Golang的trace性能分析
文章目录
-
- 一、trace概述
- 二、trace的使用方式
-
- 代码中trace采集
- 通过pprof采集
- 三、trace分析细节
-
- trace的web界面
- trace中需要关注的
-
- 关注GC的频率
- 关注goroutine调度情况
- 关注goroutine的数量
- 理想情况
- 四、GC分析
-
- 当前服务GC情况
- 设置GOGC
- 设置GOMEMLIMIT
- GC阈值的讨论
-
- GC的特点
- 五、goroutinue分析
-
- goroutine概览
- Sync block耗时分析
- Scheduler wait耗时分析
一、trace概述
上一篇是pprof的性能分析,通过pprof找到我们服务中的瓶颈点来进行优化。Golang的pprof性能分析
一般我们使用pprof的profile来分析服务的性能,主要是CPU方面的耗时和调用链路等。但是光靠profile是不够的,细节方面还是要使用trace分析并发和阻塞事件,goroutine的调度和GC情况。
相比profile,通过trace我们能看到什么呢?
1、程序运行中的goroutine数量分布
2、GC的频率和Heap的占比
3、goroutine的调度和运行,阻塞情况
二、trace的使用方式
代码中trace采集
import (
"os"
"runtime/trace"
)
func main() {
trace.Start(os.Stderr)
defer trace.Stop()
}
// 生成trace
go run main.go 2> trace.out
通过pprof采集
// trace采样
浏览器下载: http://127.0.0.1:6060/debug/pprof/trace?seconds=20
命令行采样: curl http://127.0.0.1:6060/debug/pprof/trace\?seconds\=20 > trace.out
// 运行采样的trace文件,会自动打开浏览器页面
go tool trace trace.out
三、trace分析细节
trace的web界面
参考:Go 大杀器之跟踪剖析 trace
https://eddycjy.gitbook.io/golang/di-9-ke-gong-ju/go-tool-trace
View trace:查看跟踪
Goroutine analysis:Goroutine 分析
Network blocking profile:网络阻塞概况
Synchronization blocking profile:同步阻塞概况
Syscall blocking profile:系统调用阻塞概况
Scheduler latency profile:调度延迟概况
User defined tasks:用户自定义任务
User defined regions:用户自定义区域
Minimum mutator utilization:最低 Mutator 利用率
trace中需要关注的
关注GC的频率
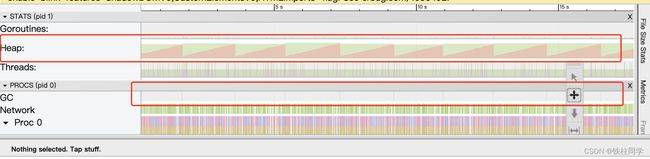
GC的频率过大,会导致大量的资源用于GC阶段,影响程序性能。另外要关注Heap的释放情况,Heap经过GC之后不释放那就需要关注内存泄漏问题了。内存泄漏大部分是查看goroutine释放和服务占用内存情况,可以参考Golang的pprof性能分析
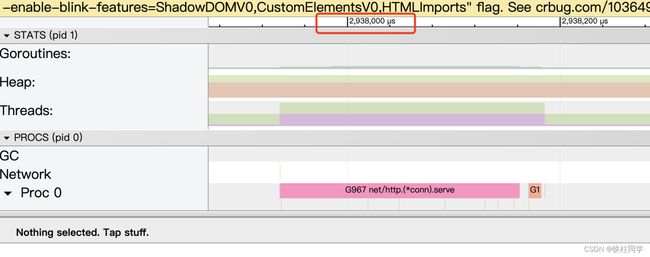
关注goroutine调度情况
鼠标放着不动,w是放大,s是缩小。一直放大可以查看具体goroutine的执行细节:
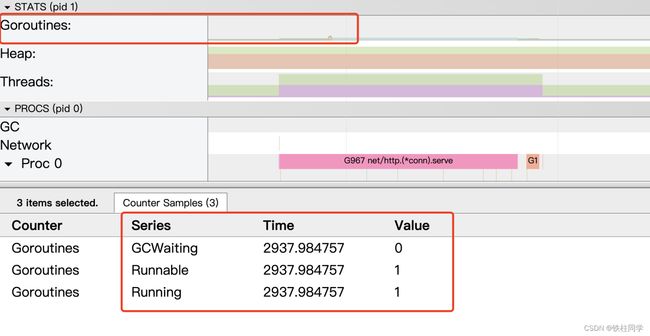
关注goroutine的数量
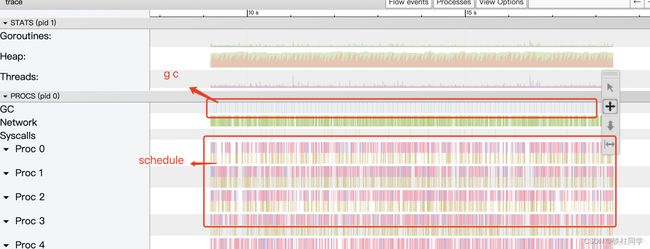
理想情况
1、GC次数适中,要多或者太小都不行
2、goutinue数量不会突增或者持续增加
3、goroutine的调度密集且有规律
下面这个就是GC过于频繁的例子。goroutine的调度还是不错的,有规律且密集
四、GC分析
当前服务GC情况

可以看到GC很频繁。查看监控发现,服务内存只用到了几十M.

这种情况只能手动改动GC的阈值了。
GOGC 变量设置初始垃圾收集目标百分比。当新分配的数据与上次收集后剩余
的实时数据的比率达到此百分比时,将触发收集。
默认值为 GOGC=100。
比如上次gc之后剩余10M,那么下次GC的阈值就是10M+10*100% = 20M
设置GOGC
// 调整gc阈值的源码
func readGOGC() int32 {
p := gogetenv("GOGC")
if p == "off" {
return -1
}
if n, ok := atoi32(p); ok {
return n
}
return 100
}
设置环境变量GOGC,然后查看trace:

设置GOMEMLIMIT
程序中GOGC设置成3000,实际上内存利用率还是很低,只有200M,服务给定的资源是4G!

GOMEMLIMIT : 设置GC的阈值(go 1.19提供),设置为服务限定资源的一半
GOGC=off : 关闭自动GC。
效果如下:

GC阈值的讨论
参考:官方对于GC的详细解释
GC的特点
1、当 GC 在标记和清除阶段之间转换时,短暂的 stop-the-world 暂停,
2、调度延迟,因为在标记阶段GC占用了25%的CPU资源,
3、用户 goroutines 协助 GC 响应高分配率,
4、当 GC 处于标记阶段时,指针写入需要额外的工作,并且
5、运行的 goroutines 必须暂停以扫描它们的根。
过多的GC会占用CPU和goroutine的资源。但是过少的GC会导致每次GC的stw时间变长,因为要标记和清楚的内存过多。因此GC阈值设置多大,也是个选择题。
五、goroutinue分析
参考:Golang GC核心要点和度量方法
goroutine概览
通过放大可以看到,goroutine的状态,有Dedicated的,有Idle的。还有处于mark标记状态的,有sweep的。

GC的三个主要阶段:mark(标记)、sweep(清扫)和 scan(扫描)。好了,跟八股文完美对上了。
红框中还有大名鼎鼎的STW。

标记阶段会将大概25%(gcBackgroundUtilization)的P用于标记对象,
逐个扫描所有G的堆栈,执行三色标记,在这个过程中,所有新分配的对象
都是黑色,被扫描的G会被暂停,扫描完成后恢复,这部分工作叫
后台标记(gcBgMarkWorker)。
这会降低系统大概25%的吞吐量,比如MAXPROCS=6,那么GC
P期望使用率为6*0.25=1.5,这150%P会通过专职(Dedicated)/
兼职(Fractional)/懒散(Idle)三种工作模式的Worker共同来完成。
Sync block耗时分析
从trace的 goroutine analysis 点进去查看主要的goroutine列表。

点进去就可以查看具体的goroutine执行情况。

点击查看goroutine,发现trace如下:

看起来146210这个goroutine进入了专职Dedicated GC处理工作模式。查看几个Sync block耗时比较长的发现都是在GC的时候,goroutine开始处理GC而暂停处理业务,等GC结束才会继续执行业务。 在优化过GC之后,Sync block耗时大幅度下降。
Scheduler wait耗时分析
大量的Scheduler wait如下:
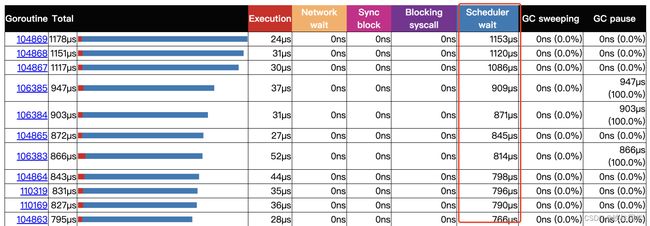
关于调度,我们都知道Go是GMP模型的调度,那么P的大小和goroutine的数量都会影响到调度性能。推荐使用uber的自动设置GOMAXPROCS的库。
uber开源的自动设置maxprocs的库
注意: 在服务分配的CPU不足1核的情况下,使用automaxprocs没什么提升。反而在多核的情况下,需要通过这个库来设置最佳的GOMAXPROCS
end