hadoop基础
FileSystem使用
核心类 org.apache.hadoop.fs.FileSystem 文件系统类 抽象类
//静态方法创建对象
public static FileSystem newInstance(URI uri,Configuration conf,String user)
/*
参数一 URI 分布式文件系统 HDFS的资源地址 NN地址 hdfs://linux01:8020
参数二 Configuration 用户自定义参数设置 副本数 3 物理切块的大小 128M
参数三 user 客户端用户名
*/
/*
org.apache.hadoop.fs.FileSystem 文件系统类 抽象类
静态方法获取对象(子类对象)
public static FileSystem newInstance(URI uri,Configuration conf,String user)
URI uri: 统一资源标识符 协议://
url统一资源定位符 www.baidu.com
只要是网络相关的 都是uri包括url
迅雷下载 百度网盘 邮件发送 mailto: jdbc连接
分布式文件系统 HDFS的资源地址 NN地址
hdfs://linux01:8020
构造方法
public URI uri
Configuration conf:用户自定义参数设置 副本数 3 物理切块的大小 128M
如果不设置 使用默认设置
String user: 用户名 root
*/
public class Demo01_FileSystem {
public static void main(String[] args) throws URISyntaxException, IOException, InterruptedException {
//文件系统的客户端连接对象
URI uri = new URI("hdfs://linux01:8020");
//配置对象 没有进行配置 使用默认配置
Configuration con = new Configuration();
//用户名
String user = "root";
//通过静态方法 获取 分布式文件系统对象
FileSystem fs = FileSystem.newInstance(uri, con, user);
System.out.println(fs);
}
}
常用方法
public void copyFromLocalFile(Path src, Path dst) 将本地文件上传到文件系统
public void copyFromLocalFile(boolean delSrc, Path src, Path dst)
public void copyToLocalFile(Path src, Path dst) 将文件系统上的文件下载到本地
public void copyToLocalFile(boolean delSrc, Path src, Path dst)
public FileStatus[] listStatus(Path f) 列出目录下所有的内容 包括文件 文件夹
public RemoteIterator listFiles(Path f, boolean recursive)列出目录下所有的文件
public FSDataOutputStream create(Path f, boolean overwrite) 获取字节输出流 向文件中写数据
public FSDataOutputStream append(Path path) 向指定的文件路径中追加写入数据
public FSDataInputStream open(Path f) 获取字节输入流 读取文件中数据
获取文件系统对象工具类
public class HDFSUtils {
private HDFSUtils(){}
public static FileSystem getFileSystem() throws Exception {
//文件系统的客户端连接对象
URI uri = new URI("hdfs://linux01:8020");
//配置对象 没有进行配置 使用默认配置
Configuration con = new Configuration();
//用户名
String user = "root";
//通过静态方法 获取 分布式文件系统对象
FileSystem fs = FileSystem.newInstance(uri, con, user);
return fs;
}
}
上传文件
/*
public void copyFromLocalFile(Path src, Path dst) 将本地文件上传到文件系统
public void copyFromLocalFile(boolean delSrc, Path src, Path dst)
boolean delSrc:是否删除源文件 true删除 false则不删除
Path src:数据源 本地系统上的文件
Path dst:数据目的 文件系统
1.创建FileSystem对象
2.调用方法上传文件到分布式文件系统
3.关闭资源
*/
public class Demo02_FileSystem {
public static void main(String[] args) throws Exception {
//通过工具类获取对象
FileSystem fileSystem = HDFSUtils.getFileSystem();
/*
public void copyFromLocalFile(Path src, Path dst) 将本地文件上传到文件系统
数据源:本地文件 d:\\mm.jpg
数据目的:分布式文件系统 /
*/
//上传并改名
Path src = new Path("d:\\mm.jpg");
Path dest = new Path("/java/meimei.jpg");
fileSystem.copyFromLocalFile(true,src,dest);
fileSystem.close();
}
}
下载文件
/*
将文件系统上的文件下载到本地
public void copyToLocalFile(Path src, Path dst)
public void copyToLocalFile(boolean delSrc, Path src, Path dst)
boolean delSrc: 是否删除数据源 true删除 false不删除
Path src:数据源 文件系统
Path dst:数据目的 本地
注意:由于win和HDFS分布式兼容不好 需要安装Hadoop环境 不安装不能下载文件
解压 hadoop3.1.1 配置环境变量HADOOP_HOME 加入Path
需要重启idea 可能需要重启电脑
*/
public class Demo03_FileSystem {
public static void main(String[] args) throws Exception {
//通过工具类获取对象
FileSystem fs = HDFSUtils.getFileSystem();
// Path src = new Path("/mm.jpg");
// Path dest = new Path("d:\\");
//将文件系统中的文件 下载到本地 自动生成.crc的检验文件
// fs.copyToLocalFile(src,dest);
Path src = new Path("/mm.jpg");
Path dest = new Path("d:\\meimei.jpg");
下载并改名
// fs.copyToLocalFile(src,dest);
/*
public void copyToLocalFile(boolean delSrc, Path src, Path dst, boolean useRawLocalFileSystem)
参数1:是否删除源文件
参数2:数据源
参数3:数据目的
参数4:是否使用本地文件系统 true则不生成.crc文件
*/
fs.copyToLocalFile(false,src,dest,true);
fs.close();
}
}
遍历文件
/*
public FileStatus[] listStatus(Path f) 列出指定目录下所有的内容 包括文件 文件夹
*/
public class Demo04_FileSystem {
public static void main(String[] args) throws Exception {
//获取对象
FileSystem fs = HDFSUtils.getFileSystem();
//获取根目录下所有内容 文件 文件夹
FileStatus[] fileStatusArr = fs.listStatus(new Path("/"));
//增强for循环遍历
for(FileStatus file : fileStatusArr){
// System.out.println(file);
//判断是否是文件夹
boolean b = file.isDirectory();
//判断是否是文件
boolean b2 = file.isFile();
//获取文件路径
Path path = file.getPath();
if(b){
System.out.println("文件夹:"+path);
}else{
System.out.println("文件:"+path);
}
}
}
}
/*
public RemoteIterator listFiles(Path f, boolean recursive)列出目录下所有的文件 只获取文件
方法参数
Path f:路径
boolean recursive:是否递归遍历 true false
方法返回值
RemoteIterator 迭代器
hasNext() 判断是否有元素
next() 获取元素
LocatedFileStatus 分布式文件系统上的文件对象 可以获取文件的信息
获取文件大小 副本个数 block块个数 大小等等
Path getPath() 获取路径
long getLen() 获取文件的字节数
short getReplication()获取副本个数
long getBlockSize() 获取block块的大小
BlockLocation[] getBlockLocations() 获取block块数组
BlockLocation 物理切块对象
String[] getHosts() 获取block块在主机的位置
String[] getNames() 获取block块在主机的名称端口
long getLenth() 获取每个切块的大小
long getOffset() 获取偏移量
*/
public class Demo05_FileSystem {
public static void main(String[] args) throws Exception {
FileSystem fs = HDFSUtils.getFileSystem();
//调用方法获取根目录下的所有内容
RemoteIterator it = fs.listFiles(new Path("/"), true);
while (it.hasNext()) {
LocatedFileStatus file = it.next();
// System.out.println(file.getPath());
//获取路径
Path path = file.getPath();
//获取文件的字节数
long len = file.getLen();
System.out.println("文件大小:" + len * 1.0 / 1024 / 1024 + "M");
//获取文件的副本
short s = file.getReplication();
System.out.println("副本个数:" + s);
//获取block大小
long blockSize = file.getBlockSize();
System.out.println("block块大小:" + blockSize * 1.0 / 1024 / 1024 + "M");
//获取block的数组
BlockLocation[] blockLocations = file.getBlockLocations();
System.out.println("block块个数:" + blockLocations.length);
//遍历物理切块数组
for (BlockLocation b : blockLocations) {
//获取物理切块的主机地址
String[] hosts = b.getHosts();
System.out.println(Arrays.toString(hosts));
String[] names = b.getNames();
System.out.println(Arrays.toString(names));
long length = b.getLength();
System.out.println("block大小:" + length * 1.0 / 1024 / 1024 + "M");
long offset = b.getOffset();
System.out.println("偏移量:" + offset);
}
System.out.println("------------------------------");
}
}
}
写数据
/*
public FSDataOutputStream create(Path f, boolean overwrite) 获取字节输出流 向文件中写数据
boolean overwrite:如果文件存在 是否覆盖 true 覆盖 false不覆盖
*/
public class Demo06_FileSystem {
public static void main(String[] args) throws Exception {
FileSystem fs = HDFSUtils.getFileSystem();
//获取写数据的字节输出流
FSDataOutputStream out = fs.create(new Path("/1.txt"), true);
out.write("hello world\r\n".getBytes());
out.write("hello boys ".getBytes());
out.write("hello girls ".getBytes());
out.close();
fs.close();
}
}
/*
追加写入数据
FSDataOutputStream append(Path path) 向指定的文件路径中追加写入数据
*/
public class Demo07_FileSystem {
public static void main(String[] args) throws Exception {
FileSystem fs = HDFSUtils.getFileSystem();
//向文件中追加写入数据
FSDataOutputStream out = fs.append(new Path("/1.txt"));
out.write("hello aaa\r\n".getBytes());
out.write("hello bbb\r\n".getBytes());
out.write("hello ccc\r\n".getBytes());
out.close();
fs.close();
}
}
读数据
/*
public FSDataInputStream open(Path f) 获取字节输入流 读取文件中数据
*/
public class Demo08_FileSystem {
public static void main(String[] args) throws Exception {
FileSystem fs = HDFSUtils.getFileSystem();
//获取字节输入流 读取文件中数据
FSDataInputStream in = fs.open(new Path("/1.txt"));
// byte[] bytes = new byte[1024];
// int len =0;
// while((len = in.read(bytes))!=-1){
// System.out.println(new String(bytes,0,len));
//
// }
//一行一行读取数据
InputStreamReader isr = new InputStreamReader(in);
//创建缓冲流
BufferedReader br = new BufferedReader(isr);
// String s = br.readLine();
String line = null;
while((line = br.readLine())!=null){
System.out.println(line);
}
br.close();
fs.close();
}
}
/*
seek和skip方法补充
*/
public class Demo09_FileSystem {
public static void main(String[] args) throws Exception {
FileSystem fs = HDFSUtils.getFileSystem();
//获取字节输入流 读取文件中数据
FSDataInputStream in = fs.open(new Path("/1.txt"));
//跳过几个字节
// in.skip(1);
//指定指针标记读取
in.seek(0);
int read = in.read();
System.out.println(read);
in.close();
fs.close();
}
}
其他方法
//DistributedFileSystem
public class Demo10_FileSystem {
public static void main(String[] args) throws Exception {
FileSystem fileSystem = HDFSUtils.getFileSystem();
fileSystem.delete(new Path("/1.txt"),true); //删除
fileSystem.mkdirs(new Path("/aaa/bbb") ); //创建文件夹
fileSystem.exists(new Path("/aaa/1.txt")); //判断路径是否存在
//...
fileSystem.close();
}
}
小文件合并
由于Hadoop擅长存储大文件,因为大文件的元数据信息比较少,如果Hadoop集群当中有大量的小文件,那么每个小文件都需要维护一份元数据信息,会大大的增加集群管理元数据的内存压力,所以在实际工作当中,如果有必要一定要将小文件合并成大文件进行一起处理在我们的HDFS的shell命令模式下,可以通过命令行将很多的hdfs文件合并成一个大文件下载到本地.
hdfs dfs -getmerge /aaa/* ./abc.txt
既然可以在下载的时候将这些小文件合并成一个大文件一起下载,那么肯定就可以在上传的时候将小文件合并到一个大文件里面去
FileSystem fs = HDFSUtils.getFS();
FSDataOutputStream out = fs.create(new Path("/aaa/big.txt"));
LocalFileSystem local = FileSystem.getLocal(new Configuration());
FileStatus[] fileStatuses = local.listStatus(new Path("file:///d:\\input"));
for (FileStatus fileStatus : fileStatuses) {
FSDataInputStream in = local.open(fileStatus.getPath());
IOUtils.copy(in,out);
IOUtils.closeQuietly(in);
}
IOUtils.closeQuietly(out);
参数配置
使用Configuration类进行配置
Configuration conf = new Configuration();
// 修改存储的副本个数 5 name value
conf.set( "dfs.replication", "5");
// 修改物理切块的大小
conf.set("dfs.blocksize", "64m");
使用配置文件进行配置
在resources下创建配置文件hdfs-site.xml
dfs.replication
5
dfs.blocksize
64m
HDFS文件限额配置
在多人共用HDFS的环境下,配置设置非常重要。特别是在Hadoop处理大量资料的环境,如果没有配额管理,很容易把所有的空间用完造成别人无法存取。Hdfs的配额设定是针对目录而不是针对账号,可以让每个账号仅操作某一个目录,然后对目录设置配置。
hdfs文件的限额配置允许我们以文件个数,或者文件大小来限制我们在某个目录下上传的文件数量或者文件内容总量,以便达到我们类似百度网盘网盘等限制每个用户允许上传的最大的文件的量。
hdfs dfs -count -q -h /aaa #查看配额信息
数量限额
hdfs dfs -mkdir -p /aaa
hdfs dfsadmin -setQuota 2 /aaa #给该文件夹下设置最多上传两个文件 ,发现只能上传一个
hdfs dfsadmin -clrQuota /aaa # 清除限额
空间大小限额
在设置空间配额时,设置空间至少是block_size*3大小
hdfs dfsadmin -setSpaceQuota 4k /aaa #限制空间大小4KB
hdfs dfs -put a.txt /aaa #上传失败
生成任意大小文件命令
dd if=/dev/zero of=1.txt bs=1M count=2 #生成任意大小文件 bs*count
清除空间配额限制
hdfs dfsadmin -clrSpaceQuota /aaa
hdfs的安全模式
安全模式是hadoop的一种保护机制,用于保证集群中的数据块的安全性。当集群启动的时候,会首先进入安全模式。当系统处于安全模式时会检查数据块的完整性。
假设我们设置的副本数(即参数dfs.replication)是3,那么在datanode上就应该有3个副本存在,假设只存在2个副本,那么比例就是2/3=0.666。hdfs默认的副本率0.999。我们的副本率0.666明显小于0.999,因此系统会自动的复制副本到其他dataNode,使得副本率不小于0.999。如果系统中有5个副本,超过我们设定的3个副本,那么系统也会删除多于的2个副本。在安全模式状态下,文件系统只接受读数据请求,而不接受删除、修改等变更请求。在,当整个系统达到安全标准时,HDFS自动离开安全模式。
dfs.namenode.safemode.threshold-pct 副本率 默认值 0.999f
dfs.namenode.safemode.extension 默认值30000 检查完成后 30秒后退出安全模式
安全模式操作命令
hdfs dfsadmin -safemode get #查看安全模式状态
hdfs dfsadmin -safemode enter #进入安全模式
hdfs dfsadmin -safemode leave #离开安全模式
原理介绍
上传数据流程
网络拓扑及机架感知
网络拓扑
节点距离:两个节点到达共同父节点的距离和
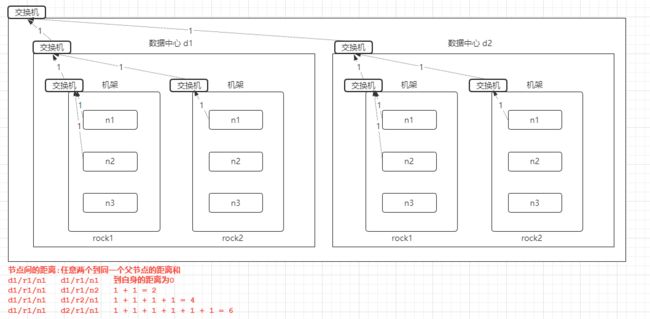
机架感知 ( 副本节点的选择 )
例如:500个节点,上传数据my.tar.gz,副本数为3,
根据机架感知,副本数据存储节点的选择。
BlockPlacementPolicyDefault
官方注释
the 1st replica is placed on the local machine,
otherwise a random datanode. The 2nd replica is placed on a datanode
that is on a different rack. The 3rd replica is placed on a datanode
which is on a different node of the rack as the second replica.
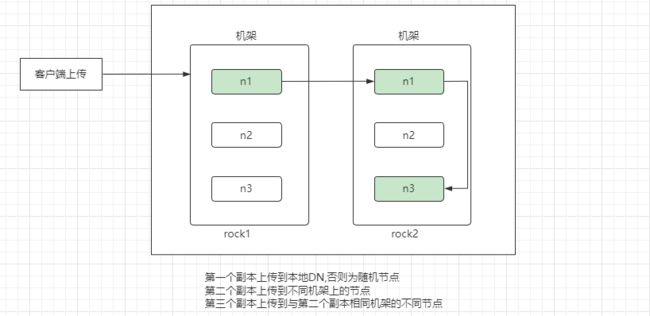
上传流程

Block
HDFS中的文件在物理上是分块存储的,即分成Block;
block在Hadoop不同版本大小不同:
Hadoop1.x:64M
Hadoop2.x:128M
Pipeline,中文翻译为管道。这是HDFS在上传文件写数据过程中采用的一种数据传输方式。
客户端将数据块写入第一个数据节点,第一个数据节点保存数据之后再将块复制到第二个数据节点,后者保存后将其复制到第三个数据节点。
为什么datanode之间采用pipeline线性传输,而不是一次给三个datanode拓扑式传输呢?
因为数据以管道的方式,顺序的沿着一个方向传输,这样能够充分利用每个机器的带宽,避免网络瓶颈和高延迟时的连接,最小化推送所有数据的延时。
ACK (Acknowledge character )即是确认字符,在数据通信中,接收方发给发送方的一种传输类控制字符。表示发来的数据已确认接收无误。
Packet
Packet是Client端向Datanode,或者DataNode的PipLine之间传输数据的基本单位,默认64kB.
Chunk
Chunk是最小的Hadoop中最小的单位,是Client向DataNode或DataNode的PipLne之间进行数据校验的基本单位,默认512Byte,因为用作校验(自己校验自己),故每个chunk需要带有4Byte的校验位。
所以世纪每个chunk写入packet的大小为516Byte,真实数据与校验值数据的比值为128:1。
下载数据流程

IO操作过程中难免会出现数据丢失或脏数据,数据传输得量越大出错得几率越高。校验错误最常用得办法就是传输前计算一个校验和,传输后计算一个校验和,两个校验和如果不相同就说明数据存在错误,比较常用得错误校验码是CRC32.
hdfs写入的时候计算出校验和,然后每次读的时候再计算校验和。要注意的一点是,hdfs每固定长度就会计算一次校验和,这个值由io.bytes.per.checksum指定,默认是512字节。
DataNode节点如何保证数据的完整性
1.当datanode读取Block的时候,会计算CheckSum
2.如果计算后的CheckSum,与Block创建时值不一样,说明Block已经损坏
3.客户端读取其他DataNode上的Block
4.常见的校验算法crc,md5等
5.DataNode在其文件创建后周期验证CheckSum(DataNode后台进程(DataBlockScanner))
如果客户端发现有block坏掉呢,会怎么恢复这个坏的块,主要分几步:
1.客户端在抛出ChecksumException之前会把坏的block和block所在的datanode报告给namenode
2.namenode把这个block标记为已损坏,这样namenode就不会把客户端指向这个block,也不会复制这个block到其他的datanode。
3.namenode会把一个好的block复制到另外一个datanode
4.namenode把坏的block删除掉
元数据信息管理
什么是元数据信息
元数据:描述数据的数据信息
HDFS中元数据分为两种
1.描述文件自身属性的元数据信息
2.描述文件与block之间映射的元数据信息
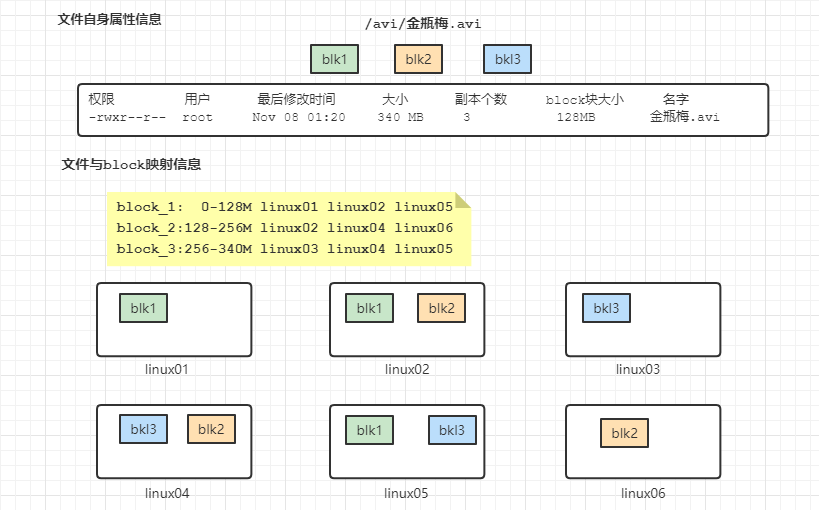
如何管理元数据信息
元数据信息就是虚拟目录的一个映射关系,如何保存这些信息.按存储形式分为内存元数据和元数据文件两种,分别存在内存和磁盘上。
内存元数据
为了保证用户操作元数据交互高效,延迟低,NameNode把所有的元数据都存储在内存中,我们叫做内存元数据。内存中的元数据是最完整的,包括文件自身属性信息、文件块位置映射信息。但是内存的致命问题是,断点数据丢失,数据不会持久化。因此NameNode又辅佐了元数据文件来保证元数据的安全完整。
元数据文件
有两种:fsimage镜像文件,edit编辑日志
fsimage镜像文件:是内存元数据的一个持久化的检查点。但是fsimage中仅包含Hadoop文件系统中文件自身属性相关的元数据信息,但不包含文件块位置的信息。文件块位置信息只存储在内存中,是由datanode启动加入集群的时候,向namenode进行数据块的汇报得到的,并且后续间断指定时间进行数据块报告。
持久化的动作是数据从内存到磁盘的IO过程,并且fsimae文件会很大(GB级别的很常见)。如果所有的更新操作都往fsimage文件中添加,这样会导致系统运行的十分缓慢会.对namenode正常服务造成一定的影响,不能频繁的进行持久化。
edit编辑日志:为了避免两次持久化之间数据丢失的问题,又设计了Edits log编辑日志文件。文件中记录的是HDPS所有更改操作(文件创建,删除或修改)的日志,文件系统客户端执行的更改操作首先会被记录到edits文件中。
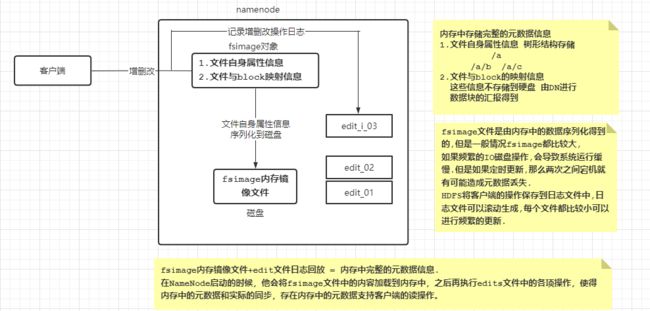
当HDFS集群运行一段时间后,就会出现下面一些问题:
1. edits logs因操作记录过多会变的很大,
2. fsimage因间隔时间长将会变得很旧;
3. namenode重启会花费很长时间,因为有很多改动要
从edits log合并到fsimage文件上;
4. 如果频繁进行fsimage持久化,又会影响NN正常服
务,毕竟I0操作是-种内存到磁盘的耗精力操作.
因此为了克服上述问题,需要一个易于管理的机制来帮助我们减小edit logs文件的大小和得到一个最新的fsimage文件,这样也会减小在NameNode,上的压力。
checkpoint机制
通过Secondary Namenode,每隔一段时间将Name Node的元数据更新并备份,然后返回fsimage给Name Node,供其下次启动时读取.
当集群启动时,NN和SNN都会启动,NN启动后会读取最新的fsimage文件,读到较新的元数据信息,同时还会读取最新的日志信息,根据日志信息的内容“回滚”上一次开机时的操作信息,这样即可保证当前的元数据信息是完整正确的
SNN会隔一段时间就去NN下载其fsimage文件和众多edits文件,下载到SNN的本机上,然后将fsimage反序列化到内存中,同时“回放”众多日志文件中的操作信息,更新补全元数据,元数据更新完毕后,SNN就会将该元数据对象序列化到本地磁盘中,然后再将该元数据对象发送给NN,供其下一次开机读取
checkpoint过程

checkpint相关参数设置(了解)
core-site.xml
dfs.namenode.checkpoint.period
--两次检查点创建之间的固定时间间隔,默认3600,即1小时。
dfs.namenode.checkpoint.txns
--未检查的事务数量。若没检查事务数达到这个值,也触发一次checkpoint,1,000,000。
dfs.namenode.checkpoint.check.period
--standby namenode检查是否满足建立checkpoint的条件的检查周期。默认60,即每1min检查一次。
dfs.namenode.num.checkpoints.retained
--在namenode上保存的fsimage的数目,超出的会被删除。默认保存2个。
dfs.namenode.num.checkpoints.retained
--最多能保存的edits文件个数,默认为1,000,000.
dfs.ha.tail-edits.period
--standby namenode每隔多长时间去检测新的Edits文件。只检测完成了的Edits, 不检测inprogress的文件。