5G NR Polar码简介(一)
这里写目录标题
- Polar码的基本原理
- NR Polar码的设计
-
- CA-Polar码
- PC-CA Polar码
- Distributed CRC Polar码
- 序列设计
Polar码的基本原理
土耳其毕尔肯大学Erdal Arikan于2008年提出了Polar码,Polar码是首个理论上可严格证明在二进制输入对称离散无记忆信道下可达香农限的编码方案。Polar码具有严格的结构,生成矩阵不需要额外设计,并且有较低的编码复杂度,速率匹配简单,可得到几乎任意码率的码字,Polar码还被理论证明没有误码平层,因而近年受到了广泛关注。
Polar码建立在信道极化的基础上,信道极化可以使得多个相同的信道产生差异,从而出现较好的信道和较差的信道。Arikan发现使用 ∣ 1 0 1 1 ∣ \begin{vmatrix} 1&0\\ 1&1 \end{vmatrix} ∣∣∣∣1101∣∣∣∣作为核矩阵,并使用Kroneccker积对该矩阵进行扩展,然后使用该扩展矩阵对信道进行合并,按序进行信道拆分得到N个二进制信道。经过信道的合并和拆分操作,二进制无记忆信道发生极化,在和容量保持不变的情况下,得到了两类极端的信道:一类信道容量趋近于1的好信道和一类信道容量趋近于0的坏信道,而且随着N的增大,好信道的比例会越来越趋近原信道的容量。
很明显,根据信道极化现象,将所要传输的数据加载在容量趋近于1的那些信道上,而容量趋近于0的那些信道不用于数据传输,就可以实现数据的可靠传输。按照这种思想构造出来的信道编码就是极化码。编码时对于一个给定的码长 N = 2 n N=2^n N=2n的Polar码,编码方法如下: x 0 N − 1 = u 0 N − 1 G N x_{0}^{N-1}=u_{0}^{N-1}G_{N} x0N−1=u0N−1GN,其中 G N G_N GN是 N ∗ N N*N N∗N阶生成矩阵。设 A A A为 { 0 , . . . , N − 1 } \{0,...,N-1\} {0,...,N−1}的一个子集,那么 x 0 N − 1 x_{0}^{N-1} x0N−1 = u A G N = u_{A}G_{N} =uAGN ⊕ u A c G N ( A C ) \oplus u_{A^c}G_{N}(A^C) ⊕uAcGN(AC),其中 G N ( A ) G_{N}(A) GN(A)是 G N ( A ) G_{N}(A) GN(A)是 G N G_N GN以 A A A为行数的子矩阵。如果固定 A A A和 u A c u_{A^c} uAc,把 u A u_{A} uA作为任意变量的信息比特输入,就可以得到对应于 u A u_A uA的码字 x 0 N − 1 x_0^{N-1} x0N−1。实际编码中,令 A A A为待编码的 K K K个信息比特对应的好信道的位置索引,而集合 A C A^C AC对应的位置取值固定,通常都设置为0, 称 u A c u_{A^c} uAc为冻结比特,Polar码的编码过程需要通过特定的规则选取信息比特位置索引 A A A。
Arikan定义的Polar码生成矩阵 G N = B N ( G 2 ) ⊗ n G_N=B_N(G_2)^{\otimes n} GN=BN(G2)⊗n, B N B_N BN为比特翻转矩阵,即把输入序列位置索引的二进制表达执行比特翻转,如 N = 8 N=8 N=8时,第二位置索引用“001”表示,经比特翻转转变为“100”,即第二位置输入比特与第五位置的输入比特交换,该操作有助于译码器设计,核矩阵 ∣ 1 0 1 1 ∣ \begin{vmatrix} 1&0\\ 1&1 \end{vmatrix} ∣∣∣∣1101∣∣∣∣,编码的复杂度为 O ( N l o g N ) O(N logN) O(NlogN)。为了保持生成矩阵的下三角结构,利于实现速率匹配,NR采用的Polar码生成矩阵不包括比特反序矩阵, G N = ( G 2 ) ⊗ n G_N=(G_2)^{\otimes n} GN=(G2)⊗n。
Polar码在码长充分大时,低复杂度的串行抵消(Successive Cancellation, SC)译码算法可以获得很好的译码性能,并被证明能够达到信道容量。但在实际应用中,码长总是有限长的,仿真结果表明,对于中短码长Polar码,SC译码性能不是很理想,为了改善译码性能,SCL(Successive Cancellation List)译码算法被提出。SCL译码相对于SC译码的一个直接改进是,在每一层路径搜索后从允许保留最好的一条路径增加到允许保留L个候选路径用于下一步扩展。随着路径数L的增加,SCL译码算法可以获得接近最大似然译码的性能,缺点是当L较大时,SCL译码算法的复杂度较高,而且会导致其FAR性能的损失,所以NR在设计控制信道Polar码编码时对性能与复杂度进行折中,所有的设计均基于L=8。
NR Polar码的设计
NR控制信道Polar码的设计原则是,在Arikan基本Polar码的基础上,根据控制信道的传输特点,引入新的特征。由于基站对译码复杂度不是非常敏感,所以当上行控制信息传输采用了 学术界研究最成熟的CA(CRC-aid)-Polar码;研究发现,当上行控制信息比特很短时,引入PC(Parity Check)比特(即PC-CA Polar码)可以明显改善CA-Polar码的性能;下行控制信道为了降低UE监听PDCCH的功耗,在CA-Polar码的基础上引入早停(Early Termination,ET)特性,即可以提前结束解码,达到降低功耗与译码延时的功效,即Distributed CRC Polar码。
CA-Polar码
虽然SCL译码算法相较于SC译码算法能明显提升BLER性能,但译码结束是的L条幸存路径中路径度量值最大的未必是正确的路径,考虑到移动通信中总会引入TB-CRC或者CB-CRC,所以可以利用CRC的校验功能辅助路径识别,从而较大的提升Polar码的纠错性能。
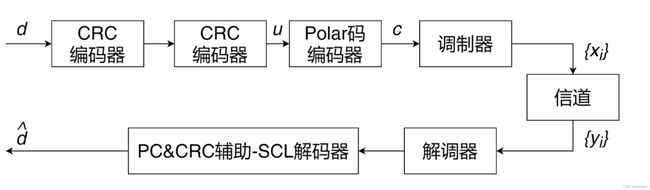
CA-polar码的编解码方案流程图如下图所示:

信源序列 d d d经过CRC编码器产生的CRC序列附加在序列 d d d后得到序列 u u u,再将序列 u u u送入Polar码编码器得到码字序列 c c c。序列 u u u中的比特在Polar码编码器上根据比特子信道可靠度进行放置,此时比特位置实际被分为信息比特、CRC比特与冻结比特3个部分,冻结比特位置放置0。译码时,CRC比特的译码过程和信息比特的译码过程相同,在SCL译码结束时,CRC译码器将对L个候选译码路径进行校验,可靠度最大的且通过CRC的路径上的译码序列作为最终译码结果 d ^ \hat{d} d^输出。
仿真表明,控制信道小分组传输时,CA-Polar在SCL译码算法下的BLER性能明显优于LTE控制信道采用的咬尾卷积码、LTE-Turbo码以及LDPC码,不同长度的CRC序列会影响系统的误帧率性能和虚警率性能。NR设计中采用了24bit CRC,在子载波间隔为15K的场景下,如果采用L=8的SCL译码,其FAR可达 2 − 21 2^{-21} 2−21。CA-Polar码被NR采纳为上行控制信息 K U C I > 19 K_{UCI}>19 KUCI>19时的编码方案。
PC-CA Polar码
研究发现,引入少量校验比特能够增加Polar码的最小码字简历,提高L条幸存路径的译码成功率,这就是PC-CA Polar码。当信息比特很短时,PC-AC Polar码的误码性能由于CA-Polar码,故PC-CA Polar被采纳为NR上行控制信息大小 12 ≤ K U C I ≤ 19 12 \leq K_{UCI} \leq 19 12≤KUCI≤19时的编码方案。
PC-CA Polar码的编解码方案如下图所示:
与CA-Polar码相比,PC-CA Polar码在CRC编码器之后级联了PC比特编码器,在译码端PC与CRC比特都参与路径筛选,而只有CRC比特被用于差错检验。J个PC比特的位置索引分为两个集合,其中 J − J ′ J-J' J−J′个PC比特放置在非冻结比特位置索引中最不可靠的 J − J ′ J-J' J−J′个最不可靠比特位置索引外的其它非冻结比特位置对应的Polar码生成矩阵中行重最小的位置上,如果行重最小的行对应的比特位置索引个数多于 J ′ J' J′,此时选择最可靠的 J ′ J' J′个位置索引放置这些的PC比特。
译码时,可以选择不展开PC比特,而是根据译码得到的信息比特与CRC比特,利用PC比特的产生方式直接计算得到PC比特。由于PC比特参与译码会改善码字的最小距离,故更容易找到最好的路径。NR标准中,PC比特由一个循环移位缓存器对信息比特进行异或操作产生。
Distributed CRC Polar码
下行控制信道的接收需要UE盲检PDCCH,对UE功耗有较大的影响。故标准在下行控制信道PDCCH与下行广播信道PBCH中采用了Distributed CRC Polar码方案, 用于支持Polar码译码早停功能。
在CA-Polar码中,CRC编码器是线性编码且生成的是系统码,所以CRC编码器必然对应一个生成矩阵 G C R C G_{CRC} GCRC,信息比特乘以生成矩阵即得CRC比特,生成矩阵由CRC多项式确定且与信息比特的长度有关。一个简单的例子,信息位长度为11bit,CRC长度为8bit。CRC编码器的输入为 d = { d 0 , d 1 , . . . , d 10 } d = \{ d_0,d_1,...,d_{10} \} d={d0,d1,...,d10},则CRC编码器的输出为 c = { c 0 , c 1 , . . . , c 18 } c = \{ c_0,c_1,...,c_{18} \} c={c0,c1,...,c18},采用交织模式 [ 10 , 9 , 8 , 4 , 11 , 0 , 5 , 12 , 6 , 1 , 13 , 2 , 14 , 3 , 15 , 7 , 16 , 17 , 18 ] [10,9,8,4,11,0,5,12,6,1,13,2,14,3,15,7,16,17,18] [10,9,8,4,11,0,5,12,6,1,13,2,14,3,15,7,16,17,18]对c进行置换,得到向量c’,从生成矩阵角度看,等价地生成矩阵 G C R C G_{CRC} GCRC进行置换得到 G ’ C R C G’_{CRC} G’CRC,可以看到,原来位于最后的8个CRC比特,有多个被置换到信息比特之前,且与CRC比特存在校验关系的信息比特也全部被置换到对应的CRC比特之前,这样译码部分信息比特就可以进行CRC了,如果校验失败即停止译码,从而实现ET功能。所以Distributed CRC Polar码在CRC编码后级联一个交织器(交织器知识改变CRC的校验顺序,并没有改变原校验关系),它的编码框图如下:

不难证明,相同的CRC生成多项式,不同信息比特长度下的CRC生成矩阵具有嵌套关系,所以根据最大信息比特长度设计交织模式可以得到任意信息比特长度对应的交织模式,NR下行控制信息目前支持的最大长度为140bit,附加24bit CRC,这样最大的交织长度为 K m a x = 164 b i t K_{max}=164bit Kmax=164bit。
序列设计
由于Polar码编码器的输入是长度为 N N N的序列u,为了适应长度为 K K K的信息比特编码,需要确定信息比特集合与冻结比特集合,这就离不开序列构造技术。Polar码的序列构造就是指根据比特信道的可靠度高低来选取可靠度高的比特信道放置信息比特,可靠度低的比特信道放置冻结信道。目前常用的序列构造方法主要有两类。
1.随机搜索的方法,主要有Monte-Carlo方法、基于密度进化的方法、高斯近似方法,及FRANK构造方法;基于随机方法够早的Polar序列,都是在特殊信道(如AWGN信道)下取得的,不可避免的会和信道存在一定的相关性,即所谓的信道敏感性。
2.PW(Polarization Weight)构造。该序列构造方式与具体的信道无关,而且性能与基于高斯近似设计序列在AWGN信道几乎一致;因此PW序列在NR Polar码序列讨论中得到广泛关注,是一种非常优秀的实现方案。
核生成矩阵 G N G_{N} GN的构造方式决定了Polar码长 N N N必须是2的整数次幂,该码长成为Polar码的母码长度。为降低基站与终端的译码复杂度,NR对Polar码的最大母码长度进行了限制,下行控制信道采用的最大母码长度 N m a x = 512 b i t N_{max}=512bit Nmax=512bit,上行控制信道采用 的最大母码长度为1024bit。为降低实现复杂度,序列设计的另一特性就是嵌套设计,即将更短的下行序列作为上行序列的一个子集,由于Polar码母码长度一定是2的整数次幂,因此短的母码赌赢序列必须是长的母码对应序列的一个子集,这就是NR Polar码序列嵌套特征。
NR系统选择采用基于AWGN信道性能作为Polar码序列设计方案的筛选准则,为了确保AWGN性能,随机搜索的方法被用于确定性能最优的序列。Polar码序列 Q = Q 0 , Q 1 , . . . , Q N m a x − 1 Q={Q_0,Q_1,...,Q_{N_{max}-1}} Q=Q0,Q1,...,QNmax−1,其中 0 ≤ Q i ≤ N m a x − 1 0 \leq Q_{i} \leq N_{max}-1 0≤Qi≤Nmax−1表示编码前的比特索引, N m a x = 1024 b i t N_{max}=1024bit Nmax=1024bit, W ( Q i N m a x ) W(Q_{i}^{N_{max}}) W(QiNmax)是 Q i Q_{i} Qi的可靠性,且满足 W ( Q 0 ) < W ( Q 1 ) < . . . < W ( Q N m a x − 1 ) W(Q_0)