INTERSPEECH 2023论文|基于多频带时频注意力的复调音乐旋律提取
论文题目:
MTANet: Multi-band Time-frequency Attention Network for Singing Melody Extraction from Polyphonic Music
作者列表:
高虞安,胡英,王柳淞,黄浩,何亮
研究背景
复调音乐是一种具有多个声部交织在一起的音乐形式。在复调音乐中,不同的声部可以同时演奏不同的旋律线,相互独立但又相互关联。乐器伴奏与主声交织在一起,使任务相当有挑战性。获得复调音乐的(主)旋律线对于理解和分析复调音乐的结构和特征相当重要,歌手产生的高共振声音容易导致高次谐波的振幅大于基频,这是算法误判[1]造成八度误差的主要声学原因。因此,获得一种能够区分基频和非基频成分(例如伴奏或唱声的更高的谐波)的语义表示至关重要。
拟解决问题
-
通过网络获得一种能够区分基频和非基频成分(例如伴奏或唱声的更高的谐波)的语义表示;
-
解决/减少常见于复调音乐旋律提取任务中的八度误差(下图红圈所示)与旋律检测误差(下图绿圈所示)。
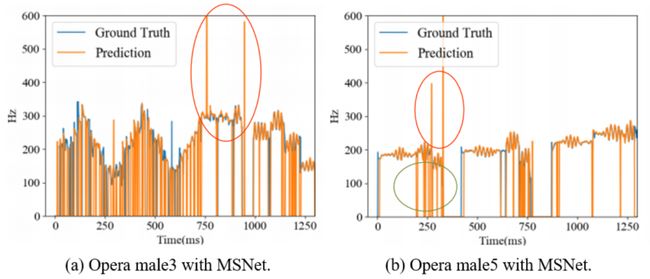
图1 MSNet对于两首歌剧预测结果的可视化
本文方案
第一阶段:基于数据预处理的频带划分
由于估计对象主要是人类唱声的基频,因此其存在的频率范围上下限有一定参考标准。结合人类唱声频率范围和全部样本的音调八度分布,我们注意到基频(F0)分量趋向于分布在一定位置内,同时较高次谐波和高频噪声会对基频定位造成一定的消极影响,这促使我们利用频谱中的位置信息来表征F0分量和非F0分量。因此,我们提出了一种频带划分策略,旨在利用频谱中基频和非基频成分的位置分布来表征基频分量和非基频分量。同时,频带划分能够有效规避高次谐波及高频噪声对基频定位的影响。
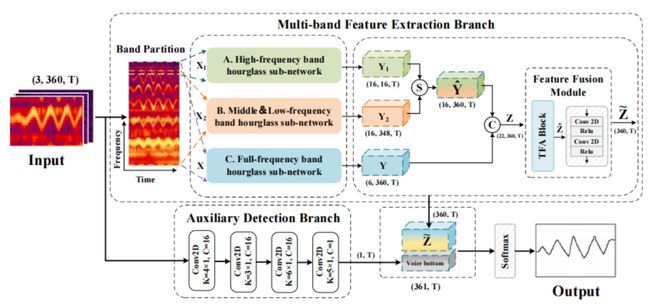
图2 多频带时频注意力网络框架
第二阶段:针对不同频带的差别特征提取
由于音乐信号在不同频带中具有不同的特性(较低的频带更可能包含调性和长期持续的声音,其具有较高的能量,而较高的频带倾向于包含噪声和快速衰减的声音,其具有较低的能量[2]),因此我们为不同频带的特征提取模块设置了差异化的通道数、层数、膨胀系数以满足不同的角色需求。具体来讲,作为基频分布的主要频带,中低频带沙漏子网络包含更多的通道数、更深的网络层数以及更大的膨胀卷积系数;作为承载非基频信息(噪声/更高次谐波)的高频带,其具备的各项参数较小;同时,为了弥补划分操作不可避免的频谱信息割裂,我们也设置了全频带网络作为整体信息的补偿。
第三阶段:对不同频带特征的选择融合
通过对多频带特征的激活可视化,我们观察到不同通道内特征分别表征不同频带的信息,为了更好地选择和聚合不同通道内的特征,基于时频注意力思想[3],我们提出了一种特征融合模块,该模块执行通道内的时频注意力及通道间信息的线性重组。事实上,在这个阶段可以尝试的方案有很多,例如通道注意力、Selective Kernel思想等。
实验结果分析
我们在三个涵盖不同音乐类型的数据集上验证模型的性能和泛化性,在综合对比中与行业主流和经典算法进行比较。如表1表示,我们的方法在3个测试集上取得了除VFA外的最好性能。OA(整体精确度)一般被认为是最重要的指标。与结构相似的MSNet[4]相比,性能的提升充分验证了频带划分方案和整体结构部署的有效性。与采用多头自注意力机制的TONet[5]相比,在大幅减少参数的基础上也取得了良好的效果,使模型更便于嵌入式设计。
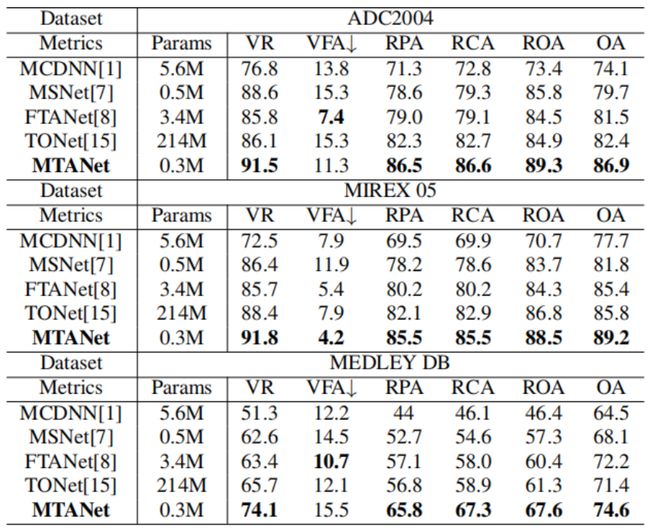
表1 多频带时频注意力网络框架
我们也采用可视化方法探索该方法解决了哪些类型的错误。如图3所示,可以观察到图(a)比(b)有更少的八度误差(即轮廓的垂直跳跃)。同时,图(a) 250ms和750ms附近的旋律检测误差(即预测旋律帧为非旋律帧)比图(b)中更少。
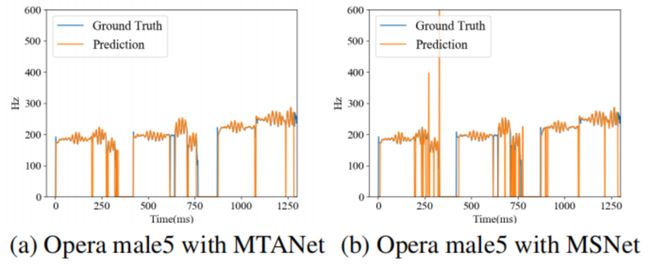
图3 MTANet与MSNet于歌剧male5预测结果的可视化对比
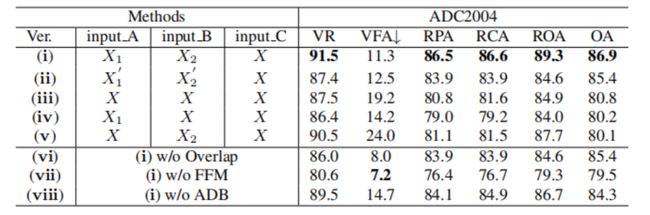
表2展示了消融实验结果,我们设计了多组频带划分消融来验证其有效性。同时,在频带划分时,我们设置了4个frequency bins的重叠以缓解划分带来的频域信息割裂问题,可以看出缺少重叠设置,性能明显下降。另外,缺少特征融合阶段会导致大量的性能损失,充分证明了特征融合模块的有效性。
表2 ADC2004数据集的消融实验结果
小结
我们提出一种用于歌唱旋律提取的多频带时频注意力网络。频带划分方案被证明能够有效地利用F0分量的位置分布来进一步捕获各种多频带特征。同时,利用特征融合模块执行通道内的时频注意力及通道间信息的线性重组进而融合多频带特征。实验结果表明,该方法在保持较少参数量的基础上取得了良好的性能且能够有效减少八度误差和旋律检测误差。
参考文献
[1] J. Salamon, E. Gomez, D. P. Ellis, and G. Richard, “Melody extraction from polyphonic music signals: Approaches, applications, and challenges,” IEEE Signal Processing Magazine, vol. 31, no. 2, pp. 118–134, 2014.
[2] Chen Y, Hu Y, He L, et al. Multi-stage music separation network with dual-branch attention and hybrid convolution[J]. Journal of Intelligent Information Systems, 2022: 1-22.
[3] S. Yu, X. Sun, Y. Yu, and W. Li, “Frequency-temporal attention network for singing melody extraction,” in ICASSP 2021-2021IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2021, pp. 251–255.
[4] T.-H. Hsieh, L. Su, and Y.-H. Yang, “A streamlined encoder/decoder architecture for melody extraction,” in ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2019, pp. 156–160.
[5] K. Chen, S. Yu, C.-i. Wang, W. Li, T. Berg-Kirkpatrick, and S. Dubnov, “Tonet: Tone-octave network for singing melody extraction from polyphonic music,” in ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022, pp.621–625.