JUC并发编程(二)
JUC并发编程(续)
接上一篇笔记:https://blog.csdn.net/weixin_44780078/article/details/130694996
五、Java内存模型
JMM 即 Java Memory Model,它定义了主存、工作内存抽象概念,底层对应着CPU寄存器、缓存、硬件内存、CPU 指令优化等。
JMM 体现在以下几个方面:
- 原子性:保证指令不会受到线程上下文切换的影响。
- 可见性:保证指令不会受 cpu 缓存的影响。
- 有序性:保证指令不会受 cpu 指令并行优化的影响。
多线程中的上下文切换:上下文切换是指当一个线程正在执行时,CPU需要暂停当前线程的执行,并将其上下文(如程序计数器、寄存器内容、堆栈指针等)保存到内存中,然后加载另一个线程的上下文,执行另一个线程。
1 可见性
先看案例:退不出的循环
private static boolean run = true;
public static void main(String[] args) {
Thread t1 = new Thread(() -> {
while (run) {
// ...
}
}, "线程t1");
t1.start();
sleep(1000);
log.info("线程t1停止");
run = false; // 改为false过后按理说会退出 while 循环
}
结果:把run改为false后,并没有像预期那样停下来,而是在一直运行。

结果分析:
- 初始状态,线程 t1 刚开始从主内存读取了 run 的值到工作内存。

- 因为线程 t1 要频繁从主内存中读取 run 的值,JIT 编译器会将 run 的值缓存至自己工作内存中的高速缓存中,减少对主存中run 的访问,提高效率。
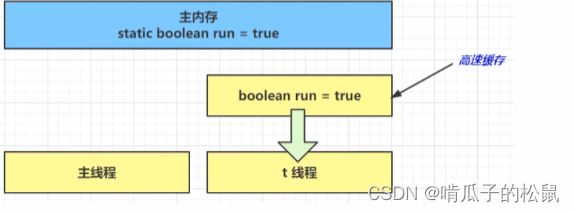
- 1秒过后,主线程修改了 run 的值,并同步至主存,而线程 t1 是从自己的工作内存中的高速缓存中读取的这个变量值,结果永远是之前的旧值。

tips: 产生这种现象的原因就是,主线程修改了主内存中的变量值,但是对于另一个线程(t1)不可见。
解决方法:对变量加上 volatile 关键字,就保证了线程 t1 每次都是在主存中去读取,保证了线程对数据的可见性。(但性能得到了损失,因为线程 t1 之前是在自己工作内存的高速缓存读取,现在是从主存读取)
private volatile static boolean run = true;
public static void main(String[] args) {
Thread t1 = new Thread(() -> {
while (run) {
// ...
}
}, "线程t1");
t1.start();
sleep(1000);
log.info("线程t1停止");
run = false;
}
结果:得到了解决。

tips: volatile关键字,可以用来修饰成员变量和静态成员变量,它可以避免线程从自己的工作缓存中查找变量的值,必须到主存中获取,线程操作 volatile 变量都是直接操作主存。
2 可见性 vs 原子性
前面例子体现的就是可见性,它保证的是在多个线程之间,一个线程对 volatile 变量的修改对另一个线程可见,但不能保证原子性,适用在于一个写线程,多个读线程的情况。
synchronized 语句块既可以保证代码块的原子性,也同时保证代码块内变量的可见性。但缺点是 synchronized 属于重量级操作,性能相对更低。
private volatile static boolean run = true;
final static Object lock = new Object();
public static void main(String[] args) {
Thread t1 = new Thread(() -> {
// ...
synchronized (lock) {
while (!run) {
break;
}
}
}, "线程t1");
t1.start();
sleep(1000);
log.info("线程t1停止");
synchronized (lock) {
run = false;
}
}
3 volatile 原理
volatile 的底层实现原理是内存屏障,Memory Barrier,对 volatile 变量的写指令后会加入写屏障;对 volatile 变量的读指令前会加入读屏障。
- 写屏障保证在该屏障之前,对共享变量的改动,都同步到主存中。
- 而读屏障保证在该屏障之后,对共享变量的读取,加载的是主存中最新的数据。
可见性的案例:单例模式(懒汉式)
分析如下代码,假如线程 t1 访问的时候,instance == null,因此会进入 if 创建一个Singleton()对象,如果 new Singleton()对象还未完成,此时线程 t2 又来访问,instance还是为null,因此还是会去创建 Singleton() 对象,这就导致失去了单例模式的意义。
public class Singleton {
private Singleton() {};
private static Singleton instance = null;
public static Singleton getInstance() {
if (instance == null) {
instance = new Singleton();
}
return instance;
}
}
因此加入 synchronized 对代码进行改进:
public class Singleton {
private Singleton() {};
private static Singleton instance = null;
public static synchronized Singleton getInstance() {
if (instance == null) {
instance = new Singleton();
}
return instance;
}
}
加了 synchronized 同步锁后,问题得到解决。但是仔细思考,发现这样修改也不是最佳的修改,因为我们只需要对线程第一次访问的时候加锁就行了,如果已经创建了对象,后续的线程访问时 instance 已经不为 null ,直接返回即可,就不需要再加锁了,显然这样代码的效率降低了。
因此再次修改代码:加入两次判断。这样当线程 t1 第一次访问时,instance 显然为 null,因此进行加锁创建对象,假设在创建对象的过程中线程 t2 再次访问,此时显然还是为 null,线程 t2 就阻塞等待,等到线程 t1 创建完对象后,线程 t2 进入第二个 if,此时 instance 已经不为null了,因此就直接退出 if。 后续的线程再来访问时,由于 instance 不为 null,因此直接返回,所以 synchronized 只加了一次锁。
public class Singleton {
private Singleton() {};
private volatile static Singleton instance = null;
public static Singleton getInstance() {
if (instance == null) {
synchronized(Singleton.class) {
if (instance == null) {
instance = new Singleton();
}
}
}
return instance;
}
}
六、共享模型之无锁
对于会发生线程安全的代码,可以通过加锁的方式解决,比如:synchronized,但也可以通过无锁的方式实现:AtomicInteger。AtomicInteger 既然没有采用加锁的方式,那它又是如何实现的呢?
AtomicInteger 内部有一个方法:compareAndSet(compare and set,比较和交换,简称CAS),它的操作是原子的。它的底层是lock cmpxchg指令(x86架构),在单核CPU和多核CPU下都能保证比较-交换的原子性。

1 CAS 与 volatile
获取共享变量时,为了保证该变量的可见性,需要使用 volatile 修饰,它可以用来修饰成员变量和静态成员变量,可以避免线程从自己的工作缓存中查找变量的值,必须到主存中获取它的值,线程操作 volatile 变量都是直接操作主存。即一个线程对 volatile 变量的修改,对另一个线程可见。
注意:volatile 仅仅保证了共享变量的可见性,让其它线程能够看到最新值,但不能解决指令交错的问题(不能保证原子性)。
CAS 必须借助 volatile 才能读取到共享变量的最新值来实现比较-交换的效果。
2 CAS无锁效率
无锁情况下,即使失败重试,线程始终在高速运行,没有停歇,而 synchronized 会让线程在没有获得锁的时候,发生上下文切换,进入阻塞状态。因此,CAS无锁比加锁效率高。
3 CAS特点
结合 CAS 和 volatile 可以实现无锁并发,适用于线程数少,多核CPU的情况下。
- CAS是基于乐观锁的思想:不怕别的线程来修改共享变量,就算改了也没关系,重试即可。
- synchronized 是基于悲观锁的思想:一开始就加锁,防备其它线程来修改共享变量,加了锁后任何线程都别想修改,只有等待锁释放,才会轮到下一个线程执行。
- CAS 体现的是无锁并发、无阻塞并发,所以效率较高。
4 原子整数
- AtomicInteger
- AtomicBoolean
- AtomicLong
具体用来操作什么Atomic后面的后缀已经很明显的显示了。此处以AtomicInteger举例:
AtomicInteger a = new AtomicInteger(1);
System.out.println(a.getAndIncrement()); // 打印1,分析:获取值先打印,再+1,也就是内存中a的值实际变为2了
System.out.println(a.incrementAndGet()); // 打印3,分析:获取值+1后再打印
System.out.println(a.getAndAdd(5)); // 打印3,分析:先获取打印,再+5,实际值变成8了
System.out.println(a.addAndGet(5)); // 打印13,分析:先获取实际值,+5后再打印
System.out.println(a.getAndUpdate(Value -> Value * 10)); // 打印13,分析:先获取值打印,就是13,然后再乘以10,实际内存中的值为130
System.out.println(a.updateAndGet(Value -> Value * 10)); // 打印1300,分析:先获取值130,乘以10,然后打印,就是1300
为什么要引用原子类型?
Atomic 家族主要是保证多线程环境下的原子性,相比 synchronized 而言更加轻量级。比较常用的是 AtomicInteger,作用是对 Integer 类型操作的封装,而AtomicReference作用是对普通对象的封装。
AtomicReference 举例:
先定义一个 User 类
@Data
@AllArgsConstructor
public class User {
private String name;
private Integer age;
}
使用 AtomicReference 初始化,并赋值:
public static void main(String[] args) {
User user1 = new User("张三", 23);
User user2 = new User("李四", 25);
User user3 = new User("王五", 20);
// 初始化为 user1
AtomicReference<User> atomicReference = new AtomicReference<>();
atomicReference.set(user1);
System.out.println(atomicReference.get()); //打印:User(name=张三, age=23)
}
使用 compareAndSet 方法:
public static void main(String[] args) {
User user1 = new User("张三", 23);
User user2 = new User("李四", 25);
User user3 = new User("王五", 20);
// 初始化为 user1
AtomicReference<User> atomicReference = new AtomicReference<>();
atomicReference.set(user1);
// 把 user2 赋给 atomicReference
atomicReference.compareAndSet(user1, user2);
System.out.println(atomicReference.get()); //打印:User(name=李四, age=25)
// 把 user3 赋给 atomicReference
atomicReference.compareAndSet(user1, user3);
System.out.println(atomicReference.get()); //打印:User(name=李四, age=25)
}
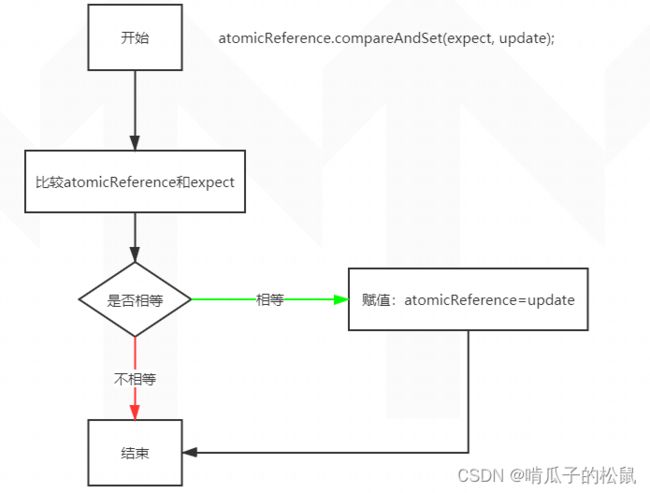
compareAndSet 方法解释:
compareAndSet(V expect, V update)
该方法作用是:如果atomicReference == expect,就把update赋给atomicReference,否则不做任何处理。对于上述的案例,因为一开始 atomicReference 初始化为 user1,执行 atomicReference.compareAndSet(user1, user2) 时,由于expect 就为 user1,所以会把 update 的 user 2 赋值给atomicReference,执行 atomicReference.compareAndSet(user1, user3) 时,由于 atomicReference 为 user2,不等于 expect,所以不做任何操作,user3就赋值失败。
4 原子引用-ABA问题
假如我们要把字符串A,改为C,可以直接这样运行:
static AtomicReference<String> ref = new AtomicReference<>("A");
public static void main(String[] args) {
log.debug("main start...");
String prev = ref.get();
sleep(1000);
log.debug("change A->C: {}", ref.compareAndSet(prev,"C"));
}
但是我们修改代码,做如下操作:
/**
* 预设初始值: "A"
*/
static AtomicReference<String> ref = new AtomicReference<>("A");
public static void main(String[] args) {
log.debug("main start...");
String prev = ref.get();
other();
sleep(1000);
/**
* 传入的值: prev
* 想要更新的值:"C"
*
* 判断传入的prev是否等于预先设置的初始值,是则修改,否则不予修改。
*/
log.debug("change A->C: {}", ref.compareAndSet(prev,"C"));
}
public static void other() {
new Thread(() -> {
log.debug("change A->B {}", ref.compareAndSet(ref.get(), "B"));
},"线程t1").start();
sleep(500);
new Thread(() -> {
log.debug("change B->A {}", ref.compareAndSet(ref.get(), "A"));
},"线程t2").start();
}
发现同样也能实现需求,只不过绕了一圈,先把A改为B,再把B改为A,这样在把A改为C时,也能修改成功。
假如主线程在把A修改为C的过程中,能进行预先判断,假如A在修改之前被其他线程修改过,就不进行操作,又该如何实现?
此处引入一个新的方法:AtomicStampedReference
AtomicStampedReference:只要有其它线程操作过共享变量,那么自己的 cas 就算失败,这时,仅比较值是不够的,需要再加一个版本号,即有线程操作过共享变量,就让版本号+1。
/**
* 预设初始值: "A"
* 预设版本号:0,也可以设置其他数,规则是自定义的
*/
static AtomicStampedReference<String> ref = new AtomicStampedReference<>( "A",0);
public static void main(String[] args) {
String prev = ref.getReference();
int stamp = ref.getStamp();
log.debug("版本号为:{}",stamp);
other();
sleep(1000);
log.debug("other方法执行结束,版本号:",stamp);
/**
* 传入的值: prev
* 想要更新的值:"C"
* 带入的版本号:stamp
* 修改成功后修改的预设标记值:false
*
* 判断传入的prev是否等于预先设置的初始值,并且判断版本号是否等于初始的版本号,是则修改,修改后还把版本号+1,否则不予修改。
*/
log.debug("change A->C: {}", ref.compareAndSet(prev,"C",stamp,stamp+1));
}
public static void other() {
new Thread(() -> {
int stamp = ref.getStamp();
log.debug("change A->B {}", ref.compareAndSet(ref.getReference(), "B", stamp, stamp+1));
},"线程t1").start();
sleep(500);
new Thread(() -> {
int stamp = ref.getStamp();
log.debug("change B->A {}", ref.compareAndSet(ref.getReference(), "A", stamp, stamp+1));
},"线程t2").start();
}

发现主线程的修改失败了,达到了最初的需求。
此处再引入一个方法:AtomicMarkableReference
AtomicMarkableReference:相对于AtomicStampedReference,AtomicMarkableReference只记录一个boolean值,假如初始值传true,有其他线程操作过,就改为false,这样就不需要记录版本号了。
/**
* 预设初始值: "A"
* 预设标记值:true,也可以为false,规则是自定义的
*/
static AtomicMarkableReference<String> ref = new AtomicMarkableReference<>( "A",true);
public static void main(String[] args) {
String prev = ref.getReference();
other();
sleep(1000);
/**
* 传入的值: prev
* 想要更新的值:"C"
* 带入的预设标记值:true
* 修改成功后修改的预设标记值:false
*
* 判断传入的prev是否等于预先设置的初始值,并且判断标记是否为true,是则修改,修改后还把标记改为fasle,否则不予修改。
*/
log.debug("change A->C: {}", ref.compareAndSet(prev,"C",true,false));
}
public static void other() {
new Thread(() -> {
log.debug("change A->B {}", ref.compareAndSet(ref.getReference(), "B", true,false));
},"线程t1").start();
sleep(500);
new Thread(() -> {
log.debug("change B->A {}", ref.compareAndSet(ref.getReference(), "A", true,false));
},"线程t2").start();
}
七、不可变对象
我们知道String是不可变的:
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence {
/** The value is used for character storage. */
private final char value[];
/** Cache the hash code for the string */
private int hash;
发现该类和类中所有属性都是final修饰的:
- 属性用 final 修饰保证了该属性的只读的,不能修改;
- 类用 final 修饰保证了该类中的方法不能被覆盖,防止子类无意间破坏不可变性;
八、并发工具类
1 线程池
为什么要使用线程池?
- 1、线程是一种系统资源,每创建一个线程都需要占用一定的内存(需分配栈内存),如果在高并发的情况下,一瞬间来了很多任务,每个任务都需要创建一个线程,这样务必会占用太多的资源,也可能会导致out of memory(内存溢出)的情况发生;
- 2、线程并非创建的越多越好,由于我们的计算机cpu数量有限,创建太多的线程会导致有大部分线程会因为得不到cpu的调度而导致阻塞,cpu 进行过多的线程的上下文切换也会严重影响性能。
线程池:创建一批线程,让这些线程可以得到重复的利用,这样既可以避免创建过多的线程,也可以避免过多的线程去造成cpu的线程上下文切换。
自定义线程池:

2 JDK中线程池实现–ThreadPoolExecutor
线程池状态:
ThreadPoolExecutor 使用 int 的高 3 位来表示线程池状态,低 29 位表示线程数量。
| 状态名 | 高3位 | 接收新任务 | 处理阻塞队列任务 | 说明 |
|---|---|---|---|---|
| running | 111 | Y | Y | |
| shutdown | 000 | N | Y | 不会接收新任务,但会处理阻塞队列剩余任务 |
| stop | 001 | N | N | 会中断正在执行的任务,兵抛弃阻塞队列任务 |
| tidying | 010 | - | - | 任务全部执行完毕,活动线程为0即将进入终结 |
| terminated | 011 | - | - | 终结状态 |
从数字上比较:terminated > tidying > stop > shutdown > running
这些信息存储在一个原子变量 ctl 中,目的是将线程池状态与线程个数合二为一,这样就可以用一次 cas 原子操作进行赋值。
// c 为旧值,ctlOf 返回结果为新值
ctl.compareAndSet(c, ctlOf(targetState, workerCountOf(c))));
// rs 为高 3 位代表线程池状态,wc 为低 29 位代表线程个数,ctl 是合并它们
private static int ctlOf(int rs, int wc) {
return rs | wc;
}
构造方法:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
- corePoolSize:核心线程数目(最多保留的线程数);
- maximumPoolSize:最大线程数目;
- keepAliveTime:生存时间针对救急线程;
- unit:时间单位针对救急线程;
- workQueue:阻寨队列;
- thrcadFactory:线程工厂可以为线程创建时起个好名字;
- handler:拒绝策略;
- 线程池中刚开始没有线程,当一个任务提交给线程池后,线程池会创建一个新线程来执行任务。当线程数达到corePoolSize 并没有线程空闲,这时再加入任务,新加的任务会被加入workQueue 队列排队,直到有空闲的线程。如果队列选择了有界队列,那么任务超过了队列大小时,会创建 maximumPoolSize - corePoolSize 数目的线程来救急。
- 如果线程到达 maximumPoolSize 仍然有新任务这时会执行拒绝策略。拒绝策略 jdk 提供了4种实现,其它著名框架也提供了实现:
- AbortPolicy 让调用者抛出 RejectedExecutionException 异常,这是默认策略;
- CallerRunsPolicy让调用者运行任务;
- DiscardPolicy 放弃本次任务;
- DiscardOldestPolicy 放弃队列中最早的任务,本任务取而代之;
- Dubbo 的实现,在抛出RejectedExecutionException 异常之前会记录日志,并 dump 线程栈信息,方便定位问题;
- Netty 的实现,是创建一个新线程来执行任务;
- ActiveMQ 的实现,带超时等待 (60s)尝试放入队列,类似我们之前自定义的拒绝策略;
- PinPoint 的实现,它使用了一个拒绝策略链,会逐一尝试策略链中每种拒绝策略当高峰过去后,超过 corePoolSize 的救急线程如果一段时间没有任务做,需要结束节省资源,这个时间由 keepAliveTime 和 unit 来控制;
线程池状态:
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor( nThreads, nThreads
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
特点:
- 核心线程数-- 最大线程数(没有救急线程被创建),因此也无需超时时间;
- 阻塞队列是无界的,可以放任意数量的任务;
3 ThreadPoolExecutor–提交任务
// 执行任务
void execute(Runnable command);
// 提交任务 task,用返回值 Future 获得任务执行结果
<T> Future<T> submit(Callable<T> task);
// 提交 tasks 中所有任务
<T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks) throws InterruptedException;
// 提交 tasks 中所有任务,带超时时间
<T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks, long timeout, TimeUnit unit) throws InterruptedException;
// 提交 tasks 中所有任务,哪个任务先成功执行完毕,返回此任务执行结果,其它任务取消
<T> T invokeAny(Collection<? extends Callable<T>> tasks) throws InterruptedException, ExecutionException;
// 提交 tasks 中所有任务,哪个任务先成功执行完毕,返回此任务执行结果,其它任务取消,带超时时间
<T> T invokeAny(Collection<? extends Callable<T>> tasks,
long timeout, TimeUnit unit)
throws InterruptedException, ExecutionException, TimeoutException;
4 关闭线程池
线程池状态变为 shutdown ,就不会接收新任务,但已提交的任务会执行完,这个方法不会阻塞调用线程的执行。
void shutdown();
public void shutdown() (
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
checkShutdownAccess();
// 修改线程池状态
advanceRunState(SHUTDOWN);
// 仅会打断空闲线程
interruptIdleWorkers();
onShutdown(); // 扩展点 ScheduledThreadPoolExecutor
} finally (
mainLock.unlock();
}
// 尝试终结(没有运行的线程可以立刻终结,如果还有运行的线程也不会等)
tryTerminate();
}
其它方法:
// 不在 RUNNING 状态的线程池,此方法就返回 true
boolean isShutdown();
// 线程池状态是否是 TERMINATED
boolean isTerminated();
// 调用shutdown 后,由于调用线程并不会等待所有任务运行结束,因此如果它想在线程池 TERMINATED 后做些事情,可以利用此方法等待
boolean awaitTermination(long timeout, TimeUnit unit) throws InterruptedException;
5 任务调度线程池–Timer
在任务调度线程池功能加入之前,可以使用 java.util.Timer 来实现定时功能,Timer 的优点在于简单易用,但由于所有任务都是由同一个线程来调度,因此所有任务都是串行执行的,同一时间只能有一个任务在执行,前一个任务的延迟或异常都将会影响到之后的任务。
Timer 案例:
public static void main(String[] args) {
Timer timer = new Timer();
TimerTask task1 = new TimerTask() {
@Override
public void run() {
log.info("task 1");
sleep(2000);
}
};
TimerTask task2 = new TimerTask() {
@Override
public void run() {
log.info("task 2");
}
};
/**
* 使用 timer 添加两个任务,希望它们都在 1s 后执行
* 但出于 timer 内只有一个线程来顺序执行队列中的任务,因此[任务1] 的延时,影响了了任务2的执行
*/
log.info("主线程开始执行...");
timer.schedule(task1, 1000);
timer.schedule(task2, 1000);
}
结果:发现任务2隔了两秒才执行,也就是 task1 和 task2 是串行执行的。

假设task1执行过程中出错了,task2也不会执行:
public static void main(String[] args) {
Timer timer = new Timer();
TimerTask task1 = new TimerTask() {
@Override
public void run() {
log.info("task 1");
int i = 1/0;
}
};
TimerTask task2 = new TimerTask() {
@Override
public void run() {
log.info("task 2");
}
};
log.info("主线程开始执行...");
timer.schedule(task1, 1000);
timer.schedule(task2, 1000);
}
结果:发现 task2 根本就没执行。再次证明task是串行执行的。

6 任务调度线程池–ScheduledThreadPoolExecutor
Timer 案例:
public static void main(String[] args) {
ScheduledExecutorService pool = Executors.newScheduledThreadPool(2);
pool.schedule(() -> {
log.info("task1 执行");
sleep(1000);
}, 1, TimeUnit.SECONDS);
pool.schedule(() -> {
log.info("task2 执行");
}, 1, TimeUnit.SECONDS);
}
结果:发现两个task是同时执行的。

假设task1也出错了,task2也会正常执行:
public static void main(String[] args) {
ScheduledExecutorService pool = Executors.newScheduledThreadPool(1);
pool.schedule(() -> {
log.info("task1 执行");
int i = 1 / 0;
}, 1, TimeUnit.SECONDS);
pool.schedule(() -> {
log.info("task2 执行");
}, 1, TimeUnit.SECONDS);
}
结果:task1和task2都正常执行。

对于线程池的异常,需要自行主动进行捕获。
每天都在更新。。。。