微调控件 0.1微调
介绍 (Introduction)
I am amazed with the power of the T5 transformer model! T5 which stands for text to text transfer transformer makes it easy to fine tune a transformer model on any text to text task. Any NLP task event if it is a classification task, can be framed as an input text to output text problem.
T5变压器型号的强大功能令我惊讶! T5代表文本到文本转换转换器,可以轻松地在任何文本到文本任务上微调转换器模型。 任何NLP任务事件(如果是分类任务)都可以被构造为输入文本,以输出文本问题。
In this blog, I show how you can tune this model on any data set you have. In particular, I demo how this can be done on Summarization data sets. I have personally tested this on CNN-Daily Mail and the WikiHow data sets. The code is publicly available on my Github here.
在此博客中,我将展示如何根据您拥有的任何数据集调整此模型。 特别是,我演示了如何在摘要数据集上完成此操作。 我已经在CNN每日邮件和WikiHow数据集上对此进行了亲自测试。 该代码是我Github上公开可用这里 。
T5-small trained on Wikihow writes amazing summaries. See snippet below of actual text, actual summary and predicted summary. This model is also available on HuggingFace Transformers model hub here. The link provides a convenient way to test the model on input texts as well as a JSON endpoint.
在Wikihow上受过训练的T5小写摘要。 请参见下面的实际文本,实际摘要和预测摘要的摘要。 此模型在此处的 HuggingFace Transformers模型中心也可用。 该链接提供了一种方便的方法来测试输入文本以及JSON端点上的模型。
WikiHow Text: Make sure you've got all the cables disconnected from the back of your console,
especially the power cord., You'll need the straight end to be about 2-3 inches long.You will need a
large size paper clip for this method because it will need to go in about 1 and a half inches to
push the disc out., It's located on the left side of the console, right behind the vents.The eject
hole on an Xbox One S is located at the second hole on the left from the right corner and the third
hole up from the bottom. It can be more difficult to spot, so it's best to have a good amount of
light available. Doing so will cause the disc to pop out a little bit., Carefully pull the disc the
rest of the way out with your fingers. It might be a good idea to use a cloth or soft fabric to
protect the disc from fingerprints and scratching.
Actual Summary: Unplug all cables from your Xbox One.Bend a paper clip into a straight line.Locate the orange circle.Insert the paper clip into the eject hole.Use your fingers to pull the disc out.
Predicted Summary: Gather the cables.Place the disc on your console.Section the eject hole on the left side of the console.Pull out the disc.Remove from the back of the console.I run a machine learning consulting, Deep Learning Analytics. At Deep Learning Analytics, we are very passionate about using data science and machine learning to solve real world problems. Please reach out to us if you are looking for NLP expertise for your business projects. Original full story published on our website here.
我运行机器学习咨询,即Deep Learning Analytics 。 在深度学习分析中,我们非常热衷于使用数据科学和机器学习来解决现实世界中的问题。 如果您正在为业务项目寻找NLP专业知识,请与我们联系。 全文刊登在我们的网站上 。
T5变压器型号 (T5 Transformer Model)
T5 model which was released by google research adds the following to existing research:
Google研究发布的T5模型将以下内容添加到现有研究中:
It creates a clean version of the massive common crawl data set called Colossal Cleaned Common crawl(C4). This data set is s two orders of magnitude larger than Wikipedia.
它创建了称为Colossal Cleaned Common爬网(C4)的大规模通用爬网数据集的干净版本。 该数据集比Wikipedia大两个数量级 。
- It pretrains T5 on common crawl 它在普通爬网中对T5进行预训练
- It proposes reframing of all NLP tasks as an input text to output text formulation 它建议将所有NLP任务重新构架为输入文本,以输出文本格式
- It shows that fine tuning on different tasks — summarization, QnA, reading comprehension using the pretrained T5 and the text-text formulation results in state of the art results 它显示了对不同任务(摘要,QnA,使用预训练的T5和文本文本公式的阅读理解)进行微调的结果是最新的结果
- The T5 team also did a systematic study to understand best practices for pre training and fine tuning. Their paper details what parameters matter most for getting good results. T5小组还进行了系统的研究,以了解预训练和微调的最佳实践。 他们的论文详细介绍了哪些参数最重要以获得良好结果。
The figure below from T5 paper explains this input text to output text problem formulation.
T5纸的下图说明了此输入文本到输出文本问题的表述。

This blog from Google also explains the paper well. Lets deep dive into the code now!
Google的这个博客也很好地解释了这篇论文。 现在让我们深入研究代码!
T5微调管道 (T5 Fine Tuning Pipeline)
We will use the HuggingFace Transformers implementation of the T5 model for this task. A big thanks to this awesome work from Suraj that I used as a starting point for my code.
我们将使用T5模型的HuggingFace Transformers实现来完成此任务。 非常感谢Suraj 所做的出色工作 ,我将其用作代码的起点。
获取数据 (Getting the data)
To make it simple to extend this pipeline to any NLP task, I have used the HuggingFace NLP library to get the data set. This makes it easy to load many supporting data sets. The HuggingFace NLP library also has support for many metrics. I have used it rouge score implementation for my model.
为了简化将此管道扩展到任何NLP任务的过程,我使用了HuggingFace NLP库来获取数据集。 这样可以轻松加载许多支持数据集。 HuggingFace NLP库还支持许多指标。 我已经在模型中使用了胭脂分数实现。
The full code is available on my Github. For this demo, I will show how to process the WikiHow data set. The code though is flexible to be extended to any summarization task.
完整的代码可以在我的Github上找到 。 对于此演示,我将展示如何处理WikiHow数据集。 但是,该代码很灵活,可以扩展到任何摘要任务。
The Main Steps involved are:
涉及的主要步骤是:
- Load the Wikihow data. Please note for this dataset, two files need to be download to a local data folder 加载Wikihow数据。 请注意,此数据集需要将两个文件下载到本地数据文件夹中
- The dataset object created by NLP library can be used to see sample examples 由NLP库创建的数据集对象可用于查看示例示例
- We want to look at the average length of the text to decide if input can be tokenized to a max length of 512 我们要查看文本的平均长度,以确定输入是否可以标记为最大长度512
For Wikihow dataset, the average length of text is 660 words and average length of summary is 49. The graph below shows distribution of text length
对于Wikihow数据集,文本的平均长度为660个单词,摘要的平均长度为49。下图显示了文本长度的分布
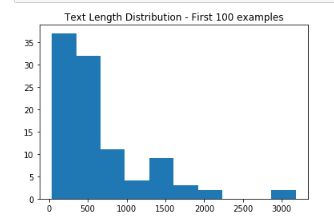
WikiHow text are usually 1–2 paragraphs instructional text on a subject. An example is shared below
WikiHow文本通常是关于某个主题的1-2段说明性文本。 下面是一个示例
WikiHow Text: Each airline has a different seat design, but you should find a lever on the side of
your seat in many cases. Pull it up to bring the seat back up. If you can't find the lever, ask a
flight attendant for help., Most airlines still use seat belts that only go across your lap. Locate
the buckle on one side and the latching device on the other. Straighten out each side, if necessary.
Insert the buckle into the latching device. Make sure you hear a click. Pull the belt until it's
snug across the tops of your thighs., Do this even if the captain turns off the “Fasten Seat Belts”
sign. If you decide to recline, make sure the belt stays snug across your lap. If you're using a
blanket, place it between the belt and your body.为数据创建Pytorch数据集类 (Creating a Pytorch Dataset Class for your data)
Next, we define a Pytorch Dataset class which can be used for any NLP data set type. For the text to text T5, we have to define the fields for input text and target text. Here the ‘text’ of the article is an input text and the ‘headline’ is its summary.
接下来,我们定义一个Pytorch Dataset类,该类可用于任何NLP数据集类型。 对于文本到文本T5,我们必须定义输入文本和目标文本的字段。 这里的文章“文本”是输入文本,“标题”是其摘要。
I have used an input target length of 512 tokens and an output summary length of 150. The output of the wikihow dataset class are :
我使用的输入目标长度为512个令牌,输出摘要长度为150。wikihow数据集类的输出为:
- source_ids: Tokenized input text length truncated/padded to a max length of 512 source_ids:标记化的输入文本长度被截断/填充为最大长度为512
- source_mask: Attention mask corresponding to the input token IDs source_mask:与输入令牌ID对应的注意掩码
- target_ids: Tokenized Target(summary) text length truncated/padded to a max length of 150 target_ids:令牌化的目标(摘要)文本长度被截断/填充为最大长度为150
- target_mask: Attention mask corresponding to the target token IDs target_mask:与目标令牌ID对应的注意掩码
My notebook on Github has sample code that you can use to play with the dataset class to check if the input is being encoded and decoded correctly.
我在Github上的笔记本上有示例代码,您可以将其与数据集类一起使用,以检查输入是否已正确编码和解码。
定义T5调谐器 (Defining the T5 tuner)
The T5 tuner is a pytorch lightning class that defines the data loaders, forward pass through the model, training one step, validation on one step as well as validation at epoch end.
T5调谐器是pytorch闪电类,它定义了数据加载器,向前通过模型,训练了一个步骤,一个步骤进行了验证以及在时代结束时进行了验证。
I have added a few features here to make it easier to use this for summarization:
我在此处添加了一些功能,以使其更易于使用:
I have used the NLP library to import the rouge_metric
我已经使用NLP库导入rouge_metric
- I have extended the code to generate predictions at the validation step and used those to calculate the rouge metric 我扩展了代码以在验证步骤中生成预测,并使用这些预测来计算胭脂度量
- Added WANDB as the logger 添加了WANDB作为记录器
训练模型 (Training the Model)
I decided to train a T5 small model. I used a batch size of 4 for both train and val and could train this model on GTX 1080Ti in about 4 hours. The model was trained for 2 epochs and WANDB logger showed good improvement in Rouge1 score and Val loss as the model trained.
我决定训练一个T5小型模型。 我使用的批次大小为4,同时用于训练和Val,可以在大约4个小时内在GTX 1080Ti上训练该模型。 该模型进行了2个时期的训练,并且WANDB记录器在训练模型后显示Rouge1得分和Val损失得到了很好的改善。
The full report for the model is shared here.
该模型的完整报告在此处共享。
测试模型 (Testing the Model)
I have uploaded this model to Huggingface Transformers model hub and its available here for testing. To test the model on local, you can load it using the HuggingFace AutoModelWithLMHeadand AutoTokenizer feature. Sample script for doing that is shared below.
我已将此模型上载到Huggingface Transformers模型中心,并可以在此处进行测试。 要在本地测试模型,可以使用HuggingFace AutoModelWithLMHeadand AutoTokenizer功能加载它。 共享示例代码如下。
The main drawback of the current model is that the input text length is set to max 512 tokens. This may be insufficient for many summarization problems. To overcome this limitation, I am working on a Longformer based summarization model. Will share a blog on that too soon!
当前模型的主要缺点是输入文本长度设置为最多512个令牌。 对于许多摘要问题而言,这可能是不够的。 为了克服此限制,我正在研究基于Longformer的摘要模型。 太早会分享博客了!
结论 (Conclusion)
T5 is an awesome model. It has made it easy to fine tune a Transformer for any NLP problem with sufficient data. In this blog I have created a code shell that can be adapted for any summarization problem.
T5是一个很棒的模型。 有了足够的数据,就可以轻松针对任何NLP问题对Transformer进行微调。 在此博客中,我创建了一个代码外壳程序,可以将其适用于任何摘要问题。
I hope you give the code a try and train your own models. Please share your experience in the comments below.
我希望您尝试一下代码并训练自己的模型。 请在下面的评论中分享您的经验。
At Deep Learning Analytics, we are extremely passionate about using Machine Learning to solve real-world problems. We have helped many businesses deploy innovative AI-based solutions. Contact us through our website here if you see an opportunity to collaborate.
在深度学习分析中 ,我们非常热衷于使用机器学习解决实际问题。 我们已经帮助许多企业部署了基于AI的创新解决方案。 如果您发现合作的机会,请通过此处的网站与我们联系。
翻译自: https://medium.com/@priya.dwivedi/fine-tuning-a-t5-transformer-for-any-summarization-task-82334c64c81
微调控件 0.1微调