数据库SQL查询(一)
本文介绍SQL查询,如何在海量数据中筛选想要数据;
数据库管理系统选择:关系型数据库mysql
数据库管理工具选择:navicat
本文中查询语句和查询案例参考自:https://edu.csdn.net/course/detail/27673?ops_request_misc=&request_id=&biz_id=105&utm_term=SQL&utm_medium=distribute.pc_search_result.none-task-course-2~course~sobaiduweb~default-3-27673.pc_edu_default&spm=1018.2226.3001.4453
目录
基本结构
示例(重命名 AS)
运算符
比较运算符:
示例(不等于 !=)
示例(为空 IS NULL)
示例(属于 IN)
示例(正则表达式 REGEXP)
排序
示例(ORDER BY)
聚合函数
示例(最大值 MAX)
示例(平均值 AVG)
示例(计数 COUNT)
示例(求和 SUM)
分组查询
示例(分组 GROUP BY)
示例(分组后筛选 HAVING)
示例(分组前筛选 WHERE)
嵌套查询
示例(in)
基本结构
select -- 查询什么,列筛选,其中*表示所有列
from -- 在哪个表查询,主要连接要查询的表名称
where -- 满足什么条件,行筛选
示例(重命名 AS)
As可以为列重命名
-- 查询出姓名为“陈鹏”的学号、手机号码和邮箱地址并重命名
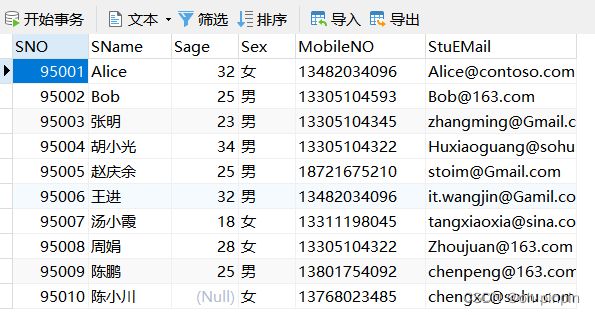
SELECT
sno AS '学号',
mobileno AS '手机号码',
stuemail AS '邮箱地址'
FROM
Student
WHERE
sname = '陈鹏'
运算符
参考:SQL学习之运算符_sql运算符有哪些_heart-szu的博客-CSDN博客
比较运算符:
比较运算符用来对表达式左边的操作数和右边的操作数进行比较,比较的结果为真则返回1,比较的结果为假则返回0,其他情况则返回NULL。
比较运算符经常被用来作为SELECT 查询语句的条件来使用,返回 符合条件的结果记录。
= 等于
<> != 不等于
>= > <= < 大于 大于等于 小于 小于等于
is null, is not null null不能使用比较运算符
示例(不等于 !=)
-- 查询出姓名不是“陈鹏”的学生的所有信息
SELECT
*
FROM
Student
WHERE
sname != '陈鹏'
示例(为空 IS NULL)
-- 查询哪些学生没有填写“年龄 ”信息
SELECT
SNo,
SName
FROM
Student
WHERE
sage IS NULL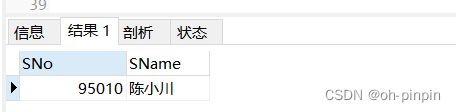
示例(属于 IN)
-- 查询出“陈鹏”、”Alice”、”Bob”的学号,姓名
SELECT
sno,
sname
FROM
Student
WHERE
sname IN (
'陈鹏',
'Alice',
'Bob')
示例(正则表达式 REGEXP)
-- 查询出手机号码133或者134开头,倒数第二位为不是2也不是4的学生
SELECT
*
FROM
Student
WHERE
mobileno REGEXP '^[1][3][34][0-9]{1,}[^24][0-9]$'
排序
通过Order by 进行排序;ASC升序 DESC降序 ;不写默认是升序;
示例(ORDER BY)
-- 对Student表按照年龄升序排序,如果年龄一样,女生排在男生前面
SELECT
*
FROM
Student
ORDER BY
sage ASC,
sex ASC -- mysql中是ASCII码排序,转换后女排在男前面,所以是升序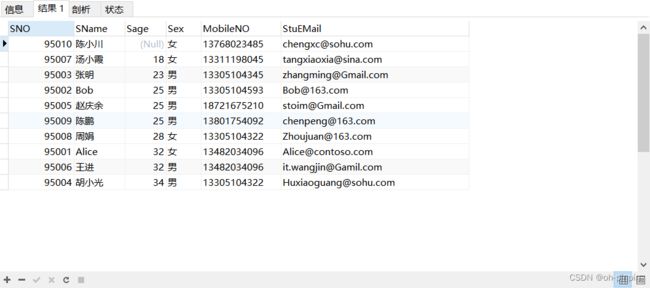
聚合函数
聚合函数对一组值执行计算并返回单一的值;
COUNT:求所选记录行数(可与distinct连用,消除重复值再计数)
AVG:求所选记录的平均值
SUM:为所选记录求和
MAX:求所选记录的最大值
MIN:求所选记录的最小值
示例(最大值 MAX)
-- 查询年龄最大值
SELECT
MAX( sage )
FROM
Student 
示例(平均值 AVG)
-- 查询男生的平均年龄
SELECT
AVG( sage )
FROM
Student
WHERE
sex = '男' 
示例(计数 COUNT)
-- 查询有多少位学生借书
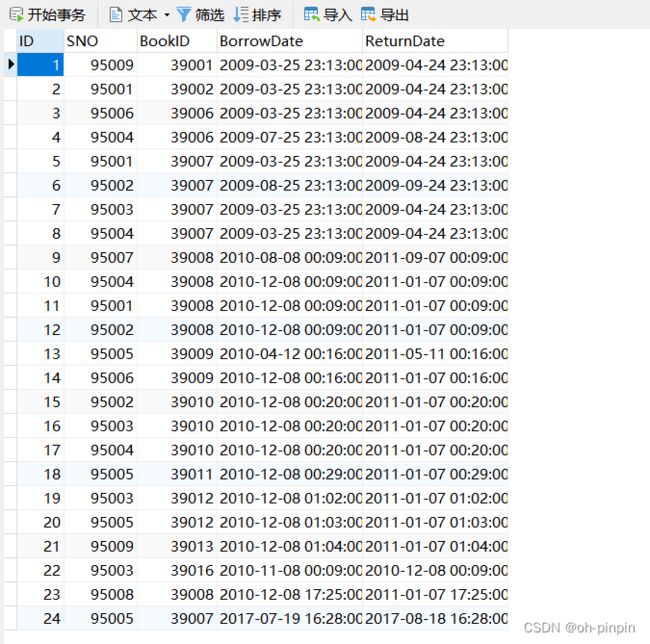
SELECT
COUNT( DISTINCT sno )
FROM
BorrowBook 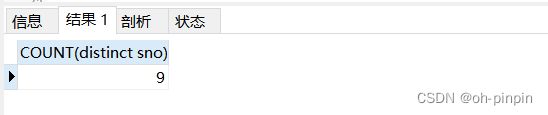
示例(求和 SUM)
-- 查询计算机类的图书总共有多少本
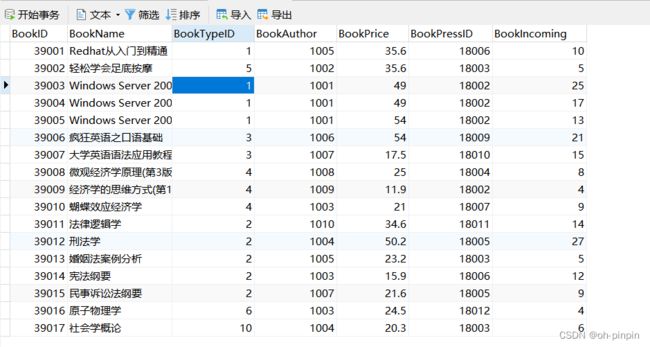
SELECT
SUM( bookincoming )
FROM
Book
WHERE
booktypeid = ( SELECT id FROM BookType WHERE typename = '计算机' ) 
分组查询
“Group By”从字面意义上理解就是根据“By”指定的规则对数据进行分组,所谓的分组就是将一个数据集划分成若干个小区域,然后针对若干个小区域进行数据处理
分组前筛选--where
分组后筛选--having
示例(分组 GROUP BY)
-- 查询出男女生姓名、人数、平均年龄、年龄和
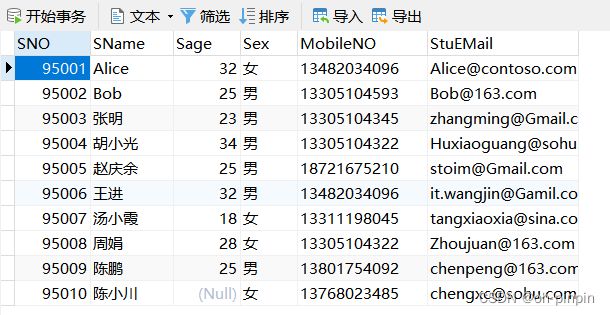
SELECT
Sex,
GROUP_CONCAT( sname ) AS '学生姓名', -- GROUP_CONCAT可以把多个值显示到一起
Count(*) AS '人数',
avg( sage ) AS '平均年龄',
sum( sage ) AS '年龄和'
FROM
Student
GROUP BY
Sex -- 按照性别分组
示例(分组后筛选 HAVING)
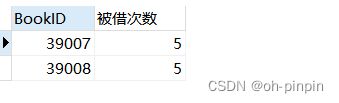
-- 查询出借的最多的那本书的Id

SELECT
BookID,
COUNT(*) AS '被借次数'
FROM
BorrowBook
GROUP BY
BookId -- 按照ID分组
HAVING
COUNT(*) = -- 分组后筛选借书最多值
(
SELECT
COUNT(*)
FROM
BorrowBook
GROUP BY
BookId
ORDER BY
COUNT(*) DESC
LIMIT 1
)
示例(分组前筛选 WHERE)
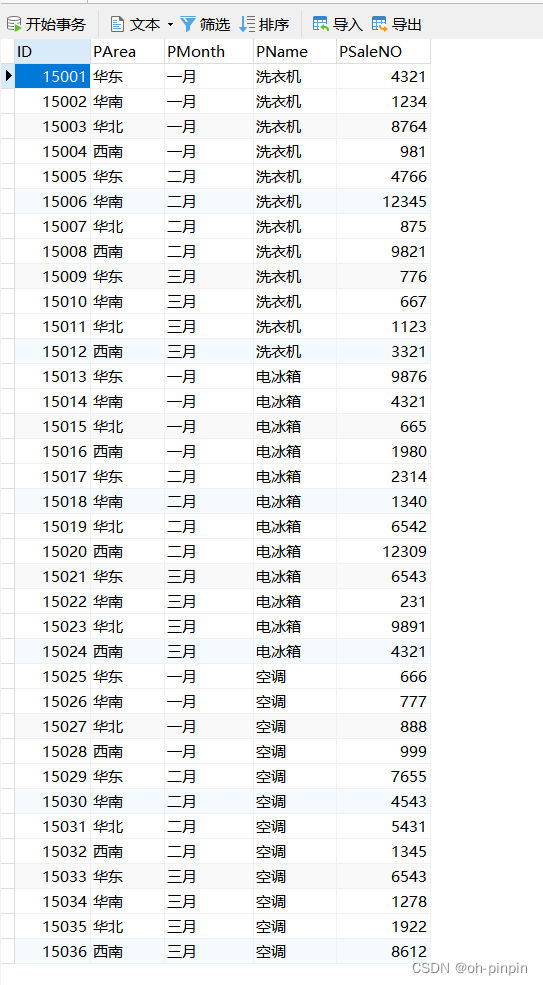
-- 统计出一月份哪些区域的哪些商品销售低于1000件, 按照倒序排列
SELECT
PArea AS '区域',
PName AS '名称',
SUM( PSaleNo ) AS '销售量'
FROM
SalesTable
WHERE
PMonth = '一月' -- 分组前筛选一月份数据:Where
GROUP BY
PArea,
PName -- 按照区域和商品分组
HAVING
SUM( PSaleNo ) < 1000 -- 分组后筛选低于1000件数据:having
ORDER BY
SUM( PSaleNo ) DESC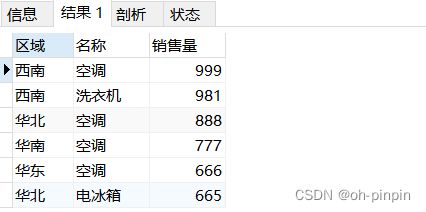
嵌套查询
在SQL语言中,一个SELECT-FROM-WHERE语句称为一个查询块。将一个查询块嵌套在另一个查询块的 WHERE子句 或 HAVING短语 的条件中的查询称为嵌套查询;
先处理内查询,由内向外处理;
连接关键字:
如果子查询确定就一个值,可以使用 = 或者 in 连接
如果子查询是多个值,需要用 in 连接
in , = any , = some 效果一样
any 满足一个就是真, all 满足所有的才是真
in 判断是否存在于集合,exists 是否有结果
示例(in)
-- 查询陈鹏借了哪些书
表关系如下图所示:

student表中通过sname匹配sno,作为条件传给borrowbook表
borrowbook表中通过sno匹配bookID,作为条件传给book表
book表中通过bookID匹配bookname
SELECT
bookname
FROM
Book
WHERE
bookid IN (
SELECT
bookid
FROM
BorrowBook
WHERE
sno = ( SELECT sno FROM Student WHERE sname = '陈鹏' )
)