMARY KEY (emp_no,dept_no));
请你查找所有已经分配部门的员工的last_name和first_name以及dept_no,未分配的部门的员工不显示,以上例子如下:
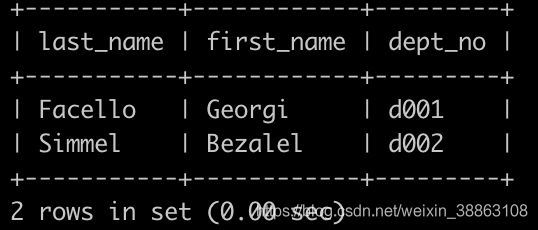
解法
# 左外连接进行查询
SELECT emp.last_name,emp.first_name,dept.dept_no
FROM dept_emp dept left join employees emp
ON dept.emp_no = emp.emp_no
SQL5 查找所有员工的last_name和first_name以及对应部门编号dept_no
题目
有一个员工表,employees简况如下:

有一个部门表,dept_emp简况如下:

建表语句如下:
CREATE TABLE employees (
emp_no int(11) NOT NULL,
birth_date date NOT NULL,
first_name varchar(14) NOT NULL,
last_name varchar(16) NOT NULL,
gender char(1) NOT NULL,
hire_date date NOT NULL,
PRIMARY KEY (emp_no));
CREATE TABLE dept_emp (
emp_no int(11) NOT NULL,
dept_no char(4) NOT NULL,
from_date date NOT NULL,
to_date date NOT NULL,
PRIMARY KEY (emp_no,dept_no));
请你查找所有已经分配部门的员工的last_name和first_name以及dept_no,也包括暂时没有分配具体部门的员工,以上例子如下:
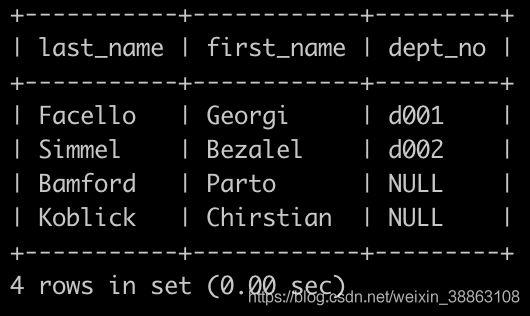
解法
# 使用左外连接合并表查询
SELECT emp.last_name,emp.first_name,dept.dept_no
FROM employees AS emp LEFT JOIN dept_emp AS dept
ON emp.emp_no = dept.emp_no
SQL7 查找薪水涨幅超过15次的员工号emp_no以及其对应的涨幅次数t
题目
有一个薪水表,salaries简况如下:
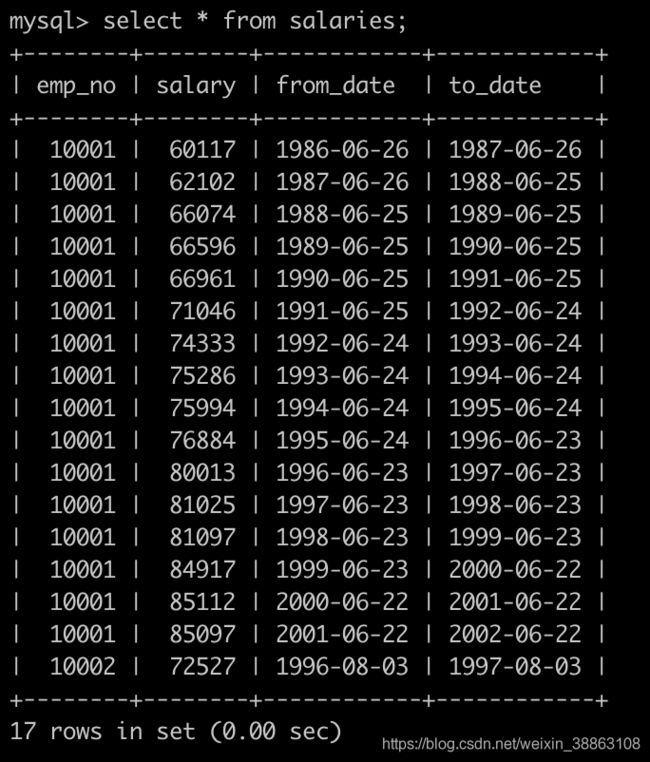
建表语句如下:
CREATE TABLE salaries (
emp_no int(11) NOT NULL,
salary int(11) NOT NULL,
from_date date NOT NULL,
to_date date NOT NULL,
PRIMARY KEY (emp_no,from_date));
请你查找薪水记录超过15次的员工号emp_no以及其对应的记录次数t,以上例子输出如下:

解法
# “Group By”从字面意义上理解就是根据“By”指定的规则对数据进行分组,
# 所谓的分组就是将一个“数据集”划分成若干个“小区域”,然后针对若干个“小区域”进行数据处理
# 使用GROUP BY进行分组查询
# 使用HAVING对能返回的结果集进行限制
# 使用COUNT()函数进行计数
SELECT emp_no, COUNT(DISTINCT from_date) AS t
FROM salaries
GROUP BY emp_no
HAVING t>15
SQL8 找出所有员工当前具体的薪水salary情况
题目
有一个薪水表,salaries简况如下:

建表语句如下:
CREATE TABLE salaries (
emp_no int(11) NOT NULL,
salary int(11) NOT NULL,
from_date date NOT NULL,
to_date date NOT NULL,
PRIMARY KEY (emp_no,from_date));
请你找出所有员工具体的薪水salary情况,对于相同的薪水只显示一次,并按照逆序显示,以上例子输出如下:

解法
# 对于distinct与group by的使用:
# 1、当对系统的性能高并数据量大时使用group by
# 2、当对系统的性能不高时使用数据量少时两者皆可
# 3、尽量使用group by
# DISTINCT+ORDER BY DESC
SELECT DISTINCT salary
FROM salaries
WHERE to_date = "9999-01-01"
ORDER BY salary DESC
# GROUP BY+ORDER BY DESC
SELECT salary
FROM salaries
WHERE to_date = "9999-01-01"
GROUP BY salary
ORDER BY salary DESC
SQL10 获取所有非manager的员工emp_no
题目
有一个员工表employees简况如下:

有一个部门领导表dept_manager简况如下:
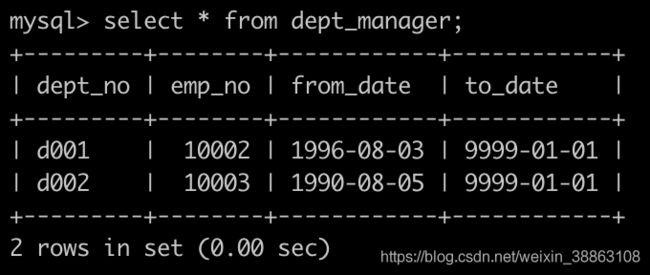
建表语句如下:
CREATE TABLE employees (
emp_no int(11) NOT NULL,
birth_date date NOT NULL,
first_name varchar(14) NOT NULL,
last_name varchar(16) NOT NULL,
gender char(1) NOT NULL,
hire_date date NOT NULL,
PRIMARY KEY (emp_no));
CREATE TABLE dept_manager (
dept_no char(4) NOT NULL,
emp_no int(11) NOT NULL,
from_date date NOT NULL,
to_date date NOT NULL,
PRIMARY KEY (emp_no,dept_no));
请你找出所有非部门领导的员工emp_no,以上例子输出:
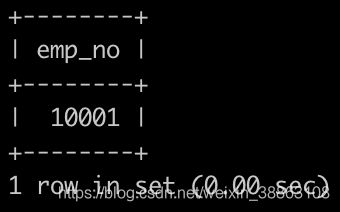
解法
# LEFT JOIN+WHERE IS NULL
SELECT e.emp_no
FROM employees AS e LEFT JOIN dept_manager AS d
ON e.emp_no = d.emp_no
WHERE dept_no IS NULL
#NOT IN+子查询
SELECT emp_no
FROM employees
WHERE emp_no NOT IN(SELECT emp_no FROM dept_manager)
SQL11 获取所有员工当前的manager
题目
有一个员工表dept_emp简况如下:

第一行表示为员工编号为10001的部门是d001部门。
有一个部门经理表dept_manager简况如下:

第一行表示为d001部门的经理是编号为10002的员工。
获取所有的员工和员工对应的经理,如果员工本身是经理的话则不显示,以上例子如下:

解法
# WHERE AND筛选条件!=
SELECT emp.emp_no AS emp_no,mgr.emp_no AS manager
FROM dept_emp AS emp LEFT JOIN dept_manager AS mgr
ON emp.dept_no = mgr.dept_no
WHERE emp.dept_no = mgr.dept_no
AND emp.emp_no != mgr.emp_no
# WHERE AND筛选条件NOT IN+子查询
SELECT emp.emp_no AS emp_no,mgr.emp_no AS manager
FROM dept_emp AS emp LEFT JOIN dept_manager AS mgr
ON emp.dept_no = mgr.dept_no
WHERE emp.dept_no = mgr.dept_no
AND emp.emp_no NOT IN(SELECT emp_no FROM dept_manager)
SQL12 获取所有部门中当前员工薪水最高的相关信息
题目
有一个员工表dept_emp简况如下:

有一个薪水表salaries简况如下:
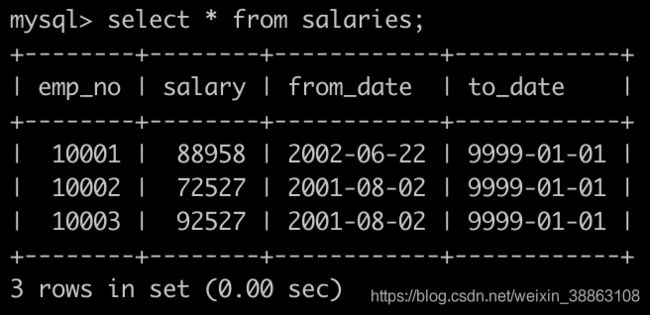
获取所有部门中员工薪水最高的相关信息,给出dept_no, emp_no以及其对应的salary,按照部门编号升序排列,以上例子输出如下:

解法1
# 第一步获取每个部门对应最高薪水的表t1
# 第二步将员工、部门、薪水整合在一张表t2
# 第三步将t1与t2整合取出dept_no, emp_no, maxSalary
SELECT t1.dept_no,t2.emp_no,t1.maxSalary
FROM
(
SELECT e.dept_no AS dept_no,MAX(salary) AS maxSalary
FROM dept_emp AS e LEFT JOIN salaries AS s
ON e.emp_no = s.emp_no
GROUP BY dept_no
)t1
JOIN
(
SELECT e.dept_no AS dept_no,e.emp_no AS emp_no,s.salary AS salary
FROM dept_emp AS e LEFT JOIN salaries AS s
ON e.emp_no = s.emp_no
)t2
ON t1.maxSalary = t2.salary AND t1.dept_no = t2.dept_no
ORDER BY t1.dept_no ASC
SQL15 查找employees表所有emp_no为奇数
题目
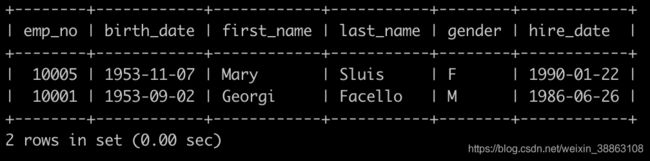
有一个员工表employees简况如下:

建表语句如下:
CREATE TABLE employees (
emp_no int(11) NOT NULL,
birth_date date NOT NULL,
first_name varchar(14) NOT NULL,
last_name varchar(16) NOT NULL,
gender char(1) NOT NULL,
hire_date date NOT NULL,
PRIMARY KEY (emp_no));
请你查找employees表所有emp_no为奇数,且last_name不为Mary的员工信息,并按照hire_date逆序排列,以上例子查询结果如下:
解法1
SELECT *
FROM employees
WHERE last_name<>'Mary'
AND emp_no&1#AND emp_no%2=1
ORDER BY hire_date DESC
SQL16 统计出当前各个title类型对应的员工当前薪水对应的平均工资
题目
有一个员工职称表titles简况如下:
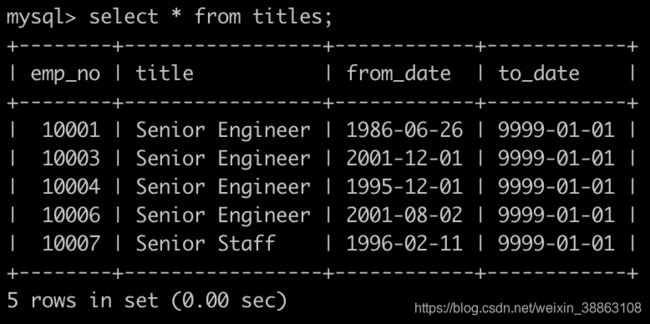
有一个薪水表salaries简况如下:
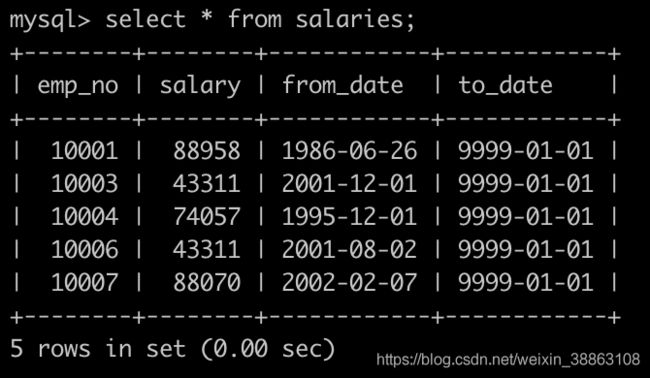
建表语句如下:
CREATE TABLE titles (
emp_no int(11) NOT NULL,
title varchar(50) NOT NULL,
from_date date NOT NULL,
to_date date DEFAULT NULL);
CREATE TABLE salaries (
emp_no int(11) NOT NULL,
salary int(11) NOT NULL,
from_date date NOT NULL,
to_date date NOT NULL,
PRIMARY KEY (emp_no,from_date));
请你统计出各个title类型对应的员工薪水对应的平均工资avg。结果给出title以及平均工资avg,并且以avg升序排序,以上例子输出如下:
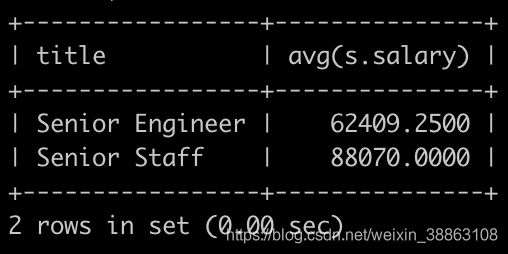
解法1
SELECT title, avg(s.salary)
FROM titles t JOIN salaries s
ON t.emp_no = s.emp_no
GROUP BY t.title
SQL17 获取当前薪水第二多的员工的emp_no以及其对应的薪水salary
题目
有一个薪水表salaries简况如下:

请你获取薪水第二多的员工的emp_no以及其对应的薪水salary
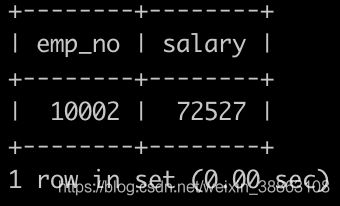
解法1
SELECT emp_no,salary
FROM salaries
ORDER BY salary DESC
LIMIT 1 OFFSET 1
解法2
#子查询
SELECT emp_no,salary
FROM salaries
WHERE salary = (
SELECT salary
FROM salaries
ORDER BY salary DESC
LIMIT 1,1
)
SQL18 查找当前薪水排名第二多的员工编号emp_no
查找当前薪水排名第二多的员工编号emp_no
有一个员工表employees简况如下:

有一个薪水表salaries简况如下:

请你查找薪水排名第二多的员工编号emp_no、薪水salary、last_name以及first_name,不能使用order by完成,以上例子输出为:
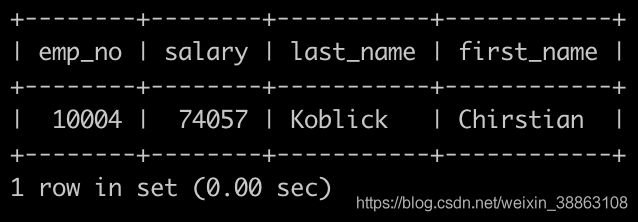
解法1
#使用两层子查询
#先查出最高工资
#再查排除最高工资之后的最高工资,即第二高工资
SELECT e.emp_no, salary, last_name, first_name
FROM employees e JOIN salaries s
ON e.emp_no = s.emp_no
WHERE s.salary = (
SELECT MAX(salary)
FROM salaries
WHERE salary<(
SELECT MAX(salary)
FROM salaries
)
)
解法2
表自连接以后:
s1 s2
100 100
98 98
98 98
95 95
当s1<=s2链接并以s1.salary分组时一个s1会对应多个s2
s1 s2
100 100
98 100
98
95 100
98
95
对s2进行去重统计数量, 就是s1对应的排名
-- 方法二
select s.emp_no, s.salary, e.last_name, e.first_name
from salaries s join employees e
on s.emp_no = e.emp_no
where s.salary =
(
select s1.salary
from salaries s1 join salaries s2 -- 自连接查询
on s1.salary <= s2.salary
and s1.to_date = '9999-01-01'
and s2.to_date = '9999-01-01'
group by s1.salary -- 当s1<=s2链接并以s1.salary分组时一个s1会对应多个s2
having count(distinct s2.salary) = 2 -- (去重之后的数量就是对应的名次)
)
and s.to_date = '9999-01-01'