简要介绍 | 强化学习:从原理到应用
注1:本文系“简要介绍”系列之一,仅从概念上对强化学习进行非常简要的介绍,不适合用于深入和详细的了解。
注2:"简要介绍"系列的所有创作均使用了AIGC工具辅助
强化学习:从原理到应用
1. 背景介绍
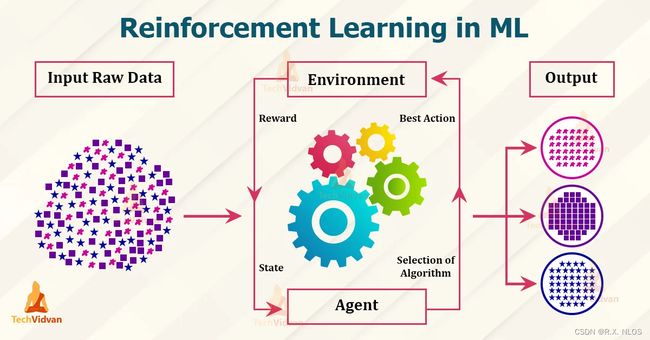
强化学习 (Reinforcement Learning, RL) 是一种通过与环境交互来学习决策策略的机器学习方法。它的核心思想是让智能体 (Agent) 在执行动作 (Action)、观察环境 (Environment) 反馈的状态 (State) 和奖励 (Reward) 的过程中,学习到一个最优策略 (Optimal Policy),从而实现长期累积奖励最大化。
2. 原理介绍与推导
2.1 强化学习框架

强化学习的核心框架包括以下几个部分:
- 智能体 (Agent):在环境中执行动作,学习最优策略的实体;
- 环境 (Environment):提供状态信息和奖励反馈,受到智能体动作影响的外部系统;
- 状态 (State):描述环境当前状况的信息;
- 动作 (Action):智能体可以在环境中执行的操作;
- 奖励 (Reward):环境对智能体执行动作的评价,是一个标量值。
2.2 马尔可夫决策过程 (Markov Decision Process, MDP)
强化学习问题通常可以建模为一个马尔可夫决策过程,包括以下几个要素:
- 状态集合 (State Set): S S S;
- 动作集合 (Action Set): A A A;
- 状态转移函数 (State Transition Function): P ( s ′ ∣ s , a ) P(s'|s, a) P(s′∣s,a),描述在状态 s s s下执行动作 a a a后转移到状态 s ′ s' s′的概率;
- 奖励函数 (Reward Function): R ( s , a , s ′ ) R(s, a, s') R(s,a,s′),描述在状态 s s s下执行动作 a a a并转移到状态 s ′ s' s′后获得的奖励。
策略 (Policy)**: π ( a ∣ s ) \pi(a|s) π(a∣s),描述智能体在状态 s s s下选择动作 a a a的概率。
目标是找到一个最优策略 π ∗ \pi^* π∗,使得长期累积奖励最大化。
2.3 价值函数 (Value Function) 与 Q 函数 (Q-function)
价值函数 (Value Function): V π ( s ) V^\pi(s) Vπ(s),描述在状态 s s s下,依据策略 π \pi π执行动作后能获得的未来累积奖励的期望。
Q 函数 (Q-function): Q π ( s , a ) Q^\pi(s, a) Qπ(s,a),描述在状态 s s s下执行动作 a a a并依据策略 π \pi π执行后续动作能获得的未来累积奖励的期望。
价值函数和 Q 函数满足以下递推关系(贝尔曼方程 (Bellman Equation)):
V π ( s ) = ∑ a π ( a ∣ s ) ∑ s ′ P ( s ′ ∣ s , a ) [ R ( s , a , s ′ ) + γ V π ( s ′ ) ] V^\pi(s) = \sum_{a} \pi(a|s) \sum_{s'} P(s'|s, a) [R(s, a, s') + \gamma V^\pi(s')] Vπ(s)=a∑π(a∣s)s′∑P(s′∣s,a)[R(s,a,s′)+γVπ(s′)]
Q π ( s , a ) = ∑ s ′ P ( s ′ ∣ s , a ) [ R ( s , a , s ′ ) + γ ∑ a ′ π ( a ′ ∣ s ′ ) Q π ( s ′ , a ′ ) ] Q^\pi(s, a) = \sum_{s'} P(s'|s, a) [R(s, a, s') + \gamma \sum_{a'} \pi(a'|s') Q^\pi(s', a')] Qπ(s,a)=s′∑P(s′∣s,a)[R(s,a,s′)+γa′∑π(a′∣s′)Qπ(s′,a′)]
其中 γ \gamma γ 是 折扣因子 (Discount Factor),取值范围为 [0, 1],表示未来奖励的折扣程度。
3. 研究现状
3.1 值迭代 (Value Iteration) 与策略迭代 (Policy Iteration)
值迭代和策略迭代是基于动态规划 (Dynamic Programming) 求解马尔可夫决策过程的传统方法。值迭代通过迭代更新价值函数 V ( s ) V(s) V(s),直到收敛;策略迭代则交替进行策略评估 (Policy Evaluation) 和策略改进 (Policy Improvement)。
3.2 Q 学习 (Q-Learning) 与 SARSA
Q 学习和 SARSA 是基于时间差分学习 (Temporal Difference Learning) 的方法。它们通过迭代更新 Q 函数,最终收敛到最优 Q 函数 Q ∗ ( s , a ) Q^*(s, a) Q∗(s,a),从而获得最优策略。
Q 学习和 SARSA 的主要区别在于更新 Q 函数时的目标值。Q 学习使用最大化后续状态的 Q 值作为目标值,而 SARSA 使用实际执行动作的后续状态的 Q 值作为目标值。
3.3 深度强化学习 (Deep Reinforcement Learning)
深度强化学习通过结合深度学习 (Deep Learning) 和强化学习,利用神经网络 (Neural Network) 作为函数逼近器 (Function Approximator),可以处理具有复杂状态空间的问题。
典型的深度强化学习算法包括:
- DQN (Deep Q-Network):将 Q 函数用深度神经网络表示,利用经验回放 (ExperienceReplay) 和固定目标网络 (Fixed Target Network) 技术进行稳定训练;
- DDPG (Deep Deterministic Policy Gradient):将策略和 Q 函数用深度神经网络表示,适用于连续动作空间的问题;
- PPO (Proximal Policy Optimization):通过限制策略更新幅度,提高了数据利用率和训练稳定性;
- A3C (Asynchronous Advantage Actor-Critic):利用异步并行训练多个智能体,加速训练过程,并提高了收敛性能。
4. 应用领域
强化学习已经在许多领域取得了显著的成果,包括但不限于:
- 游戏:AlphaGo、AlphaGo Zero 和 AlphaZero 通过强化学习击败了人类顶级棋手,展示了强化学习在围棋、象棋等游戏上的强大潜力;
- 机器人:强化学习被用于机器人控制,如教会机器人行走、抓取物体等;
- 自动驾驶:强化学习可以用于优化自动驾驶汽车的控制策略,提高道路安全和驾驶体验;
- 推荐系统:强化学习可以用于优化推荐策略,提高用户满意度和长期收益;
- 资源管理:强化学习可以用于优化资源分配问题,如数据中心能耗管理、通信网络流量控制等。
5. 总结
强化学习是一种通过与环境交互学习决策策略的机器学习方法。通过求解马尔可夫决策过程,强化学习旨在找到最优策略,使得长期累积奖励最大化。深度强化学习将深度学习和强化学习相结合,使得强化学习可以处理具有复杂状态空间的问题。强化学习在游戏、机器人、自动驾驶等领域取得了显著的成果。