使命: 开放和优秀的机器学习
在我们的使命中,我们致力于推动机器学习 (ML) 的民主化,我们在研究如何支持 ML 社区工作并有助于检查危害和防止可能的危害发生。开放式的发展和科学可以分散力量,让许多人集体开展反映他们需求和价值的 AI 研究工作。虽然 开放性使得更广泛的观点能够为研究和整个 AI 贡献力量,但它也面对着较小风险控制的紧张。
由于这些系统的动态和快速发展,对 ML 相关模型进行管控面临着独特的挑战。事实上,随着 ML 模型变得更加先进和能够生成越来越多样化的内容,使得潜在的有害或意外的输出的可能性增加,需要开发强大的调节和评估策略。此外,ML 模型的复杂性和它们处理的大量数据加剧了识别和解决潜在偏见和道德问题的挑战。
作为社区主理人,我们认识到,随着社区模型可能放大对用户和整个世界的危害,我们肩负着责任。这些危害通常会以一种依赖于情境的方式不平等地影响少数群体。我们采取的方法是分析每个情境中存在的紧张关系,并对公司和 Hugging Face 社区进行讨论。虽然许多模型可能会放大危害,尤其是歧视性内容,但我们正在采取一系列步骤来识别最高风险模型以及要采取的行动。重要的是,许多不同背景的活跃观点对于理解、衡量和减轻影响不同群体的潜在危害至关重要。
我们正在开发工具和保障措施,除了改进我们的文档实践以确保开源科学能够赋予个人权力,并继续将潜在危害最小化。
道德类别
我们培养良好的开放式 ML 工作的第一个主要方面是推广 ML 开发的工具和正面示例,这些工具和示例优先考虑其利益相关者的价值和考虑。这有助于用户采取具体步骤解决悬而未决的问题,并为 ML 开发中事实上的破坏性做法提出合理的替代方案。
为了帮助我们的用户发现和参与与伦理相关的 ML 工作,我们编制了一组标签。这 6 个高级类别基于我们对社区成员贡献的空间的分析。它们旨在为你提供一种通俗易懂的方式来思考道德技术:
- 严谨的工作特别注意在开发时牢记最佳实践。在 ML 中,这可能意味着检查失败案例 (包括进行偏见和公平性审计),通过安全措施保护隐私,并确保潜在用户 (技术和非技术) 了解项目的局限性。
- 自愿工作 支持 使用这些技术和受这些技术影响的人的自主决定。
- 具有社会意识的工作向我们展示了技术如何支持社会、环境和科学工作。
- 可持续工作着重介绍并探索使机器学习在生态上可持续发展的技术。
- 包容性工作扩大了在机器学习世界中构建和受益的对象范围。
- 追根问底的工作揭示了不平等和权力结构,这些不平等和权力结构挑战了社区并让其重新思考自身与技术的关系。
在 https://huggingface.co/ethics 上阅读更多内容
查找这些术语,我们将在 Hub 上的一些新项目中使用这些标签,并根据社区贡献更新它们!
保障措施
对开放版本采取“全有或全无”的观点忽略了决定 ML 模型正面或负面影响的各种背景因素。对 ML 系统的共享和重用方式进行更多控制,支持协作开发和分析,同时降低促进有害使用或滥用的风险; 允许更多的开放和参与创新以共享利益。
我们直接与贡献者接触并解决了紧迫的问题。为了将其提升到一个新的水平,我们正在构建基于社区的流程。这种方法使 Hugging Face 贡献者和受贡献影响的人能够告知我们平台上提供的模型和数据所需的限制、共享和其他机制。我们将关注的三个主要方面是: 工件 ( artifact ) 的来源、工件的开发者如何处理工件以及工件的使用方式。在这方面,我们:
- 为我们的社区推出了一个 报告功能,以确定 ML 工件或社区内容 (模型、数据集、空间或讨论) 是否违反了我们的 内容指南,
- 监控我们的社区讨论板,以确保 Hub 用户遵守 行为准则,
- 使用详细说明社会影响、偏见以及预期和超出范围的用例的模型卡,有力地记录我们下载次数最多的模型,
- 创建观众引导标签,例如可以添加到仓库的卡片元数据中的“不适合所有观众”标签,以避免未请求的暴力和色情内容,
- 促进对 模型 使用 开放式负责任人工智能许可证 (RAIL),例如 LLM (BLOOM,BigCode)
- 进行研究,分析 哪些模型和数据集最有可能被滥用和恶意使用,或有记录显示滥用和恶意使用。
如何使用报告功能:
单击任何模型、数据集、空间或讨论上的报告图标:
 仓库的功能。这将在仓库的社区选项卡中打开一个对话。")
分享你标记此项目的原因:

在优先考虑开放科学时,我们逐案检查潜在危害,并提供协作学习和分担责任的机会。当用户标记系统时,开发人员可以直接透明地回应问题。本着这种精神,我们要求仓库所有者做出合理的努力来解决报告的问题,尤其是当报告人花时间提供问题描述时。我们还强调,报告和讨论与平台的其他部分一样,遵循相同的沟通规范。如果行为变得仇恨和/或辱骂,模型拥有者可以脱离或结束讨论 (参见 行为准则)。
如果我们的社区将特定模型标记为高风险,我们会考虑:
如何添加“不适合所有受众”标签:
编辑 model/data card → 在标签部分添加 not-for-all-audiences → 打开 PR ,等待作者合并。合并后,以下标签将显示在仓库中:

任何标记有 not-for-all-audiences 的仓库在访问时都会显示以下弹出窗口:
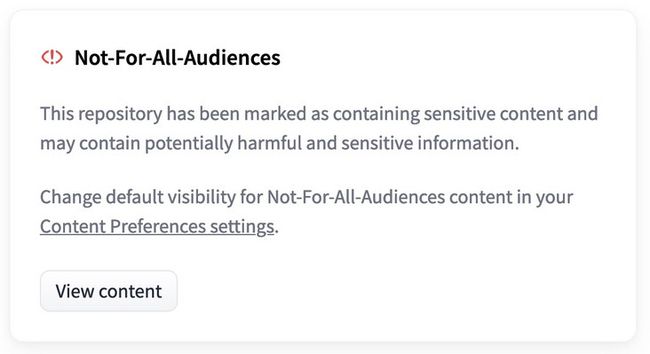
单击“查看内容”将允许你正常查看仓库。如果你希望始终在没有弹出窗口 not-for-all-audiences 的情况下查看标记的仓库 , 可以在用户的 Content Preferences 中更改此设置

开放科学需要保障措施,我们的一个目标是创造一个考虑到不同价值取舍的环境。提供模型和培育社区并讨论能够赋予多元群体评估社会影响以及引导好的机器学习的能力。
你在做保障措施吗?请在 Hugging Face Hub 上分享它们!
Hugging Face 最重要的部分是我们的社区。如果你是一名研究人员,致力于使 ML 的使用更安全,尤其是对于开放科学,我们希望支持并展示你的工作!
以下是 Hugging Face 社区研究人员最近的一些示例和工具:
- John Kirchenbauer, Jonas Geiping, Yuxin Wen, Jonathan Katz, Ian Miers, Tom Goldstein (论文) 的 大语言模型的水印
- Hugging Face 团队的 生成模型卡片的工具
- Ram Ananth 的保护图像免受篡改的 Photoguard
感谢阅读 !
~ Irene, Nima, Giada, Yacine, 和 Elizabeth, 代表道德和社会常规人员
如果你想引用这篇博客,请使用以下内容 (按贡献降序排列):
@misc{hf_ethics_soc_blog_3,
author = {Irene Solaiman and
Giada Pistilli and
Nima Boscarino and
Yacine Jernite and
Elizabeth Allendorf and
Margaret Mitchell and
Carlos Muñoz Ferrandis and
Nathan Lambert and
Alexandra Sasha Luccioni
},
title = {Hugging Face Ethics and Society Newsletter 3: Ethical Openness at Hugging Face},
booktitle = {Hugging Face Blog},
year = {2023},
url = {https://doi.org/10.57967/hf/0487},
doi = {10.57967/hf/0487}
}英文原文: https://huggingface.co/blog/ethics-soc-3
作者: Irene Solaiman, Giada Pistilli, Nima Boscarino, Yacine Jernite, Elizabeth Allendorf
译者: innovation64
排版/审校: zhongdongy (阿东)