随笔记录阿里云开发者社区Java开发高级技能自测20道题
目录
-
- 【单选】1.MyBatis中,主要使用哪个Java 接口来执行SQL命令?
- 【单选】2.Spring中ApplicationContext的主要用法是?
- 【单选】3.MySQL中,使用正则表达式查找news表中title以S或Q或L字母开头的所有数据,语句是?
- 【单选】4.MySQL索引最多包含多少个列?
- 【单选】5.Servlet处理Ajax请求如何设置请求消息的UTF-8编码?
- 【单选】6.InnoDB引擎设置读取缓存的参数?
- 【单选】7.MySQL如何修改日志文件的位置?
- 【单选】8.MySQL查询缓存机制query_cache_size的目的是?
- 【单选】9.Tomcat如何配置Java网站端口号?
- 【单选】10.如何开启MySQL的慢查询日志功能?
- 【单选】11.Spring MVC网站中,默认配置文件默认的目录是?
- 【单选】12.在我们使用maven过程中,经常会遇到依赖冲突,解决这种依赖jar包版本冲突冲突的办法有很多,以下操作不能解决冲突的选项是()
- 【多选】13.Spring MVC中,如何向前台JSP视图传递对象?
- 【多选】14.Spring MVC开发REST API使用的注解包括?
- 【多选】15.JSP网站项目中WEB-INF文件作用?
- 【多选】16.JDBC连接池核心参数包括?
- 【多选】17.Spring Bean 要自定义初始化和销毁逻辑代码,可以使用哪些方法?
- 【多选】18.阿里巴巴开源FastJSON库高性能序列化的底层原理?
- 【多选】19.关于Git的对象库(.git/objects)说法下面正确的是()
- 【多选】20.Spring MVC可以组合使用哪些开源安全框架实现身份验证?

今天利用了一点时间,自测了阿里云开发者社区的Java开发高级自测20道题目,错了3道,仅此记录!
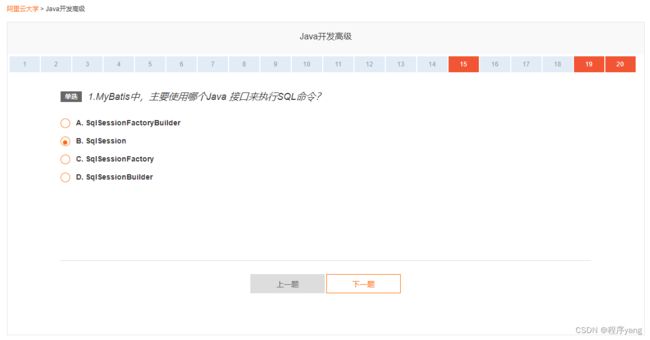
【单选】1.MyBatis中,主要使用哪个Java 接口来执行SQL命令?
- A. SqlSessionFactoryBuilder
- B. SqlSession
- C. SqlSessionFactory
- D. SqlSessionBuilder
| 答案:B |
解释:
A. SqlSessionFactoryBuilder 是用于创建 SqlSessionFactory 的建造者模式接口。它用于创建 SqlSessionFactory 实例,而不是直接执行 SQL 命令。
B. SqlSession 是 MyBatis 的核心接口之一。它提供了执行 SQL 命令的方法,例如执行查询、插入、更新和删除等操作。SqlSession 提供了对数据库的访问,可以直接执行 SQL 命令并返回结果。
C. SqlSessionFactory 是用于创建 SqlSession 的工厂接口。它是 MyBatis 的核心之一,负责创建和管理 SqlSession 实例。
D. SqlSessionBuilder 是用于创建 SqlSession 的建造者模式接口。它也用于创建 SqlSession 实例,但通常更常用的是直接使用 SqlSessionFactory 来创建 SqlSession。

【单选】2.Spring中ApplicationContext的主要用法是?
- A. Spring使用ApplicationContext创建应用程序
- B. Spring使用ApplicationContext创建MVC网站
- C. Spring使用ApplicationContext创建bean
- D. Spring使用ApplicationContext创建dao对象
| 答案:C |
解释:
A. ApplicationContext 并不是用来创建应用程序本身的,它是 Spring 框架中用于管理和配置 bean 的容器。
B. ApplicationContext 不是专门用于创建 MVC 网站的,尽管它可以在 MVC 网站中使用,但它的主要功能是管理和提供 bean,而不是创建整个 MVC 网站。
C. 正确答案。ApplicationContext 是 Spring 中最常用的容器接口之一,用于创建和管理 bean。通过配置文件或注解,我们可以在 ApplicationContext 中定义和配置 bean,并通过容器来获取和管理这些 bean 实例。
D. ApplicationContext 并不是用于创建 DAO(数据访问对象)对象的,尽管它可以在应用程序中管理和提供 DAO 对象的实例。创建 DAO 对象通常是通过依赖注入(Dependency Injection)或其他方式进行的。

【单选】3.MySQL中,使用正则表达式查找news表中title以S或Q或L字母开头的所有数据,语句是?
- A. SELECT * FROM news WHERE title like ‘^sql’;
- B. SELECT * FROM news WHERE title REGEXP ‘^sql’;
- C. SELECT * FROM news WHERE title REGEXP ‘^(S|Q|L)’;
- D. SELECT * FROM news WHERE title REGEXP ‘mysql$’;
| 答案:C |
解释:
A. 这个语句使用了 LIKE 操作符,但是正则表达式中的元字符 ^ 在 LIKE 中没有特殊含义。因此,它不适用于正则表达式的需求。
B. 这个语句使用了 REGEXP 操作符,但是正则表达式的模式应该是 ‘^(S|Q|L)’,以 S、Q 或 L 字母开头的数据。 ‘^sql’ 是一个以 “sql” 开头的模式,而不是以 S、Q 或 L 字母开头的模式。
C. 正确答案。这个语句使用了 REGEXP 操作符,并且正则表达式的模式是 ‘^(S|Q|L)’,匹配以 S、Q 或 L 字母开头的数据。这里的 ^ 表示匹配字符串的开头,而 (S|Q|L) 表示匹配 S、Q 或 L 中的任意一个字母。
D. 这个语句使用了 REGEXP 操作符,但是正则表达式的模式是 ‘mysql$’,匹配以 “mysql” 结尾的数据,而不是以 S、Q 或 L 字母开头的数据。

【单选】4.MySQL索引最多包含多少个列?
- A. 1
- B. 2
- C. 16
- D. 5
| 答案:C |
在 MySQL 中,一个索引最多可以包含 16 个列。这意味着你可以在创建索引时指定多达 16 个列来建立复合索引。复合索引可以根据多个列的组合进行查找和排序,提高查询效率。
解释:
A. 1:不正确。MySQL 允许创建单列索引,但是一个索引可以包含多个列。
B. 2:不正确。MySQL 允许创建复合索引,最多可以包含 16 个列。
C. 16:正确答案。一个索引最多可以包含 16 个列。
D. 5:不正确。MySQL 允许创建更多的列在一个索引中,最多可以包含 16 个列。

【单选】5.Servlet处理Ajax请求如何设置请求消息的UTF-8编码?
- A. response.setCharacterEncoding(“UTF-8”);
- B. response.setEncoding(“UTF-8”);
- C. request.setCharacterEncoding(“UTF-8”);
- D. request.setEncoding(“UTF-8”);
| 答案:C |
当处理 Ajax 请求时,我们通常需要确保请求消息的编码设置为 UTF-8,以确保正确地处理包含非ASCII字符的数据。
解释:
A. response.setCharacterEncoding(“UTF-8”):这个方法设置的是响应消息的编码方式,而不是请求消息的编码方式。因此,它不是正确的选项。
B. response.setEncoding(“UTF-8”):这个方法不存在于 Servlet API 中,因此不是正确的选项。
C. request.setCharacterEncoding(“UTF-8”):这个方法是正确的选项。它设置请求消息的编码方式为 UTF-8,以确保正确地解析包含非ASCII字符的请求数据。
D. request.setEncoding(“UTF-8”):这个方法不存在于 Servlet API 中,因此不是正确的选项。

【单选】6.InnoDB引擎设置读取缓存的参数?
- A. read_buffe = 2097152
- B. read_buffer_size = 2097152
- C. buffer_size = 2097152
- D. write_buffer_size = 2097152
| 答案:B |
InnoDB 是 MySQL 数据库的默认存储引擎之一,用于处理事务和行级锁定。要设置 InnoDB 引擎的读取缓存参数,可以使用 read_buffer_size 参数。
解释:
A. read_buffe = 2097152:这个选项是错误的,因为 read_buffe 不是有效的 InnoDB 缓存参数。
B. read_buffer_size = 2097152:这个选项是正确的,可以使用 read_buffer_size 参数来设置 InnoDB 引擎的读取缓存大小。该参数用于指定 InnoDB 缓存池中用于读取操作的缓存区的大小,以字节为单位。
C. buffer_size = 2097152:这个选项是错误的,因为 buffer_size 不是用于设置 InnoDB 引擎的读取缓存参数。
D. write_buffer_size = 2097152:这个选项是错误的,write_buffer_size 是用于设置 InnoDB 引擎的写入缓存大小的参数,而不是读取缓存参数。

【单选】7.MySQL如何修改日志文件的位置?
- A. mysql.cnf中修改log-error=/var/log/mysqld.log
- B. mysql.txt中修改log-error=/var/log/mysqld.log
- C. mysql.config中修改log-error=/var/log/mysqld.log
- D. mysql.cnf中修改log-error=/var/log/my.log
| 答案:A |
要修改 MySQL 的错误日志文件的位置,可以在 MySQL 的配置文件 mysql.cnf(或 my.cnf)中使用 log-error 参数来指定。log-error 参数用于指定错误日志文件的路径和名称。
解释:
A. mysql.cnf中修改log-error=/var/log/mysqld.log:这个选项是正确的。通过在 mysql.cnf 中修改 log-error 参数,将其值设置为所需的日志文件位置(在这种情况下是 /var/log/mysqld.log),可以修改 MySQL 的错误日志文件的位置。
B. mysql.txt中修改log-error=/var/log/mysqld.log:这个选项是错误的,因为通常情况下 MySQL 的配置文件使用的是 .cnf(或 .ini)扩展名,而不是 .txt。
C. mysql.config中修改log-error=/var/log/mysqld.log:这个选项是错误的,因为通常情况下 MySQL 的配置文件使用的是 .cnf(或 .ini)扩展名,而不是 .config。
D. mysql.cnf中修改log-error=/var/log/my.log:这个选项是不正确的,因为修改的是错误日志文件的位置,而不是一般日志文件的位置。

【单选】8.MySQL查询缓存机制query_cache_size的目的是?
- A. 缓存查询计划,节约磁盘空间
- B. 缓存查询计划,提升查询性能
- C. 缓存查询计划,提升写入性能
- D. 缓存查询计划,后续相同的查询可以性能加速
| 答案:D |
MySQL 的查询缓存机制允许将查询结果缓存在内存中,以提高相同查询的执行性能。query_cache_size 是用于配置查询缓存的大小的参数。当查询被执行时,MySQL 会检查查询语句是否已经在查询缓存中,并且缓存中存在相同的查询结果。如果存在,MySQL 将直接返回缓存的结果,而不执行实际的查询操作,从而提高查询性能。
解释:
A. 缓存查询计划,节约磁盘空间:这个选项是错误的,查询缓存机制并不是用于缓存查询计划,而是用于缓存查询结果。查询计划是指优化器决定如何执行查询的方式。
B. 缓存查询计划,提升查询性能:这个选项是部分正确的,查询缓存机制确实可以提升查询性能,但它并不是缓存查询计划,而是缓存查询结果。
C. 缓存查询计划,提升写入性能:这个选项是错误的,查询缓存机制并不会提升写入性能,它主要用于提升读取相同查询的性能。
D. 缓存查询计划,后续相同的查询可以性能加速:这个选项是正确的。查询缓存机制会缓存查询结果,当后续的相同查询出现时,MySQL 可以直接返回缓存的结果,而不需要再执行实际的查询操作,从而提高查询性能。

【单选】9.Tomcat如何配置Java网站端口号?
- A. web.xml修改
- B. tomcat.xml修改
- C. server.xml修改
- D. apache.xml修改
- B. tomcat.xml修改
| 答案:C |
要配置 Tomcat 的 Java 网站端口号,可以在 Tomcat 的配置文件 server.xml 中进行相应的修改。
解释:
A. web.xml修改B. tomcat.xml修改 C. server.xml修改 D. apache.xml修改

【单选】10.如何开启MySQL的慢查询日志功能?
- A. 配置文件中设置slow_query=1
- B. 配置文件中设置query_log=1
- C. 配置文件中设置slow_query_log=1
- D. 配置文件中设置slow_query=true
| 答案:C |
要开启 MySQL 的慢查询日志功能,可以通过在 MySQL 的配置文件中进行相应的设置来实现。
解释:
A. 配置文件中设置slow_query=1:这个选项是错误的,因为 MySQL 的配置文件中没有名为 slow_query 的参数。
B. 配置文件中设置query_log=1:这个选项是错误的,因为 MySQL 的配置文件中没有名为 query_log 的参数。
C. 配置文件中设置slow_query_log=1:这个选项是正确的。通过在 MySQL 的配置文件中设置 slow_query_log 参数的值为 1,可以开启慢查询日志功能。设置为 1 表示启用慢查询日志。
D. 配置文件中设置slow_query=true:这个选项是错误的,因为 MySQL 的配置文件中的参数值一般使用数字表示而不是布尔值。
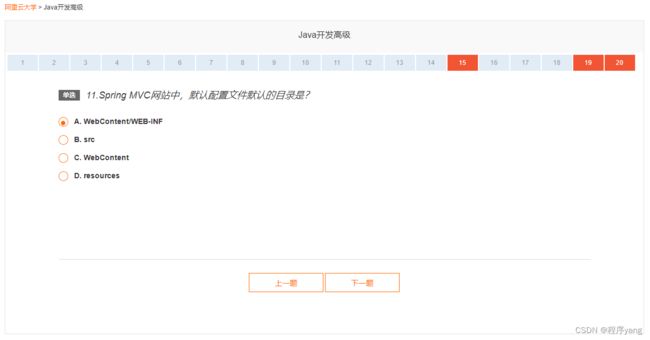
【单选】11.Spring MVC网站中,默认配置文件默认的目录是?
- A. WebContent/WEB-INF
- B. src
- C. WebContent
- D. resources
| 答案:A |
在 Spring MVC 网站中,默认配置文件的目录是 WebContent/WEB-INF。
解释:
A. WebContent/WEB-INF:这个选项是正确的。在标准的 Spring MVC 项目中,配置文件通常位于 WebContent/WEB-INF 目录下。这个目录是受保护的,不允许直接访问其中的文件,这样可以保护配置文件的安全性。
B. src:这个选项是不正确的。src 目录通常用于存放源代码文件,而不是用于存放配置文件。
C. WebContent:这个选项是不正确的。WebContent 目录通常用于存放网站的静态资源文件(如 HTML、CSS、JavaScript 等),而不是用于存放配置文件。
D. resources:这个选项是不正确的。resources 目录通常用于存放项目的资源文件,如图片、配置文件、国际化资源等,但并非默认的配置文件目录。

【单选】12.在我们使用maven过程中,经常会遇到依赖冲突,解决这种依赖jar包版本冲突冲突的办法有很多,以下操作不能解决冲突的选项是()
- A. 名称相同,版本不同的依赖冲突,优先声明自己用到的jar包。
- B. 传递依赖的包冲突,声明指定版本的包。
- C. 在pom.xml文件中声明相应版本的相应jar包。
- D. 清理本地Maven仓库
| 答案:D |
依赖冲突是在 Maven 项目中常见的问题,由于不同的依赖可能引用了相同的类或资源,但版本不同,这可能导致编译错误或运行时错误。
解释:
A. 名称相同,版本不同的依赖冲突,优先声明自己用到的 jar 包:这个选项是一种常见的解决方法。通过在 pom.xml 文件中显式地声明所需依赖的版本,可以确保使用特定版本的依赖,而不受其他冲突依赖的影响。
B. 传递依赖的包冲突,声明指定版本的包:这个选项也是一种常见的解决方法。当依赖链中的传递依赖存在冲突时,可以通过在 pom.xml 文件中显式地声明特定版本的依赖来解决冲突。
C. 在 pom.xml 文件中声明相应版本的相应 jar 包:这个选项也是正确的。在 Maven 的 pom.xml 文件中,通过添加依赖项的 元素,并指定所需的版本,可以解决依赖冲突问题。
D. 清理本地 Maven 仓库:这个选项是不正确的。清理本地 Maven 仓库并不是解决依赖冲突的方法。本地 Maven 仓库存储了项目所需的依赖库,清理仓库可能会导致项目无法构建或运行。
因此,正确的答案是 D. 清理本地 Maven 仓库,这并不是解决依赖冲突的方法。

【多选】13.Spring MVC中,如何向前台JSP视图传递对象?
- A. 可以使用ModelAndView
- B. 可以使用Model
- C. 可以使用ModelMap
- D. 可以使用Session
| 答案:ABCD |
解释:
A. 可以使用ModelAndView:ModelAndView 是一个包含数据模型和视图信息的对象,可以通过将对象设置到 ModelAndView 的 Model 中传递给 JSP 视图。
B. 可以使用Model:Model 是一个接口,可以在处理器方法中通过方法参数中的 Model 对象将数据添加到 Model 中,然后将 Model 返回给 JSP 视图。
C. 可以使用ModelMap:ModelMap 是 Model 接口的具体实现类,用于向视图传递数据。可以通过方法参数中的 ModelMap 对象将数据添加到 ModelMap 中,然后将 ModelMap 返回给 JSP 视图。
D. 可以使用Session:Session 是用于在不同请求之间共享数据的机制,可以将对象存储在 Session 中,然后在 JSP 视图中通过 Session 对象获取数据。

【多选】14.Spring MVC开发REST API使用的注解包括?
- A. 注解@Controller +注解@RequestBody
- B. 注解@Controller +@ResponseBody
- C. 注解@RestController
- D. 注解@RestController+注解@RequestBody
| 答案:BC |
解释:
A. 注解@Controller + 注解@RequestBody:这个选项是不完整的。虽然使用 @Controller 注解可以标识控制器类,而 @RequestBody 注解用于将请求体中的数据绑定到方法参数上,但缺少了将响应数据转换为合适的格式并返回的注解。
B. 注解@Controller + @ResponseBody:这个选项是正确的。@Controller 注解用于标识控制器类,而 @ResponseBody 注解用于将方法的返回值转换为合适的格式(如 JSON、XML 等)并返回给客户端,适用于 REST API 的开发。
C. 注解@RestController:这个选项是正确的。@RestController 注解是 Spring 4.0 之后提供的组合注解,相当于同时使用了 @Controller 和 @ResponseBody 注解。它用于标识控制器类,并且方法的返回值会自动转换为合适的格式并返回给客户端,非常适合 REST API 的开发。
D. 注解@RestController + 注解@RequestBody:这个选项是正确的。@RestController 注解标识控制器类,并且 @RequestBody 注解用于将请求体中的数据绑定到方法参数上。这样可以将请求体的数据解析后,处理并返回响应数据。

【多选】15.JSP网站项目中WEB-INF文件作用?
- A. Java的WEB应用的日志目录
- B. Java的WEB应用的安全目录
- C. 客户端无法直接访问里面的文件
- D. 安全性客户端可以直接访问里面的文件
| 答案:猜测是BCD |
这道题有点坑啊。应该不止我一个人选择BC吧?你们选择哪几个?
解释:
A. Java的WEB应用的日志目录:这个选项是不正确的。WEB-INF 目录并不是用于存放日志文件的目录。
B. Java的WEB应用的安全目录:这个选项是正确的。WEB-INF 目录是用于存放应用程序的安全相关文件和配置的目录。在该目录下的文件通常不能被客户端直接访问到,提供了一定程度的安全性。
C. 客户端无法直接访问里面的文件:这个选项是正确的。WEB-INF 目录中的文件无法直接通过客户端的请求访问。这可以防止客户端绕过应用程序的逻辑和安全控制来访问 WEB-INF 目录下的敏感文件。
D. 安全性客户端可以直接访问里面的文件:这个选项待定,有人能详细解释一下吗?

【多选】16.JDBC连接池核心参数包括?
- A. initialSize
- B. maxIdle
- C. minIdle
- D. maxActive
- E. maxWait
| 答案:ABCDE |
解释:
A. initialSize:连接池的初始大小,即连接池中初始创建的连接数。
B. maxIdle:连接池中最大空闲连接数。
C. minIdle:连接池中保持的最小空闲连接数。
D. maxActive:连接池中同时可以活动的最大连接数。
E. maxWait:获取连接时的最大等待时间,超过该时间将抛出异常。

【多选】17.Spring Bean 要自定义初始化和销毁逻辑代码,可以使用哪些方法?
- A. init-method
- B. create-method
- C. destroy-method
- D. close-method
| 答案:AC |
解释:
A. init-method:通过在 Bean 的配置中指定 init-method 属性,可以指定一个方法,在 Bean 实例化后进行初始化操作。
C. destroy-method:通过在 Bean 的配置中指定 destroy-method 属性,可以指定一个方法,在 Bean 销毁前进行销毁操作。
B. create-method 和 D. close-method 并不是 Spring Bean 的初始化和销毁方法的配置选项。
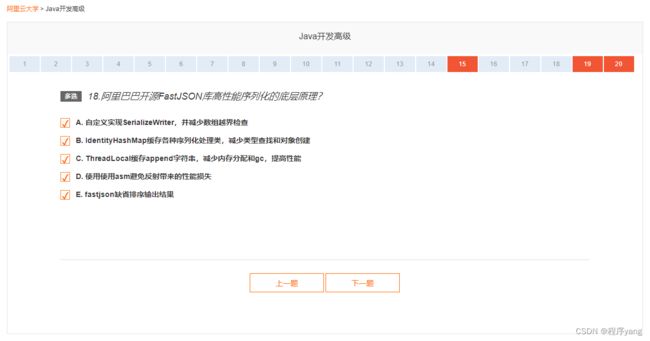
【多选】18.阿里巴巴开源FastJSON库高性能序列化的底层原理?
- A. 自定义实现SerializeWriter,并减少数组越界检查
- B. IdentityHashMap缓存各种序列化处理类,减少类型查找和对象创建
- C. ThreadLocal缓存append字符串,减少内存分配和gc,提高性能
- D. 使用使用asm避免反射带来的性能损失
- E. fastjson缺省排序输出结果
| 答案:ABCDE |
解释:
A. 自定义实现 SerializeWriter,并减少数组越界检查:FastJSON 使用自定义的 SerializeWriter 类来进行序列化操作,通过减少数组越界检查等优化措施,提高了序列化的性能。
B. IdentityHashMap 缓存各种序列化处理类,减少类型查找和对象创建:FastJSON 使用 IdentityHashMap 来缓存各种序列化处理类,以减少类型查找和对象创建的开销,提高序列化性能。
C. ThreadLocal 缓存 append 字符串,减少内存分配和 GC,提高性能:FastJSON 使用 ThreadLocal 来缓存 append 字符串,避免频繁的内存分配和垃圾回收,从而提高序列化性能。
D. 使用 ASM 避免反射带来的性能损失:FastJSON 使用 ASM(Java 字节码操纵框架)来生成字节码,避免了使用反射带来的性能损失,提高了序列化和反序列化的效率。
E. FastJSON 缺省排序输出结果:FastJSON 在序列化时会按照字段名的字典顺序进行排序,以确保输出结果的一致性和可预测性。
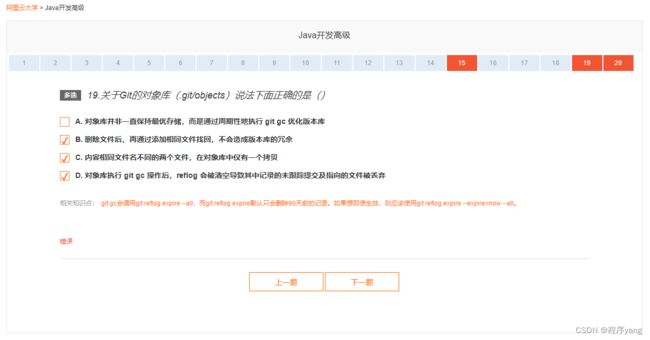
【多选】19.关于Git的对象库(.git/objects)说法下面正确的是()
- A. 对象库并非一直保持最优存储,而是通过周期性地执行 git gc 优化版本库
- B. 删除文件后,再通过添加相同文件找回,不会造成版本库的冗余
- C. 内容相同文件名不同的两个文件,在对象库中仅有一个拷贝
- D. 对象库执行 git gc 操作后,reflog 会被清空导致其中记录的未跟踪提交及指向的文件被丢弃
| 答案:ACD |
解释:
A选项正确,因为Git的对象库并非一直保持最优存储,而是通过周期性地执行git gc命令来优化版本库。git gc会删除不再被引用的对象,以及对对象进行压缩,从而减小版本库的大小。
B选项错误,当删除文件后,再通过添加相同的文件,会产生新的对象,导致版本库的冗余。Git中的对象是不可变的,因此每个文件的每个版本都会被独立地保存在对象库中。
C选项正确,因为Git使用哈希算法对每个文件进行计算得到一个唯一的哈希值,并将哈希值作为索引存储文件。因此,如果两个文件的内容相同,它们的哈希值也相同,那么在对象库中就只会存储一个拷贝。
D选项正确,因为git gc命令会清空reflog,reflog中记录了未跟踪提交及指向的文件,所以执行git gc操作后,reflog中的记录会被丢弃。

【多选】20.Spring MVC可以组合使用哪些开源安全框架实现身份验证?
- A. Apache Hadoop
- B. Apache Shiro
- C. MyBatis
- D. Spring Security
| 答案: |
很遗憾,这道题BD竟然不对,总觉得题目出的好刁钻。你们选择哪几个?
解释:
A. Apache Hadoop 是一个分布式计算框架,用于处理大规模数据的开源框架,与Spring MVC无直接关联,与身份验证和安全相关的模块主要是 Hadoop Security,用于保护 Hadoop 集群的安全。
B. Apache Shiro 是一个独立开源通用的 Java 安全框架,提供身份验证、授权、加密等功能,可以与 Spring MVC 等框架集成使用,但不是Spring MVC的默认安全框架。
C. MyBatis 是一个持久化框架,用于数据库访问,与身份验证和安全无直接关系。
D. Spring Security是一个专注于为Java应用程序提供身份验证和访问控制的开源框架,提供诸如身份验证、授权、攻击防护等功能,它与Spring框架深度集成,可以与 Spring MVC 等框架无缝集成使用,是Spring MVC默认的安全框架,提供了丰富的身份验证和授权功能。
附:Java开发技能自测相关入口,题目随机