在SQL Server中进行开发的有用的T-SQL技术
When we’re developing solutions, we can sometimes forget useful commands we can use in T-SQL that make it convenient to remove data, eliminate objects, or carefully remove data. We look at three of these commands with a few examples of where we might consider using them in development, or in rare production cases. While they may offer us speed and convenience in some cases, we also look at some situations where they may not be the best tool to use.
在开发解决方案时,有时我们会忘记可以在T-SQL中使用的有用命令,这些命令使删除数据,删除对象或仔细删除数据变得很方便。 我们看了其中的三个命令,并提供了一些示例,说明了在开发或生产案例中可能考虑使用它们的位置。 尽管在某些情况下它们可以为我们提供速度和便利,但在某些情况下,它们可能不是最好的工具。
在删除表中的每一行时截断表 (Truncating a table over deleting every row from the table)
Deleting data can be one of the most expensive DML operations and while we must do it in some situations such as deleting some records in a table, we do have an alternative with truncate if we need to remove every record in a table without each row removal being logged. In development, we will often have more freedom to truncate a table when we need to remove all rows, which will help us over using delete.
删除数据可能是最昂贵的DML操作之一,尽管在某些情况下(例如删除表中的某些记录)我们必须这样做,但是如果我们需要删除表中的每条记录而不删除每一行,我们确实有truncate的另一种选择被记录。 在开发中,当我们需要删除所有行时,我们通常会拥有更大的截断表的自由,这将有助于我们克服使用delete的麻烦。
In practice, one situation where deletes and truncates can be compared is transactional replication where we’ve defined a rule that on a reset, we want to remove every row of data in the destination table and repopulate the data from the source, as a load of inserts in our situation will perform better than updates (if the situation has much fewer updates than inserts, this would not be true). If we don’t want each row elimination tracked in the transaction log, a delete operation before repopulating the data becomes expensive, whereas a truncate operation does not. In this example, we’re still assuming a few things to prefer truncates over deletes or drop, re-creates and inserts:
在实践中,可以比较删除和截断的一种情况是事务复制,其中我们定义了一个规则,即在重置时,我们希望删除目标表中的每一行数据,并从源中重新填充数据,以作为负载。在我们的情况下,插入的性能将优于更新(如果情况的更新少于插入的情况,那将不是事实)。 如果我们不希望在事务日志中跟踪每一行的消除,那么在重新填充数据之前执行删除操作会变得很昂贵,而截断操作则不会。 在此示例中,我们仍然假设有一些事情比删节或删除,重新创建和插入更喜欢截断:
- We’re removing all the data in the destination table. 我们将删除目标表中的所有数据。
- Our source schema never changes in a manner that will impact the destination table. If this were to occur, we would want to either drop and recreate or make sure that we’re allowing DDL changes to pass. 我们的源模式永远不会以影响目标表的方式进行更改。 如果发生这种情况,我们将要么删除然后重新创建,要么确保我们允许DDL更改通过。
- We don’t want a logged record for every row elimination on the destination table. 我们不希望目标表上的每一行消除都有记录的记录。
While this command can be helpful in many situations involving development or full refreshes of a table, we should not use (or may be unable to use) the truncate command in some situations, such as the following:
尽管此命令在涉及表开发或表的完全刷新的许多情况下很有用,但在某些情况下,我们不应使用(或可能无法使用)truncate命令,例如:
- When we only want to remove a subset of our data from a table. The truncate command will remove every row of data in the table. 当我们只想从表中删除数据的子集时。 truncate命令将删除表中的每一行数据。
- When we want the individual row removals logged, such as tracking these removals in CDC even if we’re removing all the rows. If row removals from a table impact other row removals from another table, the command must be passed to the next table. We can use truncate here only if the second table contains the exact same data, otherwise, we’ll have to use delete. While truncate table faster because it does not use the transaction log in the exact same manner that deletes uses, this means we lose references to removals if we need only some removals of a full table to pass to another table. 当我们希望记录单个行的清除时,例如,即使要删除所有行,也要在CDC中跟踪这些清除。 如果从表中删除行影响从另一个表中删除其他行,则必须将命令传递给下一个表。 仅当第二张表包含完全相同的数据时,才可以在此处使用truncate,否则,我们将不得不使用delete。 尽管由于不使用与删除使用完全相同的方式来使用事务日志,所以可以更快地截断表,但是这意味着如果仅需要将整个表的部分删除传递给另一个表,则将丢失对删除的引用。
- When we want to remove all data from a table that are referenced by a foreign key, which holds true for the removal of referenced data. 当我们想要从外键引用的表中删除所有数据时,对于删除引用的数据而言,它适用。
- When we’re not (or the admins are not) willing to extend permissions to some developers that allow truncating the table, such as the ddl_admin or db_owner roles. If we’re the administrators deciding whether to extend these permissions, we should be aware that not all developers may understand references, so some tools can seem to help, but really introduce bugs. 当我们不愿意(或管理员不愿意)时,他们愿意将权限扩展给某些允许截断表的开发人员,例如ddl_admin或db_owner角色。 如果我们是由管理员来决定是否扩展这些权限,则应注意并非所有开发人员都可以理解引用,因此某些工具似乎有所帮助,但确实引入了错误。
- When the table schema changes and we want to reload all data as opposed to updating data in the table based on the new schema definition. In these situations, we want to drop the entire table, create the table with the new schema definition, and add the data. 当表模式更改时,我们希望重新加载所有数据,而不是根据新的模式定义更新表中的数据。 在这些情况下,我们要删除整个表,使用新的架构定义创建表,然后添加数据。
在delete语句中使用公用表表达式(CTE) (Using common table expressions (CTEs) in delete statements)
What about development situations where we want to remove a subset of records over removing all records? If we want to take extra caution about removing records, we can use a CTE for first filtering before removing records. In the below queries we see the work shown with a query that only uses a CTE for a select, then a delete statement from the same CTE.
在我们要删除记录的子集超过删除所有记录的开发情况下,情况又如何呢? 如果我们要特别注意删除记录,可以在删除记录之前使用CTE进行首次过滤。 在下面的查询中,我们看到的查询工作仅使用CTE进行选择,然后使用同一CTE的delete语句。
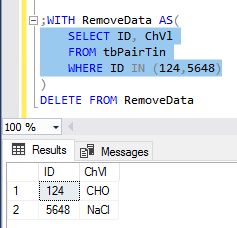
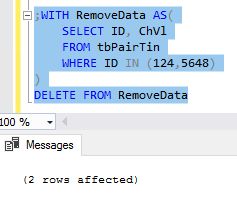
;WITH RemoveData AS(
SELECT ID, ChVl
FROM tbPairTin
WHERE ID IN (124,5648)
)
DELETE FROM RemoveData
Unlike truncate statements, delete statements may be costly due to errors or an error. If we know that we need to remove all data in a table, we’re less likely to make a mistake with a truncate since all data are being removed from a table. However, a delete statement can introduce errors by accident because if a filter is wrong, mistyped, or forgotten, records are wiped out and must be recovered. Using CTEs add extra work but offers two benefits to delete statements:
与截断语句不同,由于错误或错误,删除语句的代价可能很高。 如果我们知道需要删除表中的所有数据,则由于从表中删除了所有数据,因此不太可能因截断而出错。 但是,删除语句可能会偶然引入错误,因为如果过滤器错误,类型错误或被遗忘,则会清除记录并必须对其进行恢复。 使用CTE会增加工作量,但删除语句有两个好处:
- They raise awareness about what’s being removed by slowing urgency (which I’ve frequently observed is a root of many errors). A developer must first write the select, wrap it, then use the delete statement. If a developer must request that a DBA reverse a delete, the first question DBAs often ask is “what checks were in place?” or “what validation was used?” Using BEGIN TRANs, CTEs, or other validation checks look careful, whereas running a delete statement without any checks looks less careful. This is built into the CTE, as we can simply use the select within the CTE. 他们提高了对通过降低紧急程度而要删除的内容的意识(我经常观察到这是许多错误的根源)。 开发人员必须首先编写选择,包装它,然后使用delete语句。 如果开发人员必须要求DBA撤消删除操作,则DBA经常会问的第一个问题是“进行了哪些检查?” 或“使用了什么验证?” 使用BEGIN TRAN,CTE或其他验证检查看起来很仔细,而运行没有任何检查的delete语句看起来不太仔细。 这是内置在CTE中的,因为我们可以简单地在CTE中使用选择。
- A common delete technique used to reduce errors is to remove the data, then query the table to validate. The CTE structure makes this easy, as we have the select already written. I would still suggest using a begin transaction with a commit or rollback transaction and a check prior to committing. 一种用于减少错误的常用删除技术是删除数据,然后查询表以进行验证。 由于我们已经编写了选择,因此CTE结构使此操作变得容易。 我仍然建议在提交之前使用带有提交或回滚事务以及检查的开始事务。
- Due to a CTE’s structure, we can run the query inside of the CTE before executing the delete. In the above code, for instance, we can highlight the query within the CTE, then check the data. In fact, all CTE deletes can re-use the same below format where the query for removal is dropped within the parenthesis: 由于CTE的结构,我们可以在执行删除之前在CTE内部运行查询。 例如,在上面的代码中,我们可以在CTE中突出显示查询,然后检查数据。 实际上,所有删除CTE都可以重新使用以下相同格式,其中删除查询放在括号内:
;WITH RemoveData AS(
---- query here
)
DELETE FROM RemoveData
While this does raise awareness and adds a convenient check in place, it does require some extra effort on the part of the developers.
尽管这确实提高了知名度并添加了方便的检查方法,但开发人员确实需要付出额外的努力。
通过模式删除不再需要的所有开发表。 (Dropping all development tables by schema that are no longer required.)
If we’re testing a set of tables for a proof-of-concept and we don’t intend to keep the tables in our development, the below procedure will drop all tables by a schema. If we validate our proof-of-concept, we can retain the tables or migrate them to our default or permanent schema; if we invalidate our proof-of-concept, we can remove all the tables. This procedure also makes it easy when we’re demoing concepts to teams and we create tables during a presentation under a demonstration schema for easy later removal. Finally, if we keep table backups for when we change lookup data or other smaller data sets in production and throughout our environments, we can use other tables schemas for these backups and drop them later after our testing is complete (a rare production use-case).
如果我们要测试一组表以进行概念验证,并且不打算将这些表保留在我们的开发中,则以下过程将按模式删除所有表。 如果我们验证概念验证,则可以保留表或将其迁移到我们的默认或永久模式; 如果我们使概念验证无效,则可以删除所有表。 当我们将概念演示给团队并在演示过程中的演示模式下创建表时,使用此过程也很容易,以便以后删除。 最后,如果当我们在生产环境中以及整个环境中更改查找数据或其他较小数据集时保留表备份,则可以将其他表模式用于这些备份,并在测试完成后将其删除(罕见的生产用例) )。
CREATE PROCEDURE stpDropAllTables
@schema VARCHAR(50)
AS
BEGIN
DECLARE @sql NVARCHAR(MAX) = ''
SELECT
@sql += 'DROP TABLE ' + QUOTENAME(schema_name(schema_id)) + '.' + QUOTENAME([name]) + '
'
FROM sys.tables
WHERE schema_name(schema_id) = @schema
EXEC sp_executesql @sql
END
While it is bad practice to use keywords when naming tables or schemas, this is unfortunately common. The drop statement wraps the schema and table name within brackets using the QUOTENAME function to prevent this situation. In the below example, we create a schema and table that are both keywords and drop them successfully:
虽然在命名表或模式时使用关键字是一种不好的做法,但不幸的是,这很普遍。 drop语句使用QUOTENAME函数将模式和表名包装在方括号中,以防止出现这种情况。 在下面的示例中,我们创建一个都是关键字的架构和表,并将其成功删除:
CREATE SCHEMA [key]
CREATE TABLE [key].[Value] (ID INT)
EXEC stpDropAllTables 'key'
If you are the architect or the designer and have control, it is best practice to avoid using keywords for naming objects, but this will help in those situations where we’re required to use them by architects or clients who do not care for following best practices.
如果您是建筑师或设计师并拥有控制权,则最佳做法是避免使用关键字来命名对象,但这在那些不希望遵循最佳操作的建筑师或客户要求我们使用它们的情况下会有所帮助实践。
With this, we can develop on a schema and only keep objects we use. Otherwise, we can remove all objects by our development (or other named) schema.
这样,我们就可以在模式上进行开发,并且仅保留我们使用的对象。 否则,我们可以通过我们的开发(或其他命名)模式删除所有对象。
参考资料 (References)
- Restrictions on truncate table 截断表的限制
- The logging behavior of the delete command from Microsoft Microsoft的delete命令的日志记录行为
- Reserved keywords in T-SQL T-SQL中的保留关键字
- Microsoft on the truncate table command Microsoft在truncate table命令上
翻译自: https://www.sqlshack.com/useful-t-sql-techniques-for-development-in-sql-server/