java8 (jdk 1.8) 新特性 ——初步,发现不一样的新特性
前言


3202 年了,现在市面上的公司几乎都是 jdk1.8+, 有也是极少数在用java7 , 即使是一些传统企业,在技术革新方面也很重视,毕竟现在是大数据时代
那么java8 有哪些新特性呢?换句话说为什么在码界 这么受欢迎!!别急,我们慢慢来品
1. java8 的新特性
- List item
- Lamdba表达式
- Stream API
- 函数式接口
- 方法引用和构造引用
- 接口中的默认方法跟静态方法
- 新时间日期Api
- Optional
- 其他特性
后续的代码只要混个眼熟,先别管为什么这样写,后续章节会对8个特性进行解释 !!
Lamdba表达式 跟 Stream API 最为重要, 时间api 跟 optiona 属性 也是工作中常用的
常常听到一句话,“感受Lamdba 之美” ,美不美的我是不清楚,不过倒是方便了很多
简单看个例子 :
//获取class
List ids = Arrays.asList(1,2,3,4,5,6);
ids.forEach(id ->{
System.out.println(id);
});
可以看到最主要就是有个 箭头 ->
Stream API 就更不得了了,这东西 操作java中的数据就跟操作数据库一样
比如:
查询年龄大于20 的数据
mysql: (这边就直接用 * 了)
select * from user_info where age > 20
stream
package com.test1.demo;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.ToString;
@Data
@AllArgsConstructor
public class UserInfo {
private Integer id;
private String name;
private Integer age;
}
@Test
public void tes9(){
//获取class
List userList =new ArrayList<>();
userList.add(new UserInfo(1,"张三",19));
userList.add(new UserInfo(2,"李四",23));
userList.add(new UserInfo(3,"王五",25));
userList.add(new UserInfo(4,"赵六",18));
userList.stream().filter(s->s.getAge()>20).forEach(System.out::println);
}

先到这,今天最主要的不是了解这两个怎么用,就是混个眼熟
最主要的还是解决面试官 抛出的问题: 新特性的优点?
2. java8 的优点
- 速度更快
- 代码少、简洁
- 强大的Stream API
- 对并行流进行扩展和支持
- 解决空指针异常Optional
速度更快体现在哪里呢?
其主要原因还是 底层数据结构的变动,垃圾回收机制也就是内存结构的改动,对并行操作有了更好的扩展跟支持
底层数据结构最核心的就是 HashMap了,这个词不陌生
原来HashMap 是没有使用Hash表,无序,比较大小我们就得用 equals,如果我们往里边添加一个元素,假设不能重复,没有has表,也就是没有hash算法,就得跟每一个元素都equals 一次,数据少还好,要是一万次,效率极低
因此,采用了hash表,底层还是数组,采用hash 算法
什么是哈希表?
用一个例子来说明:
有这么24个篮球,编号分别为1-24,需要将篮球分成六组应该怎么分
这还不简单 :
编号 1 -4 第一组 5-8 第二组 9-12 第三组
编号 13-16 第四组 17-20 第五组 21-24 第六组
那如果我要找 16 号篮球球在哪个组呢? 这数据才24, 要找到也方便,要是数据量变大,成百上千,分成多个组,要快速找到想要的编号在哪个组,就显得困难了
这时候就推出了哈希,进行散列
具体实现:
分成6组
将 编号除 6 余数为0 的为 第零组:6、12、18、24
将 编号除 6 余数为1 的为 第一组:1、7、13、19
将 编号除 6 余数为2 的为 第二组:2、8、14、20
将 编号除 6 余数为3 的为 第三组:3、9、15、21
将 编号除 6 余数为4 的为 第四组:4、10、16、22
将 编号除 6 余数为5 的为 第五组:5、11、17、23
这要我们要找一个编号就很方便,比如找16,16%6 =4 16 在第四组 ,这种方式就是高效的散列,我们称之为Hash
来看看哈希的运行图解,还是以上述篮球分组为例:
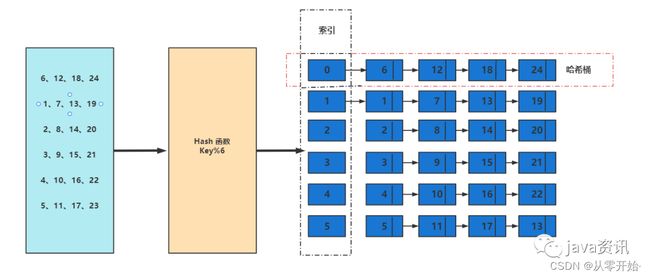
这里有几个概念:
key:就是编号
索引:数组的下标,可以快速定位,检索,我们分组的序号
哈希函数:将编号映射到索引上,采用的是取余方法 % 余数代表数组下标
哈希桶:保存索引的值的数组或链表,每个索引相同的元素以链表形式连接
通过上述,可以知道,这个存放数据的散列表就是我们说的哈希表
代码少、简洁 ,强大的Stream API
这两点前面我们进行简单案例就已经感受到了
对并行流进行扩展和支持
什么是并行流?
并行流就是将一个流的内容分成多个数据块,并用不同的线程分别处理每个不同数据块的流
现在有 一个学生 集合,我们知道学生总分,考试科目 为 7 科,求每个学生的平均分
package com.test1.demo;
import lombok.Data;
@Data
public class Student {
private Integer id;
private Double totalScore;
private Double average;
public Student(Integer id, Double totalScore) {
this.id = id;
this.totalScore = totalScore;
}
}
并行流:
@Test
public void tes10() {
//获取class
List userList = new ArrayList<>();
for (int i = 0; i < 30000; i++) {
userList.add(new Student(1, 600.00));
}
userList.parallelStream().forEach(stu -> {
stu.setAverage(stu.getTotalScore() / 7);
});
}
然而,并行流并不是随便用的,对于数据量较少的,不建议使用,数据量少用并行流反而适得其反,一般工作中基本的循环就够了
单核系统就更不要用了
解决空指针异常Optional
Optional 主要是用来对一个对象进行判空操作
例如之前
if (userInfo !=null) {
userInfo.getAge();
.....
}
现在
Optional.of(userInfo).get().getAge()
写到最后:
以上就是java8 新特性的初步认识了!!