ceph块存储使用总结
ceph块存储使用总结
大纲
- ceph osd pool池
- 创建 & 更新osd pool
- 关联应用
- 删除ceph osd pool
- 使用ceph块存储
- 自动挂载
- 扩容
本次测试相关环境与软件:
- ceph15.2.17 Octopus
- eph-deploy 2.0.1
- ubuntu18.04.6
ceph osd pool池
基础概念
Ceph 将数据存储在存储池中。存储池是用于存储对象的逻辑组。
对于存储系统而言 , 池并不是很新的概念。 企业级存储系统是通过创建不同的池来管理的 , Ceph 也通过池提供了简单的存储管理 。 Ceph 的池是一个用来存储对象的逻辑分区 。 Ceph中每个池都包含一定数量的PG , 进而实现把一定数量的对象映射到集群内部不同 OSD 上 因 此, 每一个池都是交叉分布在集群所有节点上的 , 这样就能够提供足够的弹性
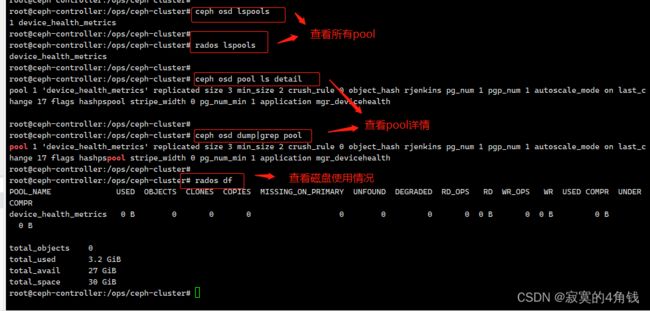
常用查询命令:
-
1 ceph osd lspools 或者 rados lspools 查看集群中存在的pools
-
2 ceph osd pool ls detail 或者 ceph osd dump|grep pool 查看pool的详细配置信息
这些详情字段可以使用ceph osd pool set去更新
-
3 rados df 查看pool的用量信息
创建 & 更新osd pool
池可以通过创建需要的副本数来保障数据的高可用性,比如通过复制或者纠删码方式
Pool是存储对象的逻辑分区,它规定了数据冗余的类型和对应的副本分布策略;支持两种类型:
- replicated 副本
- Erasure Code 纠删码
纠删码
纠删码( EC) 特性是 Ceph 的新功能,首次发布是在 Ceph 的 Firefly 版本中 。
纠删码是一种数据保护方法,它首先将数据分解成块 接着编码,然后以分布式的方式存储 。
天生就是分布式的 Ceph 能够很好地利用 EC 。
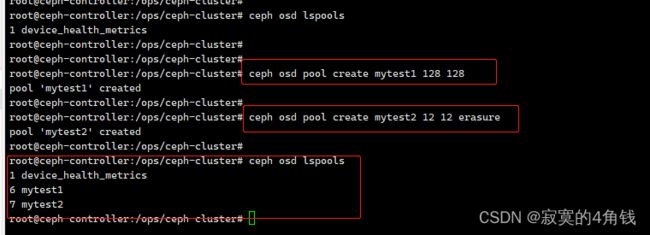
创建副本池
ceph osd pool create 【pool名称】【PG数量】 【PGP数量】
创建纠删码池
ceph osd pool create 【pool名称】【PG数量】 【PGP数量】 erasure
ceph osd pool create mytest1 128 128
ceph osd pool create mytest2 12 12 erasure
更新池
ceph osd pool set 【pool名称】【key】【value】
如设置副本池的副本数:
ceph osd pool set mytest1 size 2
set pool 2 size to 2
可选的配置更新项
size
设置存储池中对象的副本数。
min_size
设置 I/O 所需的最小副本数。
crash_replay_interval
允许客户端重放已确认但未提交的请求的秒数。
pg_num
存储池的归置组数。
pgp_num
计算数据归置时要使用的归置组的有效数量。
crush_ruleset
用于在集群中映射对象归置的规则组。
hashpspool
为给定存储池设置 (1) 或取消设置 (0) HASHPSPOOL 标志。启用此标志会更改算法,以采用更佳的方式将 PG 分配到 OSD 之间。对之前 HASHPSPOOL 标志设为 0 的存储池启用此标志后,集群会开始回填,以使所有 PG 都可再次正确归置。请注意,这可能会在集群上产生相当高的 I/O 负载,因此对高负载生产集群必须进行妥善规划。
nodelete
防止删除存储池。
nopgchange
防止更改存储池的 pg_num 和 pgp_num。
nosizechange
防止更改存储池的大小。
write_fadvise_dontneed
对给定存储池设置/取消设置 WRITE_FADVISE_DONTNEED 标志。
noscrub、nodeep-scrub
禁用(深层)整理 (scrub) 特定存储池的数据以解决临时高 I/O 负载问题。
hit_set_type
对快速缓存池启用命中集跟踪。请参见布隆过滤器以了解更多信息。此选项可用的值如下:bloom、explicit_hash、explicit_object。默认值是 bloom,其他值仅用于测试。
hit_set_count
要为快速缓存池存储的命中集数。该数值越高,ceph-osd 守护进程耗用的 RAM 越多。默认值是 0。
hit_set_period
快速缓存池的命中集期间的时长(以秒为单位)。该数值越高,ceph-osd 守护进程耗用的 RAM 越多。
hit_set_fpp
布隆命中集类型的误报率。请参见布隆过滤器以了解更多信息。有效范围是 0.0 - 1.0,默认值是 0.05
use_gmt_hitset
为快速缓存分层创建命中集时,强制 OSD 使用 GMT(格林威治标准时间)时戳。这可确保在不同时区中的节点返回相同的结果。默认值是 1。不应该更改此值。
cache_target_dirty_ratio
在快速缓存分层代理将已修改(脏)对象清理到后备存储池之前,包含此类对象的快速缓存池百分比。默认值是 .4
cache_target_dirty_high_ratio
在快速缓存分层代理将已修改(脏)对象清理到速度更快的后备存储池之前,包含此类对象的快速缓存池百分比。默认值是 .6。
cache_target_full_ratio
在快速缓存分层代理将未修改(干净)对象从快速缓存池逐出之前,包含此类对象的快速缓存池百分比。默认值是 .8
target_max_bytes
触发 max_bytes 阈值后,Ceph 将会开始清理或逐出对象。
target_max_objects
触发 max_objects 阈值时,Ceph 将开始清理或逐出对象。
hit_set_grade_decay_rate
两次连续的 hit_set 之间的温度降低率。默认值是 20。
hit_set_search_last_n
计算温度时在 hit_set 中对出现的项最多计 N 次。默认值是 1。
cache_min_flush_age
在快速缓存分层代理将对象从快速缓存池清理到存储池之前的时间(秒)。
cache_min_evict_age
在快速缓存分层代理将对象从快速缓存池中逐出之前的时间(秒)。
fast_read
如果对纠删码池启用此标志,则读取请求会向所有分片发出子读取命令,并一直等到接收到足够解码的分片,才会为客户端提供服务。对于 jerasure 和 isa 纠删插件,前 K 个副本返回时,就会使用从这些副本解码的数据立即处理客户端的请求。这有助于获得一些资源以提高性能。目前,此标志仅支持用于纠删码池。默认值是 0。
scrub_min_interval
集群负载低时整理 (scrub) 存储池的最小间隔(秒)。默认值 0 表示使用来自 Ceph 配置文件的 osd_scrub_min_interval 值。
scrub_max_interval
不论集群负载如何都整理 (scrub) 存储池的最大间隔(秒)。默认值 0 表示使用来自 Ceph 配置文件的 osd_scrub_max_interval 值。
deep_scrub_interval
深层整理 (scrub) 存储池的间隔(秒)。默认值 0 表示使用来自 Ceph 配置文件的 osd_deep_scrub 值。
关联应用
从 Luminous 开始,所有池都需要与使用该池的应用程序相关联 将与 CephFS 搭配使用或由对象网关自动创建的存储池会自动关联。需要使用 rbd 工具初始化要与 RBD 搭配使用的存储池。
关联命令格式
ceph osd pool application enable 【pool名称】 【应用程序名称: rbd rgw cephfs】
例如
ceph osd pool application enable mytest1 rbd

查看储池与个应用关联
ceph osd pool application get mytest1
删除ceph osd pool
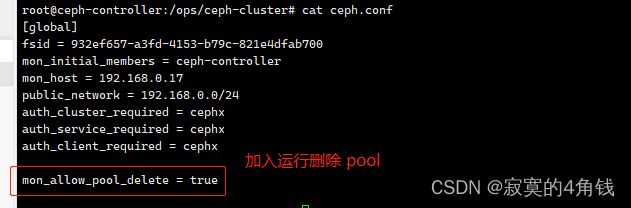
由于ceph的安全机制,osd pool不能直接删除需要配置允许删除
1 编辑ceph.conf文件 添加 mon_allow_pool_delete = true
2 将ceph.conf 推送到各个mon节点
ceph-deploy --overwrite-conf config push ceph-controller ceph-osd1 ceph-osd2
注意 --overwrite-conf 表示覆盖存在的配置文件

3 重启mon节点 mon服务
systemctl restart ceph-mon@ceph-osd1
systemctl restart ceph-mon@ceph-osd2
systemctl restart ceph-mon@ceph-controller
4 删除pool
格式 ceph osd pool delete 【pool名称】【pool名称】
例如
ceph osd pool delete mytest mytest --yes-i-really-really-mean-it

使用ceph块存储
初始化准备
网络架构
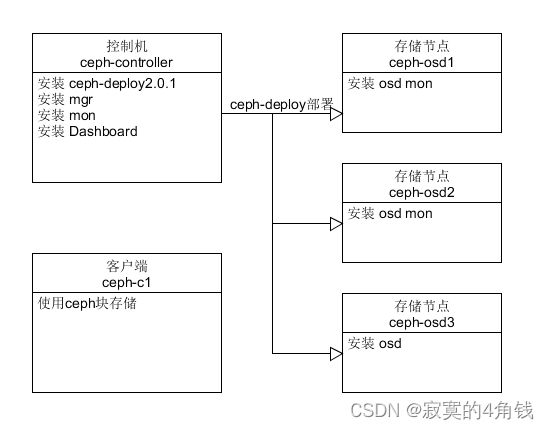
在使用块存储之前需要在稍微配置下客户端主机,登录ceph-controller主机 ,使用ceph-deploy 安装ceph相关软件
配置host
添加192.168.0.241 ceph-c1
免密登录
ssh-copy-id root@ceph-c1
在ceph-c1 主机上安装ceph相关软件
ceph-deploy install ceph-c1
为了简单将admin keyring复制到ceph-c1
ceph-deploy admin ceph-c1
rbd 命令使用的默认池的名称是rbd 所以需要在创建一个名称为rbd的池
创建pool 注意名称是rbd
ceph osd pool create rbd 128 128
关联rbd应用
ceph osd pool application enable rbd rbd

安装完成后登录到ceph-c1

使用ceph块设备
step1 创建RADOS块设备
需要先创建RADOS块设备
例如:创建一个1G的块设备 名称为my-rbd1 注意这里使用默认的rbd池
rbd create my-rbd1 --size 1024
也可以使用-p 指定对应的池
例如:创建一个1G的块设备 名称为my-test1 注意使用-p 指定mytest1池
rbd create my-test1 -p mytest1 --size 1024
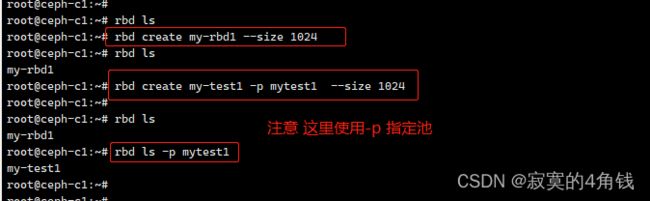
step2 映射块设备
需要把创建的块设备映射到主机上
注意需要先关闭不支持的内核特性
rbd feature disable my-rbd1 object-map fast-diff deep-flatten
映射块设备
rbd map --image my-rbd1
查看块映射后的设备名称
rbd showmapped
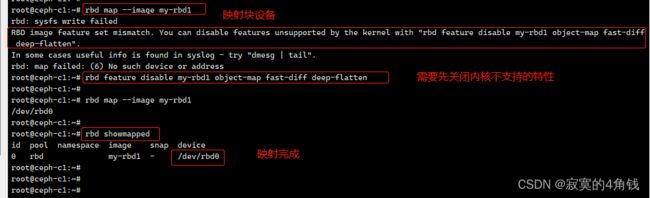
使用lsblk 和 fdisk -l 都可以看到已经出现可以使用的设备名称 /dev/rbd0

step3 格式化文件系统并挂载
格式化文件系统
mkfs.ext4 /dev/rbd0
创建文件
mkdir /ceph-disk
设备挂载
mount /dev/rbd0 /ceph-disk
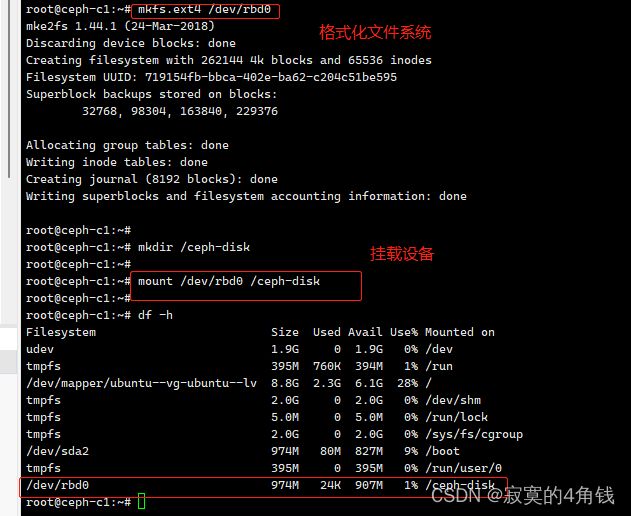
然后就使用把ceph块当做磁盘使用了
自动挂载
原理 linux开启执行rbd map映射出设备,然后自动挂载
step1 准备一个开启启动service
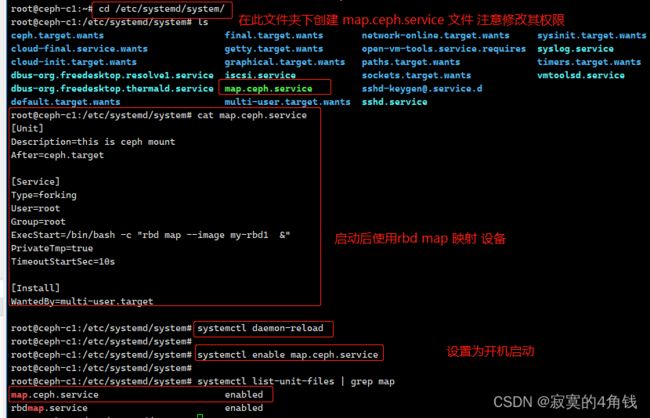
在/etc/systemd/system文件夹下创建map.ceph.service文件
内容如下:
[Unit]
Description=this is ceph mount
After=ceph.target
[Service]
Type=forking
User=root
Group=root
ExecStart=/bin/bash -c "rbd map --image my-rbd1 &"
PrivateTmp=true
TimeoutStartSec=10s
[Install]
WantedBy=multi-user.target
注意chmod 755 map.ceph.service 修改权限
systemctl daemon-reload
systemctl enable map.ceph.service
systemctl list-unit-files | grep map
step2 修改/etc/fstab
加入
/dev/rbd0 /ceph-disk ext4 defaults,_netdev 0 0

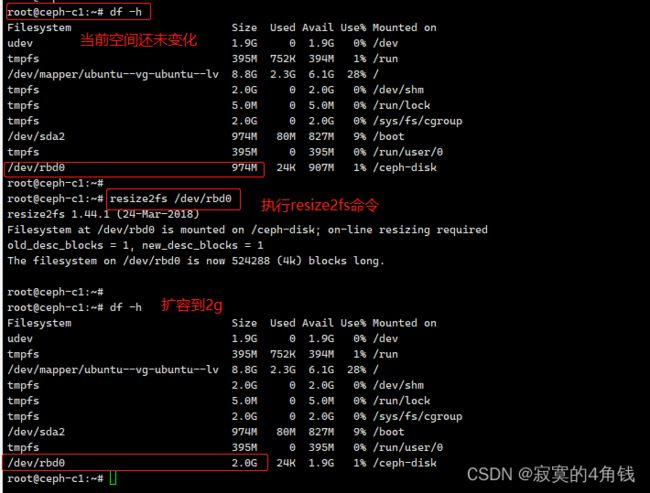
扩容
可以使用 rbd resize 命令来对块扩容
rbd resize --image my-rbd1 --size 2048
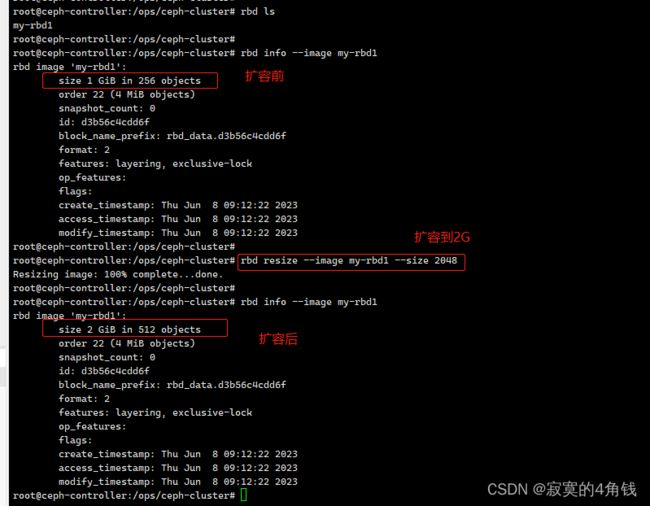
进入到ceph-c1 客户
扩容前可以看到ceph-c1 客户端当前磁盘大小为1G
blockdev 可以查看设备空间
blockdev --getsize64 /dev/rbd0
resize2fs程序会重新定义ext2,ext3或者是ext4文件系统
执行
resize2fs /dev/rbd0
执行 resize2fs命令后 空间变大