Springcloud之Feign、Hystrix、Ribbon如何设置超时时间
一,概述
我们在微服务调用服务的时候,会使用hystrix、feign和ribbon,比如有一个实例发生了故障而该情况还没有被服务治理机制及时的发现和摘除,这时候客户端访问该节点的时候自然会失败。
所以,为了构建更为健壮的应用系统,我们希望当请求失败的时候能够有一定策略的重试机制,而不是直接返回失败。
这里还会设计一些其他的配置参数,降级和熔断的概念不再赘述。
先看这几个组件的关系
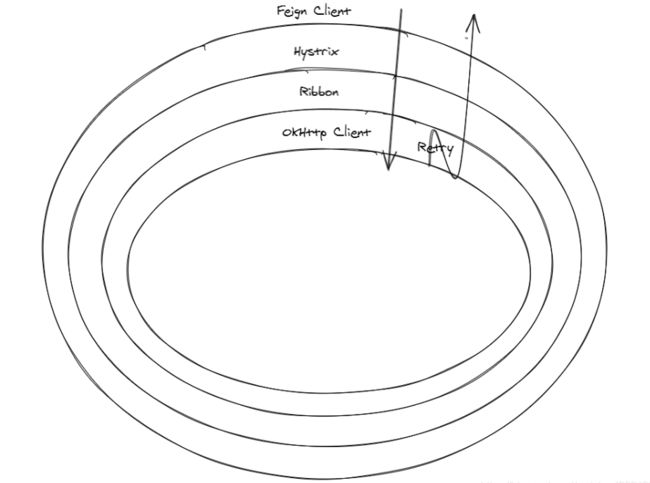
hystrix+ribbon。hystrix在最外层,然后再到Ribbon,最后里面的是http请求。所以说。hystrix的熔断时间必须大于ribbon的 ( ConnectTimeout + ReadTimeout )。而如果ribbon开启了重试机制,还需要乘以对应的重试次数(注意这里的重试可以是ribbon的重试也可能是feign的重试),保证在Ribbon里的请求还没结束时,Hystrix的熔断时间不会超时。
二,配置
1,hystrix降级配置
该降级配置会在请求发出30秒未返回或者异常的时候触发降级策略。并中断正在执行的线程。
#开启Feign下面的Hystrix功能
feign.hystrix.enabled=true
#是否开启服务降级
hystrix.command.default.fallback.enabled=true
#全局超时
hystrix.command.default.execution.timeout.enabled=true
#超时时间
hystrix.command.default.execution.isolation.thread.timeoutInMilliseconds=30000
#超时以后终止线程
hystrix.command.default.execution.isolation.thread.interruptOnTimeout=true
#取消的时候终止线程
hystrix.command.default.execution.isolation.thread.interruptOnFutureCancel=true2,hystrix熔断配置
该熔断配置的效果是如果时间窗口20秒内,请求超过5个,且失败率到达50%,也就是一般会进行熔断,比如20秒内6个请求,有三个成功,三个失败,在发送第六个请求结束后,会对下游服务进行熔断。从熔断的时刻开始,15秒后进入半开状态,尝试放过一个请求,如果成功也关闭熔断,否则等下一个15秒。
#熔断的前提条件(请求的数量),在一定的时间窗口内,请求达到5个以后,才开始进行熔断判断
hystrix.command.default.circuitBreaker.requestVolumeThreshold=5
#超过50%的失败请求,则熔断开关开启
hystrix.command.default.circuitBreaker.errorThresholdPercentage=50
#当熔断开启以后,经过多少秒再进入半开状态
hystrix.command.default.circuitBreaker.sleepWindowInMilliseconds=15000
#配置时间窗口
hystrix.command.default.metrics.rollingStats.timeInMilliseconds=20000
#开启熔断功能
hystrix.command.default.circuitBreaker.enabled=true
#强制开启熔断开关
hystrix.command.default.circuitBreaker.forceOpen=false
#强制关闭熔断开关
hystrix.command.default.circuitBreaker.forceClosed=false3,ribbon配置
该配置会在发生网络异常后进行请求重试,发生网络异常后,重试次数为(1 + MaxAutoRetries) * (1 + MaxAutoRetriesNextServer)因为包含自己的一次正常请求所以要 +1(失败次数和保存到本地的所以服务之间不能互相感知,每次每一个服务都要+1)
所以hystrix的超时时间(timeoutInMilliseconds)应该配置为
timeoutInMilliseconds > (1 + MaxAutoRetries) * (1 + MaxAutoRetriesNextServer)* (ConnectTimeout + ReadTimeout)
也就是timeoutInMilliseconds >= (1+2)*(1+2)*(1+2)
#全局配置
#每台机器最大重试次数
ribbon.MaxAutoRetries=2
#可以再重试几台机器
ribbon.MaxAutoRetriesNextServer=2
#连接超时
ribbon.ConnectTimeout=1000
#业务处理超时
ribbon.ReadTimeout=2000
#在所有HTTP Method进行重试,默认只是在GET请求的地方重试
ribbon.OkToRetryOnAllOperations=true
#单个服务配置配置,该设置会覆盖掉全局配置,servicename为调用服务在注册中心注册服务名称
#每台机器最大重试次数
servicename.ribbon.MaxAutoRetries=2
#可以再重试几台机器
servicename.ribbon.MaxAutoRetriesNextServer=2
#连接超时
servicename.ribbon.ConnectTimeout=1000
#业务处理超时
servicename.ribbon.ReadTimeout=2000
#在所有HTTP Method进行重试,默认只是在GET请求的地方重试
servicename.ribbon.OkToRetryOnAllOperations=true1,ribbon的重试机制
ribbon默认不开启重试,开启后默认只有GET请求进行重试
ribbon 调用重试需要引入此包
org.springframework.retry
spring-retry
1.3.0
4,feign配置
在项目中,使用feignClient进行http 服务调用,feignClient的默认连接方式为HttpURLConnection,因为HttpURLConnection没有连接池,并发高的时候,会有一定的网络开销,在做项目优化的时候,替换改为okHttp以便复用其连接池(也可以使用apache的httpclient)。
如果没有设置过 feign 超时,也就是等于默认值的时候,就会读取 ribbon 的配置,使用 ribbon 的超时时间和重试设置。否则使用 feign 自身的设置。两者是二选一的,且 feign 优先。
io.github.openfeign
feign-okhttp
11.0
feign:
#okhttp3的时候压缩不生效
# compression:
# request:
# enabled: true
# mime-types:
# - text/xml
# - application/xml
# - application/json
# min-request-size: 2048
okhttp:
enabled: true
client:
config:
#设置的全局超时时间
#如果没有设置过 feign 超时,也就是等于默认值的时候,就会读取 ribbon 的配置,
#使用 ribbon 的超时时间和重试设置【默认连接和读取时间各1秒】。否则使用 feign 自身的设置。
#两者是二选一的,且 feign 优先。
default:
#请求连接的超时时间
#connectTimeout: 10000
#请求处理的超时时间
#readTimeout: 60000
#不打印请求日志
loggerLevel: NONE
#配置请求拦截器
# request-interceptors:
# - feign.auth.BasicAuthRequestInterceptor
# decoder: org.springframework.cloud.openfeign.support.SpringDecoder
# encoder: org.springframework.cloud.openfeign.support.SpringEncoder1,feign的重试机制
因为ribbon的重试机制和feign的重试机制有冲突,所以源码中默认关闭feign的重试机制。
这里以使用feign的默认实现Default为例配置,这里使用bean的方式配置,这里配置最大重试次次数是5次,最大重试时间1s,每次重试间隔100ms
注意使用feign重试的时候,不需要开启ribbon重试,且需要配置feign的超时时间。
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import feign.Retryer;
import static java.util.concurrent.TimeUnit.SECONDS;
@Configuration
public class AppConfig {
@Bean
public Retryer feignRetryer(){
return new Retryer.Default(1,SECONDS.toMillis(1), 5);
}
}