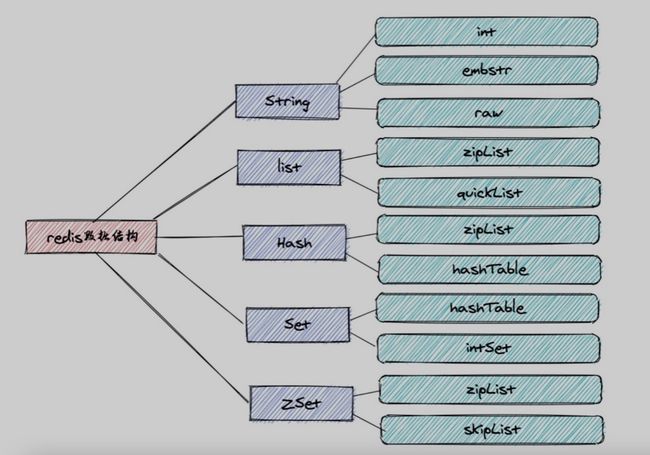
Redis数据结构
0、引言
了解Redis的数据结构才能更好地使用Redis处理数据。
Redis具有多种数据结构,并且Redis的底层是用C语言实现的,本文将详细介绍Redis中:动态字符串的机制、intset、Dict、ZipList、QuickList、RedisObject、String、List、Set、ZSET和Hash结构的底层原理。
1、动态字符串SDS
字符串是Redis日常开发中最常用的一种数据结构,Redis中保存的Key是字符串,value往往是字符串或者字符串的集合。
Redis构建了一种新的字符串结构,称为简单动态字符串(Simple Dynamic String),简称SDS。 Redis是C语言实现的,其中SDS是一个结构体,源码如下:

该结构的字符串支持动态扩容:

说明:对于SDS的扩容功能,如果新增的字符串比较小,那就申请扩展后的2倍+1,(+1是为了\0,字符串的长度len是不包括\0的) ,如果较大,2倍就太浪费了,就在扩展后加1M+1即可。
此外:之所以要进行扩展额外的空间,是因为申请内存非常消耗性能,如果每次扩容都新申请将非常低效,因此要提前预留多余空间。
2、 intset
IntSet是Redis中set集合的一种实现方式,基于整数数组来实现,并且具备长度可变、有序等特征。 为了方便查找,Redis会将intset中所有的整数按照升序依次保存在contents数组中。
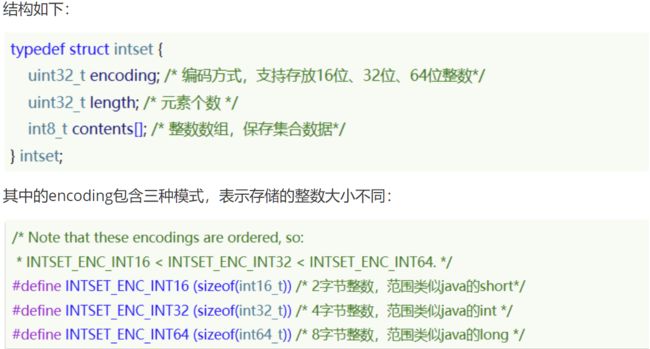
类型自动升级:
我们向其中添加一个数字:50000,这个数字超出了int16_t的范围,intset会自动升级编码方式到合适的大小。
总结:
Redis会确保Intset中的元素唯一、有序
具备类型升级机制,可以节省内存空间
底层采用二分查找方式来查询
3、Dict
Redis是一个键值型(Key-Value Pair)的数据库,我们可以根据键实现快速的增删改查。而键与值的映射关系正是通过Dict来实现的。
Dict由三部分组成,分别是:哈希表(DictHashTable)、哈希节点(DictEntry)、字典(Dict)

当我们向Dict添加键值对时,Redis首先根据key计算出hash值(h),然后利用 h & sizemask来计算元素应该存储到数组中的哪个索引位置。
Dict的rehash
Dict中的HashTable就是数组结合单向链表的实现,底层是数组加链表来解决哈希冲突。
不管是扩容还是收缩,必定会创建新的哈希表,导致哈希表的size和sizemask变化,而key的查询与sizemask有关。因此必须对哈希表中的每一个key重新计算索引,插入新的哈希表,这个过程称为rehash。
4、RedisObject
Redis中的任意数据类型的键和值都会被封装为一个RedisObject,也叫做Redis对象,源码:
/*
* Redis 对象
*/
typedef struct redisObject {
// 类型 4bits
unsigned type:4;
// 编码方式 4bits
unsigned encoding:4;
// LRU 时间(相对于 server.lruclock) 24bits
unsigned lru:22;
// 引用计数 Redis里面的数据可以通过引用计数进行共享 32bits
int refcount;
// 指向对象的值 64-bit
void *ptr;
} robj;
5、压缩列表ziplist 与 快速列表QuickList
ziplist:
ziplist 可以看做是一种压缩的双向链表,它的好处是更能节省内存空间,因为它所存储的内容都是在连续的内存区域当中的、并且列表的节点之间不是通过指针连接,而是记录上一节点和本节点长度来寻址。
适用于:对象元素不大,每个元素也不大 的情况,尤其是在插入、删除等频繁操作时。
因为:
连续内存,插入的时间复杂度为O(n),并且需要移动其他元素的位置,特别是在列表的头部或尾部插入/删除元素时,ziplist就显得非常吃力。
ziplist是按照元素顺序存储的,如果需要按照值进行查找,ziplist的效率会受到很大的影响.
QuickList:
快速列表是ziplist和linkedlist的混合体,是将linkedlist按段切分,每一段用ziplist来紧凑存储,多个ziplist之间使用双向指针链接。
QuickList的特点:
是一个节点为ZipList的双端链表
节点采用ZipList,解决了传统链表的内存占用问题
控制了ZipList大小,解决连续内存空间申请效率问题
中间节点可以压缩,进一步节省了内存
6、String
底层实现方式:动态字符串sds 或者 long
String的内部存储结构⼀般是sds(Simple Dynamic String,可以动态扩展内存)。
但是如果⼀个String类型的value的值是数字,那么Redis内部会把它转成long类型来存储,从⽽减少内存的使用。并将字符串对象的编码设置为 int
应用场景:
- 缓存:string 最常用的就是缓存功能,会将一些更新不频繁但是查询频繁的数据缓存起来,以此来减轻 DB 的压力。
- 计数器:可以用来计数,通过 incr 操作,如统计网站的访问量、文章访问量等。
7、List
底层实现
list 是有序可重复列表,和 Java 的 LinkedList 比较像,可以通过索引查询;插入删除速度快。底层使用quicklist,它是一个双向链表,而且是一个基于ziplist的双向链表,quicklist的每个节点都是一个ziplist,结合了双向链表和ziplist的优点。
使用场景:
- 消息队列:Redis 的 list 是有序的列表结构,可以实现阻塞队列,使用左进右出的方式。Lpush 用来生产 从左侧插入数据,Brpop 用来消费,用来从右侧 阻塞的消费数据。
- 数据的分页展示: lrange 命令需要两个索引来获取数据,这个就可以用来实现分页,可以在代码中计算两个索引值,然后来 redis 中取数据。
- 可以用来实现粉丝列表以及最新消息排行等功能。
8、Set
Redis的Set与Java的Set类似:无需不可重复。
底层实现:
- 集合对象的编码可以是 intset 或者 hashtable 。
- 如果集合对象保存的所有元素都是整数值并且保存的元素数量不超过 512 个,则使用 intset 编码(有序了);否则使用 hashtable(无序);
应用场景:
- 标签:可以将博客网站每个人的标签用 set 集合存储,然后还按每个标签 将用户进行归并。
- 存储好友/粉丝:set 具有去重功能;还可以利用set并集功能得到共同好友之类的功能。
9、 跳表skiplist
跳表的原理可以参考http://t.csdn.cn/Ibh6l 的文章。概括来说是一种空间换时间的策略,通过给一个链表添加多级的索引,减少链表查询时的时间复杂度。Redis自己实现了跳跃表来来当做有序集合(zset)的底层实现, 他的查询复杂度平均O(logN), 最坏O(N)
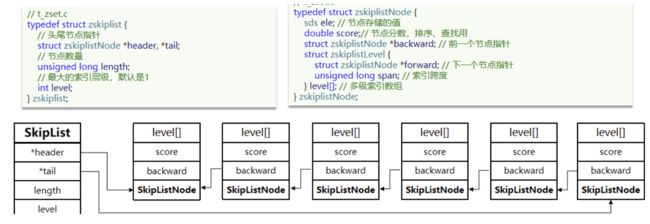
10、ZSET(有序集合)
底层实现:
zset底层数据结构必须满足键值存储、键必须唯一、可排序:
当ziplist作为zset的底层存储结构时候:
每个集合元素使用两个紧挨在一起的 ziplist 节点来保存,第一个节点保存元素的成员,第二个元素保存元素的分值。
当skiplist作为zset的底层存储结构的时候:使用skiplist按序保存元素及分值,使用dict来保存元素和分值的映射关系。
ZSet中每一个元素都需要指定一个score值(它可以是一个浮点数类型的数字,用于表示该元素的权重或者排名)和member值。
例如,在以下示例中,我们创建了一个名为 myzset 的 zset,并向其中添加三个元素,它们的分值分别为 0.5、0.8 和 1.2:
> ZADD myzset 0.5 "one" 0.8 "two" 1.2 "three" (integer) 3然后,我们可以使用
ZRANGE命令按照分值从小到大的顺序查看元素:> ZRANGE myzset 0 -1 WITHSCORES 1) "one" 2) "0.5" 3) "two" 4) "0.8" 5) "three" 6) "1.2"
应用场景:
- 排行榜:有序集合最常用的场景。如新闻网站对热点新闻排序,比如根据点击量、点赞量等。
- 带权重的消息队列:重要的消息 score 大一些,普通消息 score 小一些,可以实现优先级高的任务先执行。
11、Hash
类似于java的HashMap,可以存储多个键值对之间的映射
底层实现: ziplist 或者 hashtable
应用场景:
- 购物车场景:可以以用户的 id 为 key ,商品的 id 为存储的 field ,商品数量为键值对的value,这样就构成了购物车的三个要素。