Javac编译原理:基本结构和工作原理
Javac编译器
文章目录
- Javac编译器
-
- 简介
- 基本结构
-
- 如何编译程序
- 工作原理
-
- 词法分析器
- 语法分析器
- 语义分析器
- 代码生成器
简介
javac是一种编译器,能将一种语言规范转化成另一种语言规范
编译器通常是将便于人理解的语言规范转换成容易理解的语言规范,如C都是将源码直接编译成目标机器码,这个目标机器码是CPU直接执行的指令集合,这些指令集合也就是底层的一种语言规范,机器能够直接识别这种语言规范,虽然这种机器码执行起来高效,但是对人不友好,开发这个代码的成本远远高于省下的机器的执行成本
从某种程度上来说,有了编译器才有了程序语言的繁荣,编译器是人类和机器沟通的一个纽带
javac的任务:将Java源代码语言先转换成JVM能识别的一种语言,再由JVM将JVM语言转化成当前机器能识别的机器语言
Java语言的执行和平台无关,也成就了Java语言的繁荣

从图中可以看出,Javac的任务就是将Java源码编译成Java字节码,也就是JVM能够识别的二进制码,(.java - .class),这些二进制数字是有格式的,只有JVM能正确识别
基本结构
Javac编译器的作用:将符合Java语言规范的源代码转化成符合Java虚拟机规范的Java字节码
如何编译程序
Javac主要四个模块:词法分析器、语法分析器、语义分析器和代码生成器
词法分析:一个字节为一节的读,找出语法关键词,最终从源代码中找出一些规范化的Token流
语法分析:检查关键词组合在一起是否符合Java语言规范,形成一个符合Java语法规范的抽象语法树,抽象语法树是一个结构化的语法表达形式,作用:把语言的主要词法用一个结构化的形式组织在一起,这颗语法树在之后可以按照新的规则重新组织,也是编译器的关键所在
语义分析:把一些难懂的、复杂的语法转换成更加简单的语法,结果就是将复杂语法转换成简单语法,还有注解,形成一个注解过后的抽象语法树,这棵语法树更加接近目标语言的语法规则
代码生成:通过字节码生成器生成字节码,根据经过注解的抽象语法树生成字节码,也就是将一个数据结构转换成另一个数据结构,代码生成器的结果就是生成符合Java虚拟机规范的字节码

工作原理
词法分析器
作用:将Java源文件的字符流转变成对应的Token流
类结构
Javac主要词法分析器的接口类是
package com.sun.tools.javac.parser;
public interface Lexer {
它的默认实现类是
package com.sun.tools.javac.parser;
public class Scanner implements Lexer {
Scanner会逐个读取Java源文件的单个字符,然后解析出符合Java语言规范的Token序列,所涉及的类:

由Factory生成了两个接口的实现类:Scanner和JavacParser,这两个类负责整个词法分析的过程控制;
JavacParser:规定哪些词是符合Java语言规范规定的
Scanner:读取和归类不同词法的操作
Token:规定了所有Java语言的合法关键词
Names:存储和表示解析后的词法
词法分析过程是在JavacParser的该方法中完成的:
/** CompilationUnit = [ { "@" Annotation } PACKAGE Qualident ";"] {ImportDeclaration} {TypeDeclaration}
*/
public JCTree.JCCompilationUnit parseCompilationUnit() {
Token firstToken = token;
JCModifiers mods = null;
boolean consumedToplevelDoc = false;
boolean seenImport = false;
boolean seenPackage = false;
ListBuffer<JCTree> defs = new ListBuffer<>();
//解析修饰符
if (token.kind == MONKEYS_AT)
mods = modifiersOpt();
//解析package声明
if (token.kind == PACKAGE) {
int packagePos = token.pos;
List<JCAnnotation> annotations = List.nil();
seenPackage = true;
if (mods != null) {
checkNoMods(mods.flags & ~Flags.DEPRECATED);
annotations = mods.annotations;
mods = null;
}
nextToken();
JCExpression pid = qualident(false);
accept(SEMI);
JCPackageDecl pd = toP(F.at(packagePos).PackageDecl(annotations, pid));
attach(pd, firstToken.comment(CommentStyle.JAVADOC));
consumedToplevelDoc = true;
defs.append(pd);
}
boolean checkForImports = true;
boolean firstTypeDecl = true;
while (token.kind != EOF) {
if (token.pos <= endPosTable.errorEndPos) {
// error recovery 跳过错误字符
skip(checkForImports, false, false, false);
if (token.kind == EOF)
break;
}
if (checkForImports && mods == null && token.kind == IMPORT) {
seenImport = true;
//解析import声明
defs.append(importDeclaration());
} else {
Comment docComment = token.comment(CommentStyle.JAVADOC);
if (firstTypeDecl && !seenImport && !seenPackage) {
docComment = firstToken.comment(CommentStyle.JAVADOC);
consumedToplevelDoc = true;
}
//SEMI(";"),
if (mods != null || token.kind != SEMI)
mods = modifiersOpt(mods);
if (firstTypeDecl && token.kind == IDENTIFIER) {
ModuleKind kind = ModuleKind.STRONG;
if (token.name() == names.open) {
kind = ModuleKind.OPEN;
nextToken();
}
//Token.INDENTIFIER 用于表示用户定义的名称
if (token.kind == IDENTIFIER && token.name() == names.module) {
if (mods != null) {
checkNoMods(mods.flags & ~Flags.DEPRECATED);
}
defs.append(moduleDecl(mods, kind, docComment));
consumedToplevelDoc = true;
break;
} else if (kind != ModuleKind.STRONG) {
reportSyntaxError(token.pos, Errors.ExpectedModule);
}
}
JCTree def = typeDeclaration(mods, docComment);
if (def instanceof JCExpressionStatement statement)
def = statement.expr;
defs.append(def);
if (def instanceof JCClassDecl)
checkForImports = false;
mods = null;
firstTypeDecl = false;
}
}
JCTree.JCCompilationUnit toplevel = F.at(firstToken.pos).TopLevel(defs.toList());
if (!consumedToplevelDoc)
attach(toplevel, firstToken.comment(CommentStyle.JAVADOC));
if (defs.isEmpty())
storeEnd(toplevel, S.prevToken().endPos);
if (keepDocComments)
toplevel.docComments = docComments;
if (keepLineMap)
toplevel.lineMap = S.getLineMap();
this.endPosTable.setParser(null); // remove reference to parser
toplevel.endPositions = this.endPosTable;
return toplevel;
}
从源文件的一个字符开始,按照Java语法规范依次找出package、import、类定义、属性和方法定义,最后构建一个抽象语法树
Javac是如何分辨一个token的呢?
/** The factory to be used for abstract syntax tree construction.
*/
protected TreeMaker F;
/**
* Qualident = Ident { DOT [Annotations] Ident }
*/
public JCExpression qualident(boolean allowAnnos) {
JCExpression t = toP(F.at(token.pos).Ident(ident()));
while (token.kind == DOT) { //判断这个token是否token.DOT,如果是则读取整个package定义的类名
int pos = token.pos;
nextToken();
List<JCAnnotation> tyannos = null;
if (allowAnnos) {
//注解
tyannos = typeAnnotationsOpt();
}
t = toP(F.at(pos).Select(t, ident()));
if (tyannos != null && tyannos.nonEmpty()) {
t = toP(F.at(tyannos.head.pos).AnnotatedType(tyannos, t));
}
}
return t;
}
先根据Token.INDENTIFIER 的token创建一个JCIdent的语法节点,然后取下一个token,如果为DOT,则进入while循环读取整个路径
如何判断哪些字符组合是一个token则是在Scanner类中定义:
//每调用依次方法就会形成一个token
public void nextToken() {
prevToken = token;
if (!savedTokens.isEmpty()) {
token = savedTokens.remove(0);
} else {
token = tokenizer.readToken();
}
}
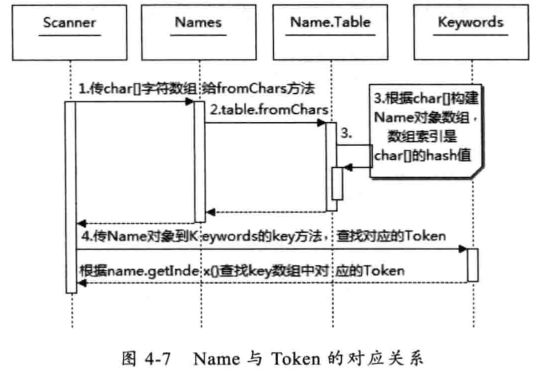
实际上在读取每个token时都需要一个转换过程,在java源码中的所有字符集合都要找到在com.sun.tools.javac.parser.INDENTIFIER中定义的对应关系,这个任务则是在com.sun.tools.javac.parser.Keywords中完成,Kaywords负责将所有字符集合对应到token集合中
字符集合到token转换相关的类关系:
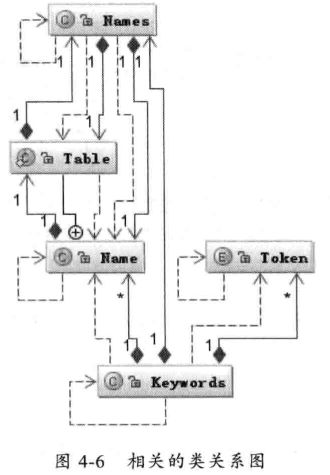
每个字符集合都是一个Name对象,所有的Name对象都存储在Name.Table这个内部类,这个类也就是对应的这个类的符号表,会将所有的元素按照他们的Token.name转化成name对象,然后建立Name对象和Token的对应关系,保存在Keyworks里的key数组,其他的所有字符集合则会被对应到Token.INDENTIFIER类型
语法分析器
作用:将Token流组建成更加结构化的语法树
语法树的规则
每个语法节点都会实现一个接口xxxTree,这个接口继承自com.sun.source.tree.Tree接口,例如IfTree语法节点表示一个if类型的表达式
每个语法节点都是com.sun.tools.javac.tree.JCTree的子类,并且会实现第一节点中的xxxTree接口类,这个类的名称类似于JCxxx
所有JCxxx 类都作为一个静态内部类定义在JCTree类中

JCTree类有三个重要的属性类
Tree tag :每个语法节点都会用一个整型常数表示,并且每个节点类型的数值都是在前一个的基础上+1,顶层节点TOPLEVEL是1,而IMPORT节点等于TOPLEVEL+1,也就是2
pos :也是一个整数,存储的是这个语法节点在源代码中的起始位置,一个文件的位置是0,-1代表不存在
type :表示这个节点是什么Java类型
例如之前的这个函数
public JCExpression qualident(boolean allowAnnos) {
JCExpression t = toP(F.at(token.pos).Ident(ident()));
...
}
调用了TreeMaker类,根据Name对象构建了一个JCIdent语法节点,如果包名是多级目录,将构建成JCFieldAccess语法节点,此节点也可以是嵌套关系
Package 节点解析完成之后进入while循环,首先解析importDeclaration,解析规则和package类似;解析节点之后构建语法树:
/** ImportDeclaration = IMPORT [ STATIC ] Ident { "." Ident } [ "." "*" ] ";"
*/
protected JCTree importDeclaration() {
int pos = token.pos;
nextToken();
boolean importStatic = false;
//检查是否有static关键字,如果有则设置标识,然后解析第一个类路径,是多级目录则继续读取下一个,并构建JCFiledAccess
if (token.kind == STATIC) {
importStatic = true;
nextToken();
}
JCExpression pid = toP(F.at(token.pos).Ident(ident()));
do {
int pos1 = token.pos;
accept(DOT);
//如果最后一个Token为*,则设置这个JCFieldAccess的Token名称为asterisk
if (token.kind == STAR) {
pid = to(F.at(pos1).Select(pid, names.asterisk));
nextToken();
break;
} else {
pid = toP(F.at(pos1).Select(pid, ident()));
}
} while (token.kind == DOT);
accept(SEMI);
//最后将这个解析的语法节点作为子结点构建在新创建的JCImport节点中
return toP(F.at(pos).Import(pid, importStatic));
}
JCImport语法树如图:

Import节点解析完成之后就是class的解析,类包括interface、class、enum,以class为例:
/** ClassDeclaration = CLASS Ident TypeParametersOpt [EXTENDS Type]
* [IMPLEMENTS TypeList] ClassBody
* @param mods The modifiers starting the class declaration
* @param dc The documentation comment for the class, or null.
*/
protected JCClassDecl classDeclaration(JCModifiers mods, Comment dc) {
//第一个token是这个类的关键词
int pos = token.pos;
accept(CLASS);
Name name = typeName();
//这个类的类型可选参数,将这个参数解析为JCTypeParameter语法节点
List<JCTypeParameter> typarams = typeParametersOpt();
JCExpression extending = null;
if (token.kind == EXTENDS) {
nextToken();
extending = parseType();
}
List<JCExpression> implementing = List.nil();
if (token.kind == IMPLEMENTS) {
nextToken();
implementing = typeList();
}
//对classBody的解析,也是按照变量定义解析、方法定义解析和内部类定义解析,结果保存在list集合
List<JCExpression> permitting = permitsClause(mods, "class");
List<JCTree> defs = classInterfaceOrRecordBody(name, false, false);
//最后将这些子节点添加到JCClassDecl这课class树种
JCClassDecl result = toP(F.at(pos).ClassDef(
mods, name, typarams, extending, implementing, permitting, defs));
attach(result, dc);
return result;
}
例如这一段代码:
public class YuFa {
int a;
private int c = a + 1;
public int getC() {
return c;
}
public void setC(int c) {
this.c = c;
}
}
这段代码对应的语法树:
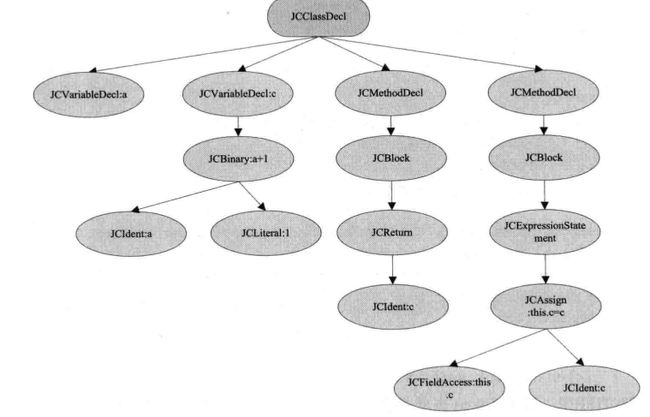
当这个类解析完成之后,会将这个类节点加到这个类对应的包路径的顶层节点也就是JCCompilationUnit,它持有以package 作为pid和JCClassDecl 的集合,这样整个.java文件就被解析完成
所举例代码对应的完整语法树:
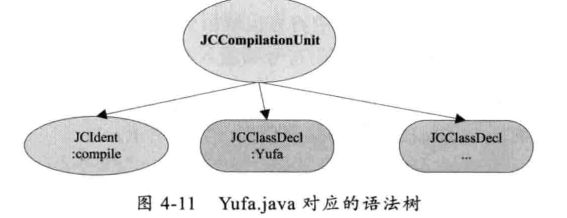
注意:所有语法节点的生成都是在TreeMaker类中完成,它实现了在JCTree.Factory 接口中定义的所有节点的构成方法
语义分析器
作用:处理语法树,例如添加默认的构造函数
类:com.sun.tools.javac.comp.Enter
主要完成以下两个步骤
将所有类中出现的符号输入到类自身的符号表中,所有类符号、类的参数类型符号(泛型参数类型)、超类符号和继承的接口类型符号等都存储到一个未处理的列表中
将这个未处理列表中所有的类都解析到各自的类符号列表中,这个操作是在MemberEnter.complete()中完成的
下一个步骤是处理annotation,这个步骤是由com.sun.tools.processing.JavacProssessingEnvironment完成的
再接下来是com.sun.tools.javac.comp.Attr,最重要的是检查语义的合法性并进行逻辑判断,如以下几点:
- 变量的类型是否匹配
- 变量在使用前是否已经完成初始化
- 能够推导出泛型方法的参数类型
- 字符串常量的合并
在这个步骤中除 Atr 之外还需要另外一些类来协助,如下所述。
- com.sun.tools.javac.comp.Check:辅助 Attr 类检查语法树中的变量类型是否正确,如二元操作符两边的操作数的类型是否匹配,方法返回的类型是否与接收的引用值类型匹配等。
- com.sun.tools.javac.comp. Resolve: 主要检查变量、方法或者类的访问是否合法、变量是否是静态变量、变量是否已经初始化等。
- com.sun.tools.javac.comp.ConstFold:常量折叠,这里主要针对字符串常量,会将一个字符串常量中的多个宇符串合并成一个字符串。
- com.sun.tools.javac.comp.Infer:帮助推导泛型方法的参数类型等
标注完成后由 com.sun.tools.javac.comp.Flow 类完成数据流分析,数据流分析主要完成如下工作:
- 检查变量在使用前是否都己经被正确赋值。除了 Java 中的原始类型,如 int.long、byte、double、char、float,都会有默认的初始化值,其他像String 类型和对象的引用都必须在使用前先赋值。
- 保证 final 修饰的变量不会被重复赋值。经过final 修饰的变量只能赋一次值,重复赋值会在这一步编译时报错,如果这个变量是静态变量,则在定义时就必须对其赋值。
- 要确定方法的返回值类型。这里需要检查方法的返回值类型是否确定,并检查接受这个方法返回值的引用类型是否匹配,如果没有返回值,则不能有任何引用类型指向方法的这个返回值。
- 所有的 Checked Exception 都要捕获或者向上抛出。例如,我们使用 FilelnputStream读取一个文件时,必须捕获可能抛出的
FileNotFondException异常,或者直接向上层方法抛出这个异常。 - 所有的语句都要被执行到。这里会检查是否有语句出现在一个return 方法的后面,因为在 return 方法后面的语句永远也不会被执行到。
语法分析的最后一步是执行com.sun.tools.javac.comp.Flow,这是在进一步对语法树进行语义分析,如消除一些无用的代码,总结:
- 去掉无用的代码
- 变量的自动转换
- 去除语法糖
代码生成器
经过语义分析器完成后的语法树已经非常完善了,接下来javac会调用com.sun.tools.javac.jvm.Gen类遍历语法树,生成最终的Java字节码,主要为两个步骤:
将Java方法中的代码块转化成符合JVM语法的命令形式,JVM的操作是基于栈的,所有操作都必须经过出栈和进栈完成
按照JVM的文件组织格式将字节码输出到以class为拓展名的文件
生成字节码除Gen类之外还有两个重要的辅助类:
Items:这个类表示任何可寻址的操作项,包括本地变量、类实例变量或者常量池中用户自定义的常量,这些操作项都可以作为一个单位出现在操作栈上
不同类型的Item对应不同的JVM的操作码:ImmediateItem(常量类型)、LocalItem(本地变量)、StackItem(栈中元素)
Code:存储生成的字节码,并提供一些能够映射操作码的方法
Gen会以后序遍历的顺序解析语法树,将add方法的方法块JCBlock的代码转换成JVM对应的字节码,时序图:

最后使用callMethod方法,返回给方法的调用者