Java零基础入门——使用jsoup进行初级网络爬虫
文章目录
-
-
- 0. 配置jsoup
- 1. 实战爬虫知乎
- 2. 实战汽车之家爬图
-
0. 配置jsoup
- 安装idea并打开创建class
- 打开idea,File->New->Project->Maven->Next----->Finish
- 在文件夹src->main->java下先创建package,再在该package下创建java class。
- 配置jsoup
把以下的文档复制粘贴到pom.xml:
org.jsoup
jsoup
1.10.2
1. 实战爬虫知乎
先使用jsoup获取网页的源代码,具体的,可以用Chrome浏览器打开该网页,右击查看源代码。
Document document=Jsoup.connect("https://www.zhihu.com/explore/recommendations")
.userAgent("Mozilla/4.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0)")
.get();
注:userAgent需要在网页中找对应的,具体的地方在:
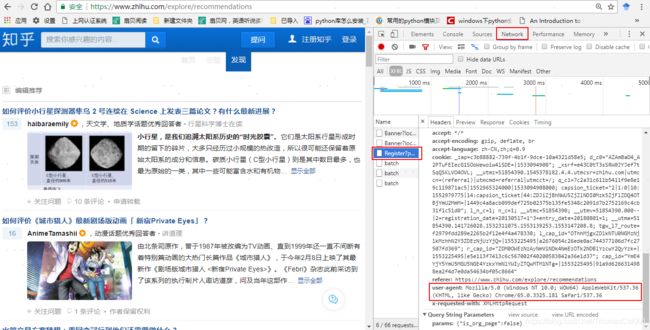
然后是找到url,具体也是通过网页的源代码中去找(其实,爬虫爬虫,爬的就是网页,所以所有的去网页的源代码中去找就对了),先贴源码:
Element main = document.getElementById("zh-recommend-list-full");
Elements url = main.select("div").select("h2").select("a[class=question_link]");
注: 其中,document.getElementById表示通过id定位到你要爬取的块,然后用.select定位到前缀包含这些限定词的所有url。
对应网页的源代码部分:
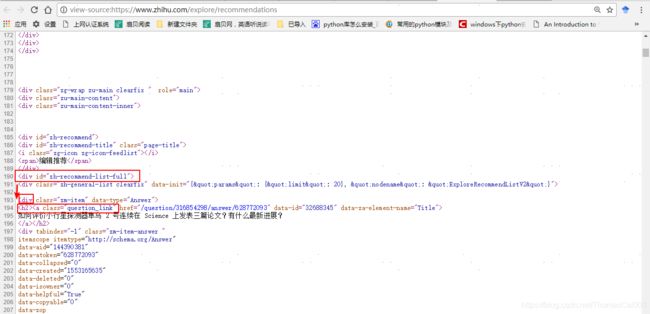
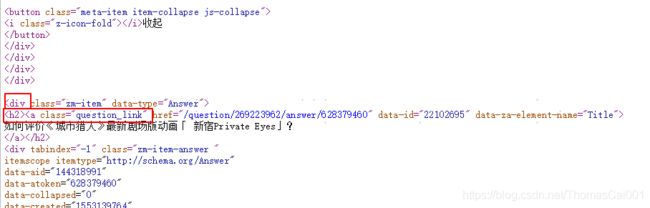
然后去遍历获取到的所有url
for(Element question:url)
并解析出单个问题的URL并连接,方式如上所述:
String URL=question.attr("abs:href");
Document document2=Jsoup.connect(URL)
.userAgent("Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36")
.get();
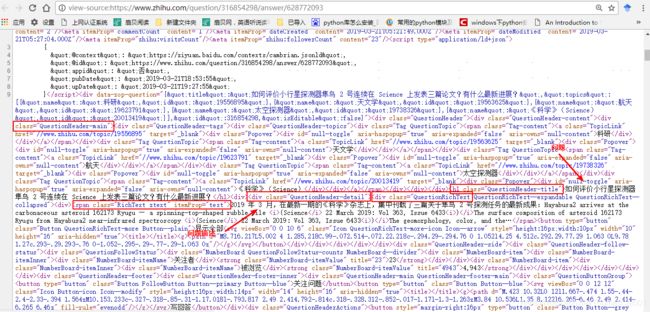
然后同样的方式获取问题、问题描述、回答:
//问题
Elements title=document2.select(".QuestionHeader-main").select(".QuestionHeader-title");
//问题描述
Elements detail=document2.select(".QuestionHeader-detail").select(".QuestionRichText").select("span[class=RichText ztext]span[itemprop=text]");
//回答
Elements answer=document2.select(".RichContent").select(".RichContent-inner").select("span[class=RichText ztext CopyrightRichText-richText]span[itemprop=text]");
最后打印出来就好了,以下是完整代码:
package spider;
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class spider {
public static void main(String[] args) throws IOException {
//获取编辑推荐页
Document document=Jsoup.connect("https://www.zhihu.com/explore/recommendations")
//模拟火狐浏览器
.userAgent("Mozilla/4.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0)")
.get();
Element main=document.getElementById("zh-recommend-list-full");
//System.out.println(main);
Elements url=main.select("div").select("h2").select("a[class=question_link]");
for(Element question:url){
//输出href后的值,即主页上每个关注问题的链接
String URL=question.attr("abs:href");
//下载问题链接指向的页面
Document document2=Jsoup.connect(URL)
.userAgent("Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36")
.get();
//问题
// Elements title=document2.select("#zh-question-title").select("h2").select("a");
Elements title=document2.select(".QuestionHeader-main").select(".QuestionHeader-title");
//问题描述
Elements detail=document2.select(".QuestionHeader-detail").
select(".QuestionRichText").select("span[class=RichText ztext]span[itemprop=text]");
//回答
Elements answer=document2.select(".RichContent").select(".RichContent-inner").select("span[class=RichText ztext CopyrightRichText-richText]span[itemprop=text]");
if(detail.size() == 0)
{
System.out.println("\n"+"链接:"+URL
+"\n"+"标题:"+title.text()
+"\n"+"问题描述:"+"无"
+"\n"+"回答:"+answer.text());
}
else
{
System.out.println("\n"+"链接:"+URL
+"\n"+"标题:"+title.text()
+"\n"+"问题描述:"+detail.text()
+"\n"+"回答:"+answer.text());
}
}
}
}
结果截图:
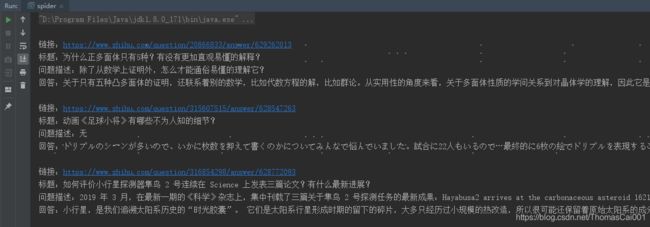
参考:https://blog.csdn.net/u014798883/article/details/54909951(原代码跑不通,本博文有改)
2. 实战汽车之家爬图
还是同样的思路,只不过这里是获取图片的
URL,然后下载图片就好了,这里下载图片的代码是copy别人的,原代码忘了网址,发现的朋友请告知一声,我贴上链接或者删掉,谢谢理解-。
这里就直接贴源码了:
package spider;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.IOException;
import java.io.File;
import java.io.IOException;
import java.io.*;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLConnection;
import java.net.URLEncoder;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
public class spider_picture {
private static void downImages(String filePath, String imgUrl) {
// 若指定文件夹没有,则先创建
File dir = new File(filePath);
if (!dir.exists()) {
dir.mkdirs();
}
// 截取图片文件名
String fileName = imgUrl.substring(imgUrl.lastIndexOf('/') + 1, imgUrl.length());
try {
// 文件名里面可能有中文或者空格,所以这里要进行处理。但空格又会被URLEncoder转义为加号
String urlTail = URLEncoder.encode(fileName, "UTF-8");
// 因此要将加号转化为UTF-8格式的%20
imgUrl = imgUrl.substring(0, imgUrl.lastIndexOf('/') + 1)
+ urlTail.replaceAll("\\+", "\\%20");
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
// 写出的路径
File file = new File(filePath + File.separator + fileName);
try {
// 获取图片URL
URL url = new URL(imgUrl);
// 获得连接
URLConnection connection = url.openConnection();
// 设置10秒的相应时间
connection.setConnectTimeout(10 * 1000);
// 获得输入流
InputStream in = connection.getInputStream();
// 获得输出流
BufferedOutputStream out = new BufferedOutputStream(new FileOutputStream(file));
// 构建缓冲区
byte[] buf = new byte[1024];
int size;
// 写入到文件
while (-1 != (size = in.read(buf))) {
out.write(buf, 0, size);
}
out.close();
in.close();
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) throws IOException {
//获取图片爬虫页
Document document = Jsoup.connect("https://car.autohome.com.cn/photolist/series/34231/4457966.html#pvareaid=3454450").
userAgent("Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36")
.get();
String id = "pa";
int n = 1;
while (n < 4) {
Element main=document.getElementById("pa" + n);
Elements url = main.select("li").select("img");
for(Element picture:url) {
//输出href后的值,即主页上每个关注问题的链接
String URL=picture.attr("abs:src");
System.out.println(URL);
downImages("d:/this_is_save_pictures_folder", URL);
}
n += 1;
}
}
}