深度学习实战——强化学习与王者荣耀(腾讯开悟)
忆如完整项目/代码详见github:https://github.com/yiru1225(转载标明出处 勿白嫖 star for projects thanks)
目录
系列文章目录
一、强化学习综述与PPO算法解析
1.强化学习综述
1.1 强化学习简介
1.2 强化学习的要素与架构
1.3 强化学习应用场景
1.4 强化学习算法综述
2.PPO算法
2.1 PPO算法简介
2.2 PPO算法详解
传统策略梯度算法
自然策略梯度算法
信赖域策略优化算法(TRPO)
近端策略优化算法(PPO)
二、腾讯MOBA强化学习框架解构
1.论文简介
2.框架详解
三、参考资料
系列文章目录
本系列博客重点在深度学习相关实践(有问题欢迎在评论区讨论指出,或直接私信联系我)。
第一章 深度学习实战——不同方式的模型部署(CNN、Yolo)_如何部署cnn_@李忆如的博客
第二章 深度学习实战——卷积神经网络/CNN实践(LeNet、Resnet)_@李忆如的博客-CSDN博客
第三章 深度学习实战——循环神经网络(RNN、LSTM、GRU)_@李忆如的博客-CSDN博客
第四章 深度学习实战——模型推理优化(模型压缩与加速)_@李忆如的博客-CSDN博客
第五章 深度学习实战——强化学习与王者荣耀(腾讯开悟)
梗概
本篇博客主要介绍强化学习与腾讯AI Lab在MOBA(王者荣耀)中提出的强化学习系统框架。
一、强化学习综述与PPO算法解析
由于开悟平台上的实践(智能体训练与对战)实际上是强化学习的经典任务,故本章先对强化学习的核心概念做一定引入,并对本次实验开悟使用的算法PPO进行解析。
1.强化学习综述
1.1 强化学习简介
强化学习是机器学习的一个分支领域,旨在设计智能体(agent)能够通过与环境的交互学习最优行为策略。与监督学习和无监督学习不同,强化学习并不依赖于标记好的训练数据或明确的目标函数,而是通过与环境的反馈进行学习,即强化学习是第三种机器学习范式。
Reinforcement learning is learning what to do—how to map situations to actions——so as to maximize a numerical reward signal. ----- Richard S. Sutton and Andrew G. Barto 《Reinforcement Learning: An Introduction II》
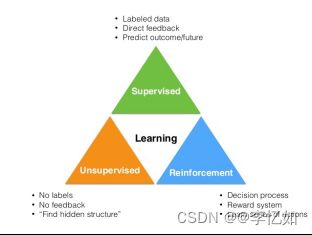
图1 监督学习-无监督学习-强化学习划分
在强化学习基本流程中,智能体通过观察环境的状态,采取行动,然后接收环境的奖励或惩罚来评估行动的好坏。目标是通过与环境的交互,使智能体学会选择能够最大化累积奖励的行动序列,即学习到最优的策略。强化学习的关键在于将长期的累积奖励最大化,而不仅仅是针对单个行动的即时奖励。
综上,我们可以总结出强化学习的核心特点如下:
- 没有监督者,只有一个奖励信号
- 反馈是延迟的而非即时
- 具有时间序列性质
- 智能体的行为会影响后续的数据
1.2 强化学习的要素与架构
强化学习系统一般包含四个核心要素如下:
- 状态(State):环境的描述,反映了智能体与环境的交互情况。
- 行动(Action):智能体在某个状态下采取的动作。
- 奖励(Reward):环境根据智能体的行动给予的反馈信号,表示行动的好坏。
- 策略(Policy):智能体在给定状态下选择行动的策略,可以是确定性策略(确定选择一个行动)或概率性策略(选择行动的概率分布)。
Tips:强化学习系统还包含“智能体(agent)”与“环境(environment)”两大部分。
强化学习系统核心部分详解如表2:
表2 强化学习核心部分详解
| Ⅰ、策略(Policy): 策略定义了智能体对于给定状态所做出的行为,即一个从状态到行为的映射,事实上状态包括了环境状态和智能体状态,这里我们是从智能体出发的,也就是指智能体所感知到的状态。因此我们可以知道策略是强化学习系统的核心,因为我们完全可以通过策略来确定每个状态下的行为。我们将策略的特点总结为以下三点:
|
| Ⅱ、奖励(Reward): 奖励信号定义了强化学习问题的目标,在每个时间步骤内,环境向强化学习发出的标量值即为奖励,它能定义智能体表现好坏,类似人类感受到快乐或是痛苦。因此我们可以体会到奖励信号是影响策略的主要因素。我们将奖励的特点总结为以下三点:
|
| Ⅲ、价值(Value): 价值(函数),与奖励的即时性不同,价值函数是对长期收益的衡量,而不仅仅盯着眼前的奖励。结合强化学习的目的,我们能很明确地体会到价值函数的重要性,事实上在很长的一段时间内,强化学习的研究就是集中在对价值的估计。我们将价值函数的特点总结为以下三点:
|
| Ⅳ、环境(模型) 模型(Model),是对环境的模拟,如当给出了状态与行为后,有了模型我们就可以预测接下来的状态和对应的奖励。但我们要注意的一点是并非所有的强化学习系统都需要有一个模型,因此会有基于模型(Model-based)、不基于模型(Model-free)两种不同的方法,不基于模型的方法主要是通过对策略和价值函数分析进行学习。我们将模型的特点总结为以下两点:
|
结合表2,一个实际的例子如图2所示,对应的元素/部分如表3所示:
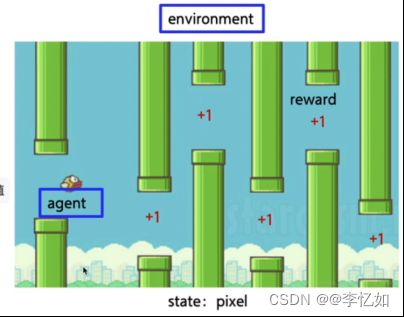
图2 强化学习示例
表3 示例-元素/部分对应
| 名称 |
对应上图2中的内容 |
| agent |
鸟 |
| environment |
鸟周围的环境,水管、天空(包括小鸟本身) |
| state |
拍个照(目前的像素) |
| action |
向上向下动作 |
| reward |
距离(越远奖励越高) |
根据强化学习定义及元素/部分解析,我们可以总结其核心架构如图3所示:
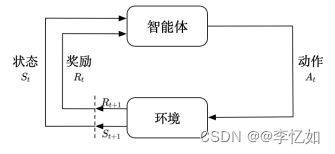
图3 强化学习核心架构
分析:如图3所示,强化学习基本流程即从当前的状态st出发,在做出一个行为At之后,对环境产生了一些影响,它首先给agent反馈了一个奖励信号Rt,接下来我们的agent可以从中发现一些信息,进而进入一个新的状态,再做出新的行为,形成一个循环。
1.3 强化学习应用场景
强化学习在众多领域有着广泛的应用,它提供了一种学习最优决策的框架,使得智能体能够通过与环境的交互不断优化自己的行为,逐步提高性能,常见应用场景如图4所示,一些具体的应用及其核心实现如图5所示:
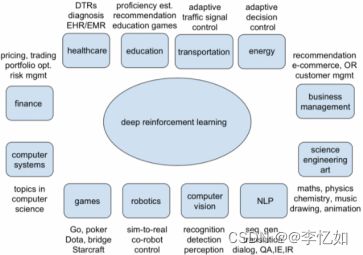
图4 强化学习常见应用场景
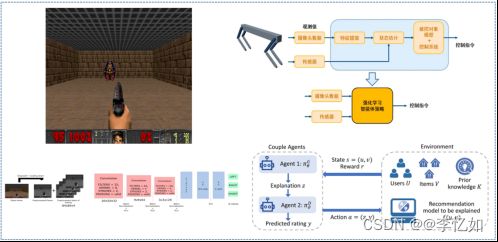
图5 强化学习具体应用及其核心实现样例
1.4 强化学习算法综述
强化学习算法按照不同的标准可以有几种划分规则如图表1,一些常见算法如图6所示:
图表1 强化学习算法划分规则
| Ⅰ、按照环境是否已知划分:免模型学习(Model-Free) vs 有模型学习(Model-Based)
Tips:一般情况下,环境都是不可知的,所以这里主要研究无模型问题。 |
| Ⅱ、按照学习方式划分:在线策略(On-Policy) vs 离线策略(Off-Policy)
|
| Ⅲ、按照学习目标划分:基于策略(Policy-Based)和基于价值(Value-Based)。
Tips:更为厉害的方法是二者的结合:Actor-Critic,Actor根据概率做出动作,Critic根据动作给出价值,从而加速学习过程,常见的有A2C,A3C,DDPG等。
|

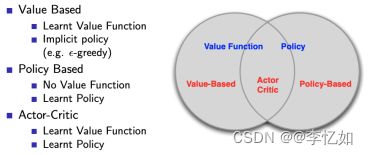
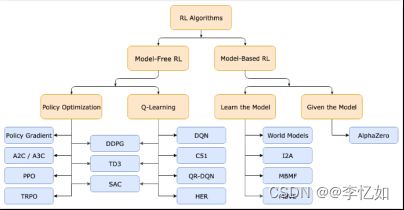
图6 强化学习常见算法
2.PPO算法
参考论文:Proximal Policy Optimization Algorithms (arxiv.org)
由于本次实验平台(开悟)是基于PPO(Proximal Policy Optimization)算法训练智能体,故我们在本部分仅以PPO算法作为强化学习算法特例做解析,根据1.4综述(图表1规则)与图6划分,我们可以看到PPO算法为Model-Free下的基于策略的强化学习算法。
2.1 PPO算法简介
PPO由OPENAI在2017年提出,核心原理在学习并优化策略以最大化累积奖励。其是基于TRPO(Trust Region Policy Optimization)算法的改进,通过一种称为“近端策略优化”(proximal policy optimization)的方式来更新策略。目标是在每次更新时保持策略的改变幅度在一个可接受的范围内,以确保稳定性和可靠性。
PPO算法的主要思想是通过两个关键的步骤来优化策略:采样数据和策略更新。
- 采样数据:在PPO算法中,智能体与环境进行交互来收集数据。通过执行当前策略,并根据环境的反馈(奖励信号)收集一定数量的轨迹或经验。
- 策略更新:使用采样数据来更新策略。PPO算法的核心是定义一个目标函数,该函数衡量当前策略与新策略之间的差异,并通过最大化目标函数来更新策略。
PPO算法的优点包括简单易实现、相对较快的收敛速度以及对超参数不敏感。它已被广泛应用于各种强化学习任务,包括机器人控制、游戏玩耍和自动驾驶等领域。
Tips:需要注意的是,PPO算法有多个变体,如PPO1和PPO2,它们在具体策略更新步骤和近端剪切参数的定义上略有不同,但核心思想都是基于近端策略优化进行策略更新。
2.2 PPO算法详解
2.1中简单介绍了PPO算法的核心原理与流程,其详细演变过程如图7所示:

图7 PPO算法演变过程
-
传统策略梯度算法
首先根据图6与2.1我们知道PPO为概率梯度强化算法,传统的策略梯度算法与神经网络的优化思路相同,通过参数θ优化目标函数,梯度近似如式1,更新规则如式2:
式1 传统梯度RL算法梯度近似
![]()
式2 传统梯度RL算法更新规则
分析:在传统策略梯度强化学习算法中,根据式1可以完全计算梯度(已知策略![]() ),并使用式2更新对θ调整优化,直至迭代到最优策略。
),并使用式2更新对θ调整优化,直至迭代到最优策略。
补充:常见两种策略为Softmax策略和高斯策略。实际问题中损失函数定义为式3:
![]()
式3 传统梯度RL算法损失函数(实际问题)
-
自然策略梯度算法
在传统的策略梯度算法中,我们根据目标函数梯度和步长更新策略权重,这样的更新过程可能会出现两个常见的问题:
1、过冲(Overshooting):更新错过了奖励峰值并落入了次优策略区域
2、下冲(Undershooting):在梯度方向上采取过小的更新步长会导致收敛缓慢
为缓解/解决以上两个问题,自然策略梯度算法被提出,有两个核心优化如下,权重更新方案如式4所示,算法伪代码如图8所示:
1、考虑到策略对局部变化的敏感性,策略梯度由逆Fisher矩阵校正,而传统的梯度方法假定更新为欧几里得距离。
2、更新步长α具有适应梯度和局部敏感性的动态表达式,确保无论参数化如何,策略变化幅度为。在传统方法中,α通常设置为一些标准值,如0.1或0.01。
![]()
式4 自然策略梯度算法 - 权重更新方案

图8 自然策略梯度算法流程伪代码
-
信赖域策略优化算法(TRPO)
根据自然策略梯度算法的流程分析,实际上它存在以下三个主要缺陷:
1、近似值可能会违反KL约束,从而导致分析得出的步长过大,超出限制要求
2、矩阵![]() 的计算时间太长,是O(N^3)复杂度的运算
的计算时间太长,是O(N^3)复杂度的运算
3、我们没有检查更新是否真的改进了策略。由于存在大量的近似过程,策略可能没有优化
因此,信赖域策略优化算法(TRPO)被提出,相对自然策略梯度算法,TRPO主要有三个改进,每个改进都解决了原始算法中的一个问题。TRPO的核心是利用单调改进定理,验证更新是否真正改进了我们的策略。
Ⅰ、共轭梯度法(conjugate gradient method)
我们知道自然策略梯度算法中计算Fisher矩阵是一个耗时且数值不稳定的过程。而引入共轭梯度法,这是一个近似![]() 乘积的数值过程,这样我们就可以避免计算逆矩阵。共轭梯度通常在||步内收敛,从而可以处理大矩阵。
乘积的数值过程,这样我们就可以避免计算逆矩阵。共轭梯度通常在||步内收敛,从而可以处理大矩阵。
Ⅱ、线搜索(line search)
虽然自然梯度策略中提供了给定KL散度约束的最佳步长,但由于存在较多的近似值,实际上可能不满足该约束。
TRPO 通过执行线搜索来解决此问题,通过不断地迭代减小更新的大小,直到第一个不违反约束的更新。这个过程可以看作是不断缩小信任区域,即我们相信更新可以实际改进目标的区域,线搜索伪代码如图9所示:

图9 线搜索伪代码
Ⅲ、改进检查
在TRPO中,我们并没有假设更新会提高替代优势![]() ,而是真正检查了它。尽管实际计算时需要根据旧策略计算优势,以及使用重要性抽样来调整概率,会花费一些时间,但验证更新是否真正改进了策略是有必要的。
,而是真正检查了它。尽管实际计算时需要根据旧策略计算优势,以及使用重要性抽样来调整概率,会花费一些时间,但验证更新是否真正改进了策略是有必要的。
-
近端策略优化算法(PPO)
TRPO算法解决了许多与自然策略梯度相关的问题,并获得了在RL任务上的广泛采用。但是,TRPO仍然存在一些缺点,特别是:
1、无法处理大参数矩阵:尽管使用了共轭梯度法,TRPO仍然难以处理大的 Fisher矩阵,即使它们不需要求逆
2、二阶优化很慢:TRPO的实际实现是基于约束的,需要计算上述Fisher矩阵,这大大减慢了更新过程。此外,我们不能利用一阶随机梯度优化器,例如ADAM
3、算法复杂:TRPO很难解释、实现和调试。当训练没有产生预期的结果时,确定如何提高性能可能会很麻烦
故PPO被提出,常见(变体)为PPO Penalty和PPO Clip(均在上述参考论文中提出)。
Ⅰ、PPO Penalty
TRPO在理论分析上推导出与KL散度相乘的惩罚项,但在实践中,这种惩罚往往过于严格,只产生非常小的更新。PPO通过设置目标散度 的方式解决了这个问题,希望我们的
的方式解决了这个问题,希望我们的
每次更新都位于目标散度附近的某个地方。目标散度应该大到足以显著改变策略,但又应该小到足以使更新稳定。
每次更新后,PPO都会检查更新的大小。如果最终更新的散度超过目标散度的 1.5倍,则下一次迭代我们将加倍β来更加重惩罚。相反,如果更新太小,我们将β减半,从而有效地扩大信任区域,算法伪代码如图10所示:
Tips:加倍与减半是基于启发式确定的,而非数学证明的结果。

图10 PPO Penalty伪代码
分析:与自然策略梯度和TRPO算法相比,PPO更容易实现。同时,我们可以使用流行的随机梯度下降算法(如ADAM等)执行更新,并在更新太大或太小时调整惩罚。
Ⅱ、PPO Clip
Clipped PPO是目前最流行的PPO的变体,也是我们说PPO时默认的变体。PPO Clip相比于PPO Penalty效果更好,也更容易实现。与PPO Penalty不同,与其费心随着时间的推移改变惩罚,PPO Clip直接限制策略可以改变的范围。我们重新定义了替代优势如式5:
式5 PPO Clip替代优势
其中,clip为截断函数,当重要性采样超出规定的上或下限后,函数会返回对应的上或下限,如图11所示:
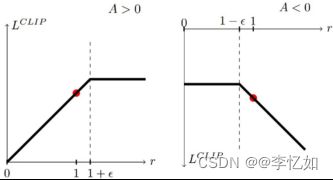
图11 clip替代优势示意图
二、腾讯MOBA强化学习框架解构
第一章主要针对强化学习的原理、架构、应用、算法进行了综述,并以开悟的基础算法PPO为例详解了强化学习算法。而在开悟平台实践与报告前,在本章我们将会针对平台底层的强化学习框架(腾讯AI Lab MOBA框架)进行论文的对照与解析。
参考论文:Mastering Complex Control in MOBA Games with Deep RL
1.论文简介
这个问题在MOBA游戏的1v1对战中,涉及的状态和动作空间比传统的1v1游戏(如围棋和Atari游戏系列)要复杂得多,这使得搜索具有人类水平表现的策略非常困难。为此腾讯提出了一个深度强化学习框架,从系统和算法的角度来解决这个问题。论文提出的算法包括几种新颖的策略,包括控制依赖解耦、动作屏蔽、目标注意力和dual-clip PPO。在提出的Actor-Critic网络的训练下,在《王者荣耀》中,训练后的AI智能体能够在完整的1v1对战中击败顶级职业人类玩家。

图12 Go 1v1与MOBA 1v1复杂度对比
2.框架详解

图13 腾讯MOBA强化学习系统/框架总览
如图13所示,腾讯提出的MOBA 1v1强化学习系统设计包括四个主要模块:强化学习学习器、人工智能服务器、调度模块和内存池。这个设计旨在解决MOBA 1v1等复杂代理控制问题引入的随机梯度的高方差,需要较大的批量大小以加快训练速度。
- AI服务器:负责游戏环境和AI模型之间的交互逻辑,通过自我对弈生成回合,并使用镜像策略进行采样对手策略。基于从游戏状态提取的特征,使用Boltzmann探索预测英雄动作,即基于Softmax分布进行采样。采样的动作然后被发送到游戏核心进行执行。执行后,游戏核心连续返回相应的奖励值和下一个状态。
- 调度模块:调度模块是一个服务器,与同一台机器上的多个AI服务器绑定。它从AI服务器收集数据样本,包括奖励、特征、动作概率等。这些样本首先被压缩和打包,然后发送到内存池。
- 内存池:内存池也是一个服务器。其内部实现为内存高效的循环队列用于数据存储。它支持长度不同的样本,并基于生成的时间进行数据采样。
- RL学习器:RL学习器是一个分布式训练环境。为了加速使用大批量大小的策略更新,多个RL学习器从相同数量的内存池中并行获取数据。RL学习器中的梯度通过环形全局归约算法进行平均。为了减少IO成本,从RL学习器训练的模型以对等方式快速同步到AI服务器。

图14 框架核心算法架构
系统/框架算法设计如图14,首先,网络使用卷积、全连接和全连接(FC)将图像特征fi、向量特征fu和游戏状态信息fg(可观察到的游戏状态)编码为编码hi、hu和hg。其中注意力分布计算如式6:
![]()
式6 注意力分布计算
论文中没有使用我们上文提到的经典PPO,而是设计了改进后的Dual-clip PPO。在经典的PPO算法(式5)的基础上,它进一步剪辑了比值rt(θ),以使其有一个下界c,支持大规模的分布式训练,如式7所示:
![]()
式7 Dual-clip PPO核心原理
至此,开悟平台底层的深度强化学习框架核心部分均已解析完成。
三、参考资料
1.强化学习(一):简介——什么是强化学习?_Woody2357的博客-CSDN博客
2.强化学习入门:基本思想和经典算法 - 张浩在路上 (imzhanghao.com)
3.Proximal Policy Optimization (PPO) 算法理解:从策略梯度开始 - 知乎 (zhihu.com)
4.lecture_13_advanced_pg.pdf (berkeley.edu)