英语词汇学习
It will be useful to gather the terms that are related to learning techniques and methods in machine and deep learning techniques in a single glossary, so that I give the concerned readers a quick grasp that can let them save considerable time and effort while looking for their meaning throughout the internet and documentations. The glossary includes some terms that are commonly used, whereas others are less popular, perhaps recently considered. Usually, terms are alphabetically ordered in glossaries. Here, I will present them according to their relation to each other. Aligning with the glossary nature, each term will be briefly introduced. The aim is to provide a comprehensible definition in a compact manner.
在单个词汇表中收集与机器学习和深度学习技术中的学习技术和方法相关的术语将非常有用,这样我可以使相关的读者快速掌握信息,从而可以在寻找他们的同时节省大量的时间和精力。整个互联网和文档中的含义。 该词汇表包含一些常用术语,而另一些则不太流行,也许最近才考虑使用。 通常,术语在术语表中按字母顺序排列。 在这里,我将根据它们之间的关系来介绍它们。 与词汇表性质保持一致,将简要介绍每个术语。 目的是以紧凑的方式提供可理解的定义。
Federated learning :
联合 学习 :
In federated learning, also baptized collaborative learning, the model is collectively trained by several nodes. A server orchestrates the training process of these latter that are generally mobile devices such as smartphones, tablets, and Internet of Things (IoT) devices. Federated learning is a good learning alternative that makes the training data decentralized :
在联合学习和受洗协作学习中,该模型由多个节点共同训练。 服务器编排这些服务器的培训过程,后者通常是诸如智能手机,平板电脑和物联网(IoT)设备之类的移动设备。 联合学习是一种很好的学习选择,它可以分散训练数据:
“ We term our approach Federated Learning, since the learning task is solved by a loose federation of participating devices (which we refer to as clients) which are coordinated by a central server. ” McMahan et al. 2016
“我们将我们的方法称为联合学习,因为学习任务是通过由中央服务器协调的参与设备(我们称为客户端)的松散联合来解决的。 ” McMahan等。 2016年
The principal working principle of the federated learning is that data used for the learning are distributed on several devices. This actually disables data disclosure since only trained models are shared between the nodes and the central server. The training data is preserved on devices. The role of the server is to aggregate the local model updates of each node and compute their average. The role of each of the devices is to download the global model update in order to compute the next local update and send it to the server. The first framework developed in this context is the Vanilla FL developed in 2016 by Google. The outcrop of the federated learning is benefiting from the development of a number of tools and frameworks, such as TensorFlow Federated, Federated AI Technology Enabler, PySyft, Leaf, PaddleFL, and Clara Training Framework. Despite its success, the FL is facing several issues, namely privacy concerns, expensive communication, systems heterogeneity, and statistical heterogeneity.
联合学习的主要工作原理是将用于学习的数据分布在多个设备上。 由于节点和中央服务器之间仅共享训练过的模型,因此实际上禁用了数据公开。 训练数据保存在设备上。 服务器的作用是汇总每个节点的本地模型更新并计算其平均值。 每个设备的作用是下载全局模型更新,以便计算下一个本地更新并将其发送到服务器。 在这种情况下开发的第一个框架是Google在2016年开发的Vanilla FL。 联合学习的露头得益于许多工具和框架的开发,例如TensorFlow联合,联合AI技术使能,PySyft,Leaf,PaddleFL和Clara培训框架。 尽管取得了成功,但FL仍面临几个问题,即隐私问题,昂贵的通信,系统异质性和统计异质性。
Distributed deep learning :
分布式 深度学习 :
Unlike federated learning, the focus of the distributed learning is to parallelize the training load by training a model on several nodes. With regard to nodes used in federated learning, they are battery-powered systems, e.g., smartphones and IoT devices, and communicate with the central server using limited reach networks, e.g., Bluetooth and Wi-Fi. However, nodes in distributed learning are typically powerful servers of high computational abilities that communicate using reliable networks. With regard to data, local datasets distributed across devices in federated learning are heterogeneous and not necessarily of the same size. In distributed learning, though, local datasets are almost of the same size and identically distributed on servers. In the table below, I gather the key differences between the federated and distributed learning.
与联合学习不同,分布式学习的重点是通过在几个节点上训练模型来并行化训练负载。 关于联合学习中使用的节点,它们是电池供电的系统,例如智能手机和IoT设备,并使用有限范围的网络(例如蓝牙和Wi-Fi)与中央服务器进行通信。 但是,分布式学习中的节点通常是使用可靠网络进行通信的,具有高计算能力的强大服务器。 关于数据,在联合学习中跨设备分布的本地数据集是异构的,不一定具有相同的大小。 但是,在分布式学习中,本地数据集的大小几乎相同,并且在服务器上的分布相同。 在下表中,我收集了联合学习和分布式学习之间的主要区别。
Mobile deep learning :
移动 深度学习 :
When deep learning is implemented on mobile devices, we are talking about mobile deep learning. As training is locally carried out, the mobile deep learning has many assets, mainly rapid response time, low network bandwidth, better data privacy, and low cost of the cloud resources. This fast-paced field is benefiting from the important advancements in terms of software, such as PyTorch Mobile, Paddle Mobile, and TensoFlow Lite, as well as in terms of hardware architectures, including Field Programmable Gate Arrays (FPGA), Application Specific Integrated Circuit (ASIC), and recent mobile Graphic Processing Units (GPU).
在移动设备上实现深度学习时,我们正在谈论的是移动深度学习。 由于培训是在本地进行的,因此移动深度学习具有许多资产,主要是响应时间短,网络带宽低,数据隐私性更好以及云资源成本较低。 这个快速发展的领域受益于软件方面的重要进步,例如PyTorch Mobile,Paddle Mobile和TensoFlow Lite,以及硬件体系结构,包括现场可编程门阵列(FPGA),专用集成电路(ASIC)和最新的移动图形处理单元(GPU)。
Supervised learning :
监督 学习:
The machine learning algorithm is presented with inputs and outputs and it has to learn rules to map the former to the latter. Here, we talk about labeled dataset. The supervised learning deals with two types of problems that are classification and regression where the predicted outputs are respectively discrete categorical and continuous numerical variables.
提出了带有输入和输出的机器学习算法,并且必须学习规则以将前者映射到后者。 在这里,我们讨论标记的数据集。 监督学习处理两种类型的问题,即分类和回归,其中预测的输出分别是离散的分类变量和连续的数值变量。
Unsupervised learning :
无监督 学习:
The machine learning algorithm is presented with inputs but not outputs and it has to learn structure from the inputs. Unlike supervised learning, no complete and clean labeled dataset is used in unsupervised learning. The main types of problems in this context are clustering, i.e., identification of data groups based on similarities and differences in input values, association mining, i.e., identification of items sets that frequently occur together in datasets, and anomaly detection, i.e., identification of unusual cases based on deviation from normal input patterns. We note that there is also a semi-supervised learning technique that takes a middle ground. It makes use of a small labeled dataset supported by a larger set of unlabeled data.
机器学习算法是用输入而不是输出表示的,它必须从输入中学习结构。 与有监督的学习不同,无监督的学习中不使用完整且干净的标记数据集。 在这种情况下,问题的主要类型是聚类(即,基于输入值的相似性和差异来识别数据组),关联挖掘(即,识别在数据集中经常一起出现的项目集)以及异常检测(即,对数据集的识别)。基于偏离正常输入模式的异常情况。 我们注意到,还有一种半监督学习技术,它具有中间立场。 它利用了较大的未标记数据集支持的小型标记数据集。
Self supervised learning :
自我监督 学习:
Self or sole supervised learning is a form of unsupervised learning where the data provides the supervision to solve problems such as data representations learning and automatic dataset labeling. Confronted to supervised learning, the aim of self supervised learning is to train good and why not better models than supervised learning without making use of too many labeled data. Based on cognitive abilities of living beings, like babies and animals that learn by experimenting and without actually having labels, Pierre Sermanet has declared :
自我或唯一的监督学习是无监督学习的一种形式,其中数据为解决诸如数据表示学习和自动数据集标记之类的问题提供监督。 面对监督学习,自我监督学习的目的是在不使用过多标记数据的情况下训练良好的模型,以及为什么没有比监督学习更好的模型。 Pierre Sermanet基于生物的认知能力,例如通过实验而实际上没有标签的婴儿和动物,他们宣布:
Give a robot a label and you feed it for second, teach a robot to label and you feed it for a lifetime.
给机器人贴上标签,然后第二次喂食,教机器人贴标签,然后终生喂。
Hence, self supervised learning allows us, unlike supervised technique, to leverage the large quantity of unlabeled data available on the internet. Further, it lets us avoid the compute, time and money cost of manually generating labeled datasets. In other words, self supervised learning exploits the asset of unsupervised learning, i.e., unlabeled data, to enhance the supervised learning return, i.e., labeled data, by firstly extracting data features and secondly performing a cheaper and less time consuming supervised learning.
因此,与监督技术不同,自我监督学习使我们能够利用互联网上可用的大量未标记数据。 此外,它使我们避免了手动生成标记数据集的计算,时间和金钱成本。 换句话说,自我监督学习通过首先提取数据特征并第二次执行便宜且耗时较少的监督学习,来利用无监督学习的资产(即未标记的数据)来增强有监督的学习回报(即标记的数据)。
Reinforcement learning :
强化 学习:
This specific learning technique is actually based on an agent that learns, on its own, to react to an environment. According to its state, the agent carries out actions in an environment to accumulate rewards. A reward is gained if the agent action corresponds to what is expected. In analogy with humans, the agent learns what to do and what not to do from positive and negative experiences that respectively correspond to rewarded and not rewarded actions. The main used reinforcement learning approaches are value-based, policy-based (deterministic and stochastic) and model-based.
这种特定的学习技术实际上是基于一个能够自己学习以对环境做出React的代理。 代理根据其状态在环境中执行操作以累积奖励。 如果代理人的行为与预期的行为相对应,则会获得奖励。 与人类类似,代理从分别对应于奖励和非奖励行为的积极和消极经验中学习做什么和不做什么。 强化学习的主要方法是基于价值,基于策略(确定性和随机性)和基于模型。
Below is a table that depicts the main characteristics of the supervised, unsupervised, self supervised and reinforcement learning techniques. No one of these machine learning techniques is favored over others. The idea is to make the choice of the appropriate one according to the nature of the problem to solve as well as the available data (small/large dataset, labeled/unlabeled data, …) and resources (time, hardware, money, …).
下表描述了有监督,无监督,自我监督和强化学习技术的主要特征。 这些机器学习技术中没有哪一种比其他的更受青睐。 想法是根据要解决的问题的性质以及可用的数据(小型/大型数据集,带标签/无标签的数据,...)和资源(时间,硬件,金钱,...)来选择合适的解决方案。

Compositional learning :
作文 学习 :
Compositional learning imitates the humans ability to decompose complex problems to primitive ones and acquire new knowledge from learned one without having to perform additional training. These assets make the compositional learning extremely useful to outcome the complexity of conventional learning techniques and alleviate their need for exorbitant amounts of labeled training datasets. The compositional learning becomes even a must when we face Natural Language processing problems. In fact, they represent a huge set of known words combinations that result in unknown expressions. Different approaches can be leveraged to achieve compositional learning. Main ones include modular learning, transfer learning and incremental learning that will be addressed in what follows.
组合学习模仿了人类将复杂问题分解为原始问题并从所学到的知识中获取新知识的能力,而无需进行额外的培训。 这些资产使构图学习对于得出传统学习技术的复杂性非常有用,并减轻了他们对大量标注训练数据集的需求。 当我们面对自然语言处理问题时,作文学习甚至成为必须。 实际上,它们代表了大量已知单词组合,导致未知的表达。 可以利用不同的方法来实现组成学习。 主要内容包括模块化学习,迁移学习和增量学习,这些将在后面介绍。
Modular learning :
模块化 学习 :
One of the disturbing issues that restrains the usage of deep learning algorithms is their exponential training complexity that highly increases as the number of the training epochs becomes more important. The modular learning is proposed as a solution to overcome such a shortcoming. Indeed, it lets us to control what part of the neural network would be run for each sample of the training dataset. I share with you a definition that I find interesting and complete :
限制深度学习算法使用的令人不安的问题之一是它们的指数训练复杂性,随着训练时期的数量变得越来越重要,该训练复杂性会大大增加。 提出了模块化学习作为克服这种缺点的解决方案。 实际上,它使我们可以控制针对训练数据集的每个样本运行神经网络的哪一部分。 我与您分享一个有趣且完整的定义:
“ A Modular Neural Network (MNN) is a Neural Network (NN) that consists of several modules, each module carrying out one sub-task of the NN’s global task, and all modules functionally integrated. A module can be a sub-structure or a learning subprocedure of the whole network … decomposing the objective task over smaller, sparsely-connected, and less complex modules decreases the connections-per-node ratio substantially, and hence, decreases the theoretical, as well as the practical, bounds of the required number of training samples” AUDA 1999
“模块化神经网络(MNN)是由多个模块组成的神经网络(NN),每个模块执行NN全局任务的一个子任务,并且所有模块在功能上集成在一起。 模块可以是整个网络的子结构或学习子过程…在较小,稀疏连接和较不复杂的模块上分解目标任务,从而大大降低了每个节点的连接数比率,因此降低了理论值,因为以及所需训练样本数量的实际界限”,AUDA 1999
Transfer learning :
转移 学习 :
Transfer learning leverages the knowledge that is generated from models already trained for a specific source task. In simple terms, transfer learning is the process of training a model on a large dataset and subsequently using this pre-trained model, that functions well for source task, to perform learning for another target task. This can make the learning faster and more accurate especially for target tasks that do not dispose of sufficient training data. That is what makes, as shown in the figure below, the success of transfer learning.
转移学习利用从已经针对特定源任务进行训练的模型中生成的知识。 简而言之,转移学习是在大型数据集上训练模型,然后使用此预训练的模型(对于源任务很好运行)对另一个目标任务进行学习的过程。 这可以使学习更快,更准确,特别是对于没有处理足够训练数据的目标任务。 如下图所示,这就是成功完成转学的原因。
For the particular deep transfer learning, two main strategies are commonly used, namely off-the-shelf pre-trained models as feature extractors and fine tuning off-the-shelf pre-trained models. The idea behind the former is to use the pre-trained model weighted layers to extract features of the target task data, then train a new shallow model on the so obtained features using traditional machine learning algorithms. The latter selectively retrains some of the source pre-trained model layers by updating their weights in order to fit the new task data. Layers that are generally chosen to be retrained are the deep ones since first layers do not detect task-specific features. A good transfer learning performance is achieved if new data resembles the source ones or at least shares the same features. The transfer learning is commonly used for both computer vision (e.g., VGG-16, ResNet-50 and Inception V3) and Nature Language Processing (e.g., Word2Vec, FastText and GloVe).
对于特定的深度转移学习,通常使用两种主要策略,即,作为特征提取器的现成的预训练模型和现成的预训练模型的微调。 前者的想法是使用预训练的模型加权层提取目标任务数据的特征,然后使用传统的机器学习算法在如此获得的特征上训练新的浅层模型。 后者通过更新它们的权重来选择性地重新训练某些源预训练模型层,以适应新的任务数据。 通常选择重新训练的层是较深的层,因为第一层不会检测特定于任务的功能。 如果新数据类似于源数据或至少共享相同的功能,则可以实现良好的迁移学习性能。 迁移学习通常用于计算机视觉(例如VGG-16,ResNet-50和Inception V3)和自然语言处理(例如Word2Vec,FastText和GloVe)。
Learning from scratch :
从头 学习 :
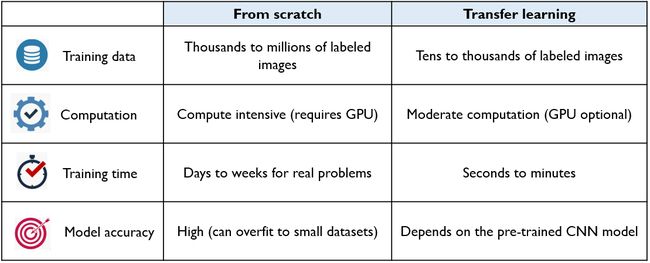
Lack of sufficient data, computing resources and time, you download from the web a pre-trained model that is already trained on a huge dataset. Then, you use it, without any further tuning or with only minimal fine tuning on your own much smaller dataset. Unlike this transfer learning, you may opt for learning from scratch where the model needs to be trained for as many iterations as a new model would demand. A full training process is typically required on all the dataset. Learning from scratch is considered necessary for tasks that do not dispose of pre-trained models or simply do not have access to them. Main differences between learning from scratch and transfer learning are summarized in the table below. Both approaches have their pros and cons and the adoption of one of them depends on the nature of the problem to solve.
缺乏足够的数据,计算资源和时间,您需要从网络上下载已经在庞大的数据集上进行训练的预训练模型。 然后,您可以使用它,而无需进行任何进一步的调整,或者仅对自己较小的数据集进行最小的调整。 与这种转移学习不同,您可以选择从头开始学习,在这种情况下,需要对模型进行新模型所需的多次迭代训练。 通常,对所有数据集都需要完整的培训过程。 对于不处理预训练模型或根本无法访问它们的任务,从头开始学习被认为是必要的。 下表总结了从头开始学习和迁移学习之间的主要区别。 两种方法各有利弊,采用其中一种方法取决于要解决的问题的性质。
Incremental learning :
增量 学习 :
One of the major limits of neural networks is their inability to gain knowledge over time and continually learn as humans do. They will not learn anything new once you stop training them. The incremental learning, also known as continuous, continual, and online learning, is proposed to address such issue especially that, in a world as we are living nowadays, new data is continuously available. Further, they are of high dimensionality, large in size and of continuous update. This is mainly the case of data streams, big data and time series datasets that are largely exploited for stock trend prediction and costumer profiling applications. Another current example is models that are trained on COVID-19 X-rays and CT images as diagnosis alternatives to the time-consuming RT-PCR. These databases are substantially expanded by the scientific community and medical societies as new data becomes available.
神经网络的主要限制之一是它们无法随着时间的流逝获得知识并无法像人类一样不断学习。 一旦您停止培训他们,他们将不会学到任何新东西。 提出了增量学习(也称为连续学习,连续学习和在线学习)来解决这一问题,尤其是在当今我们生活的世界中,不断有新数据可用。 此外,它们具有高尺寸,大尺寸和连续更新。 这主要是数据流,大数据和时间序列数据集的情况,这些数据集主要用于股票趋势预测和客户分析应用。 当前的另一个例子是在COVID-19 X射线和CT图像上训练的模型,作为耗时的RT-PCR的诊断替代方案。 随着新数据的获得,科学界和医学界大大扩展了这些数据库。
Given a model that you have trained from scratch for a source task, transfer learning makes possible its reuse with and without fine-tuning for a traget one. In the case of fine-tuning, layers that are retrained tend to adjust their weights and biases to solve the new task and forget them for source task. This is not the case for incremental learning. This latter has the advantage of training in sequence a neural network for several tasks, i.e., source, target, …, without forgetting what it learned before.
给定您已从头开始训练的用于源任务的模型,转移学习可以在有或没有对traget进行微调的情况下进行重用。 在微调的情况下,重新训练的图层倾向于调整其权重和偏差以解决新任务,而将其遗忘用于源任务。 增量学习不是这种情况。 后者的优点是可以顺序训练一个神经网络以执行多个任务,即源,目标等,而不会忘记以前学到的知识。
Few/N-shot learning :
少/无镜头 学习 :
Unlike humans, computers are not able to recognize objects that were not previously learned. In this context, N-shot learning is becoming more and more solicited insofar as it enables recognition of objects from classes that the learned model has not seen during training. These are classes for which labeled images are sparse or even not present during the training phase. Indeed, with numerous object classes in the real life, it is impossible to possess densely populated classes and it becomes unfeasible and expensive to maintain a large number of examples per class to feed the training process. N-shot is hence an interesting variant of transfer learning where the model is able to classify new data belonging to new classes based on few or even unlabeled shots, i.e., samples available for training.
与人类不同,计算机无法识别以前未学习的对象。 在这种情况下,N-shot学习正变得越来越受人们欢迎,因为它可以识别所学习的模型在训练过程中未见过的类中的对象。 这些是在训练阶段稀疏甚至不存在标记图像的类。 确实,在现实生活中有许多对象类,不可能拥有人口稠密的类,并且为每个类维护大量示例以供训练过程变得不可行且昂贵。 因此,N镜头是转移学习的一个有趣的变体,其中模型能够基于少量甚至未标记的镜头(即可用于训练的样本)对属于新类别的新数据进行分类。
Few-shot or N-shot learning usually refers to a number of samples per unseen class ranging from 0 to 5. If we consider for example a zero-shot learning, it means that our model will be trained with no samples. By the same reasoning, one-shot means a training using one sample. Besides visual features, a semantic transfer is required to make the N-shot learning possible. The semantic attributes act as a bridge between seen and unseen classes given that samples of these latter are either scarce or unavailable.
很少镜头学习或N镜头学习通常指的是每个未见类的样本数量,范围从0到5。如果我们考虑例如零镜头学习,这意味着我们的模型将在没有样本的情况下进行训练。 出于同样的原因,一次射击意味着使用一个样本进行训练。 除视觉功能外,还需要语义转换以使N镜头学习成为可能。 鉴于这些类别的样本稀缺或不可用,因此语义属性充当可见和不可见类之间的桥梁。
Thanks for reading ! This glossary may be not complete. If a term is missing, please let me know.
谢谢阅读 ! 该词汇表可能不完整。 如果缺少一个术语,请告诉我。
In case you have missed my other posts :
如果您错过了我的其他职位:
Before you go, I want to share with you the pictures below that I have captured during my last visit to Djerba, the island of dreams in Tunisia !
在您出发之前,我想与您分享我上次访问突尼斯梦想之岛杰尔巴时拍摄的以下照片!

翻译自: https://medium.com/@sebaidorsaf/x-learning-glossary-19203cf9080e
英语词汇学习