FlinkSQL行级权限解决方案及源码
FlinkSQL的行级权限解决方案及源码,支持面向用户级别的行级数据访问控制,即特定用户只能访问授权过的行,隐藏未授权的行数据。此方案是实时领域Flink的解决方案,类似离线数仓Hive中Ranger Row-level Filter方案。
源码地址: https://github.com/HamaWhiteGG/flink-sql-security
注: 此方案已产品化集成到实时计算平台Dinky,欢迎试用。
一、基础知识
1.1 行级权限
行级权限即横向数据安全保护,可以解决不同人员只允许访问不同数据行的问题。例如针对订单表,用户A只能查看到北京区域的数据,用户B只能查看到杭州区域的数据。

1.2 业务流程
1.2.1 设置行级权限
管理员配置用户、表、行级权限条件,例如下面的配置。
| 序号 | 用户名 | 表名 | 行级权限条件 |
|---|---|---|---|
| 1 | 用户A | orders | region = ‘beijing’ |
| 2 | 用户B | orders | region = ‘hangzhou’ |
1.2.2 用户查询数据
用户在系统上查询orders表的数据时,系统在底层查询时会根据该用户的行级权限条件来自动过滤数据,即让行级权限生效。
当用户A和用户B在执行下面相同的SQL时,会查看到不同的结果数据。
SELECT * FROM orders;
用户A查看到的结果数据是:
| order_id | order_date | customer_name | price | product_id | order_status | region |
|---|---|---|---|---|---|---|
| 10001 | 2020-07-30 10:08:22 | Jack | 50.50 | 102 | false | beijing |
| 10002 | 2020-07-30 10:11:09 | Sally | 15.00 | 105 | false | beijing |
注: 系统底层最终执行的SQL是:
SELECT * FROM orders WHERE region = 'beijing'。
用户B查看到的结果数据是:
| order_id | order_date | customer_name | price | product_id | order_status | region |
|---|---|---|---|---|---|---|
| 10003 | 2020-07-30 12:00:30 | Edward | 25.25 | 106 | false | hangzhou |
| 10004 | 2022-12-15 12:11:09 | John | 78.00 | 103 | false | hangzhou |
注: 系统底层最终执行的SQL是:
SELECT * FROM orders WHERE region = 'hangzhou'。
1.3 组件版本
| 组件名称 | 版本 | 备注 |
|---|---|---|
| Flink | 1.16.0 | |
| Flink-connector-mysql-cdc | 2.3.0 |
二、Hive行级权限解决方案
在离线数仓工具Hive领域,由于发展多年已有Ranger来支持表数据的行级权限控制,详见参考文献[2]。下图是在Ranger里配置Hive表行级过滤条件的页面,供参考。
但由于Flink实时数仓领域发展相对较短,Ranger还不支持FlinkSQL,以及要依赖Ranger会导致系统部署和运维过重,因此开始自研实时数仓的行级权限解决工具。
三、FlinkSQL行级权限解决方案
3.1 解决方案
3.1.1 FlinkSQL执行流程
可以参考作者文章[FlinkSQL字段血缘解决方案及源码],本文根据Flink1.16修正和简化后的执行流程如下图所示。

在CalciteParser.parse()处理后会得到一个SqlNode类型的抽象语法树(Abstract Syntax Tree,简称AST),本文会在Parse阶段,通过组装行级过滤条件生成新的AST来实现行级权限控制。
3.1.2 Calcite对象继承关系
下面章节要用到Calcite中的SqlNode、SqlCall、SqlIdentifier、SqlJoin、SqlBasicCall和SqlSelect等类,此处进行简单介绍以及展示它们间继承关系,以便读者阅读本文源码。
| 序号 | 类 | 介绍 |
|---|---|---|
| 1 | SqlNode | A SqlNode is a SQL parse tree. |
| 2 | SqlCall | A SqlCall is a call to an SqlOperator operator. |
| 3 | SqlIdentifier | A SqlIdentifier is an identifier, possibly compound. |
| 4 | SqlJoin | Parse tree node representing a JOIN clause. |
| 5 | SqlBasicCall | Implementation of SqlCall that keeps its operands in an array. |
| 6 | SqlSelect | A SqlSelect is a node of a parse tree which represents a select statement. |

3.1.3 解决思路
在Parser阶段,如果执行的SQL包含对表的查询操作,则一定会构建Calcite SqlSelect对象。因此限制表的行级权限,只要在构建Calcite SqlSelect对象时对Where条件进行拦截即可,而不需要解析用户执行的各种SQL来查找配置过行级权限条件约束的表。
在SqlSelect对象构造Where条件时,要通过执行用户和表名来查找配置的行级权限条件,系统会把此条件用CalciteParser提供的parseExpression(String sqlExpression)方法解析生成一个SqlBacicCall再返回。然后结合用户执行的SQL和配置的行级权限条件重新组装Where条件,即生成新的带行级过滤条件Abstract Syntax Tree,最后基于新的AST再执行后续的Validate、Convert、Optimize和Execute阶段。

以上整个过程对执行SQL的用户都是透明和无感知的,还是调用Flink自带的TableEnvironment.executeSql(String statement)方法即可。
注: 要通过技术手段把执行用户传递到Calcite SqlSelect中。
3.2 重写SQL
主要在org.apache.calcite.sql.SqlSelect的构造方法中完成。
3.2.1 主要流程
主流程如下图所示,根据From的类型进行不同的操作,例如针对SqlJoin类型,要分别遍历其left和right节点,而且要支持递归操作以便支持三张表及以上JOIN;针对SqlIdentifier类型,要额外判断下是否来自JOIN,如果是的话且JOIN时且未定义表别名,则用表名作为别名;针对SqlBasicCall类型,如果来自于子查询,说明已在子查询中组装过行级权限条件,则直接返回当前Where即可,否则分别取出表名和别名。
然后再获取行级权限条件解析后生成SqlBacicCall类型的Permissions,并给Permissions增加别名,最后把已有Where和Permissions进行组装生成新的Where,来作为SqlSelect对象的Where约束。
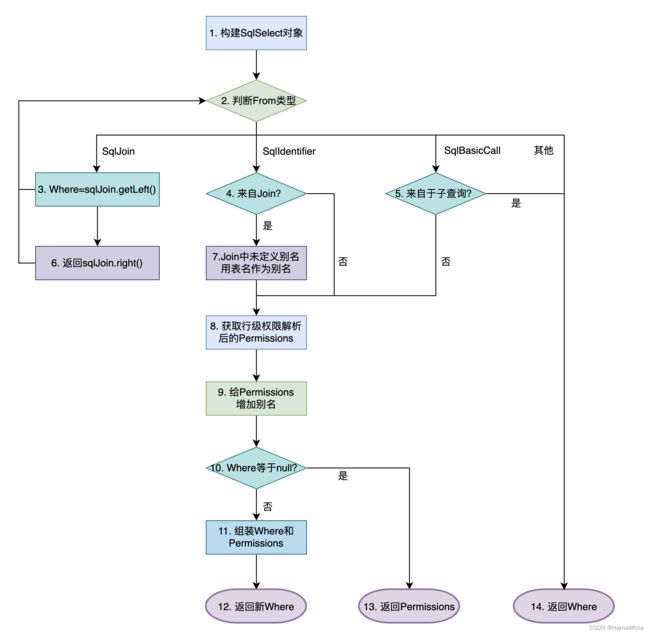
上述流程图的各个分支,都会在下面的用例测试章节中会举例说明。
3.2.2 核心源码
核心源码位于SqlSelect中新增的addCondition()、addPermission()、buildWhereClause()三个方法,下面只给出控制主流程addCondition()的源码。
/**
* The main process of controlling row-level permissions
*/
private SqlNode addCondition(SqlNode from, SqlNode where, boolean fromJoin) {
if (from instanceof SqlIdentifier) {
String tableName = from.toString();
// the table name is used as an alias for join
String tableAlias = fromJoin ? tableName : null;
return addPermission(where, tableName, tableAlias);
} else if (from instanceof SqlJoin) {
SqlJoin sqlJoin = (SqlJoin) from;
// support recursive processing, such as join for three tables, process left sqlNode
where = addCondition(sqlJoin.getLeft(), where, true);
// process right sqlNode
return addCondition(sqlJoin.getRight(), where, true);
} else if (from instanceof SqlBasicCall) {
// Table has an alias or comes from a subquery
SqlNode[] tableNodes = ((SqlBasicCall) from).getOperands();
/**
* If there is a subquery in the Join, row-level filtering has been appended to the subquery.
* What is returned here is the SqlSelect type, just return the original where directly
*/
if (!(tableNodes[0] instanceof SqlIdentifier)) {
return where;
}
String tableName = tableNodes[0].toString();
String tableAlias = tableNodes[1].toString();
return addPermission(where, tableName, tableAlias);
}
return where;
}
四、用例测试
用例测试数据来自于CDC Connectors for Apache Flink
[6]官网,在此表示感谢。下载本文源码后,可通过Maven运行单元测试。
$ cd flink-sql-security
$ mvn test
4.1 新建Mysql表及初始化数据
Mysql新建表语句及初始化数据SQL详见源码[flink-sql-security/data/database]里面的mysql_ddl.sql和mysql_init.sql文件,本文给orders表增加一个region字段。
4.2 新建Flink表
4.2.1 新建mysql cdc类型的orders表
DROP TABLE IF EXISTS orders;
CREATE TABLE IF NOT EXISTS orders (
order_id INT PRIMARY KEY NOT ENFORCED,
order_date TIMESTAMP(0),
customer_name STRING,
product_id INT,
price DECIMAL(10, 5),
order_status BOOLEAN,
region STRING
) WITH (
'connector'='mysql-cdc',
'hostname'='xxx.xxx.xxx.xxx',
'port'='3306',
'username'='root',
'password'='xxx',
'server-time-zone'='Asia/Shanghai',
'database-name'='demo',
'table-name'='orders'
);
4.2.2 新建mysql cdc类型的products表
DROP TABLE IF EXISTS products;
CREATE TABLE IF NOT EXISTS products (
id INT PRIMARY KEY NOT ENFORCED,
name STRING,
description STRING
) WITH (
'connector'='mysql-cdc',
'hostname'='xxx.xxx.xxx.xxx',
'port'='3306',
'username'='root',
'password'='xxx',
'server-time-zone'='Asia/Shanghai',
'database-name'='demo',
'table-name'='products'
);
4.2.3 新建mysql cdc类型shipments表
DROP TABLE IF EXISTS shipments;
CREATE TABLE IF NOT EXISTS shipments (
shipment_id INT PRIMARY KEY NOT ENFORCED,
order_id INT,
origin STRING,
destination STRING,
is_arrived BOOLEAN
) WITH (
'connector'='mysql-cdc',
'hostname'='xxx.xxx.xxx.xxx',
'port'='3306',
'username'='root',
'password'='xxx',
'server-time-zone'='Asia/Shanghai',
'database-name'='demo',
'table-name'='shipments'
);
4.2.4 新建print类型print_sink表
DROP TABLE IF EXISTS print_sink;
CREATE TABLE IF NOT EXISTS print_sink (
order_id INT PRIMARY KEY NOT ENFORCED,
order_date TIMESTAMP(0),
customer_name STRING,
product_id INT,
price DECIMAL(10, 5),
order_status BOOLEAN,
region STRING
) WITH (
'connector'='print'
);
4.3 测试用例
详细测试用例可查看源码中的单测,下面只描述部分测试点。
4.3.1 简单SELECT
4.3.1.1 行级权限条件
| 序号 | 用户名 | 表名 | 行级权限条件 |
|---|---|---|---|
| 1 | 用户A | orders | region = ‘beijing’ |
4.3.1.2 输入SQL
SELECT * FROM orders;
4.3.1.3 输出SQL
SELECT * FROM orders WHERE region = 'beijing';
4.3.1.4 测试小结
输入SQL中没有WHERE条件,只需要把行级过滤条件region = 'beijing'追加到WHERE后即可。
4.3.2 SELECT带复杂WHERE约束
4.3.2.1 行级权限条件
| 序号 | 用户名 | 表名 | 行级权限条件 |
|---|---|---|---|
| 1 | 用户A | orders | region = ‘beijing’ |
4.3.2.2 输入SQL
SELECT * FROM orders WHERE price > 45.0 OR customer_name = 'John';
4.3.2.3 输出SQL
SELECT * FROM orders WHERE (price > 45.0 OR customer_name = 'John') AND region = 'beijing';
4.3.2.4 测试小结
输入SQL中有两个约束条件,中间用的是OR,因此在组装region = 'beijing'时,要给已有的price > 45.0 OR customer_name = 'John'增加括号。
4.3.3 两表JOIN且含子查询
4.3.3.1 行级权限条件
| 序号 | 用户名 | 表名 | 行级权限条件 |
|---|---|---|---|
| 1 | 用户A | orders | region = ‘beijing’ |
4.3.3.2 输入SQL
SELECT
o.*,
p.name,
p.description
FROM
(SELECT
*
FROM
orders
WHERE
order_status = FALSE
) AS o
LEFT JOIN products AS p ON o.product_id = p.id
WHERE
o.price > 45.0 OR o.customer_name = 'John'
4.3.3.3 输出SQL
SELECT
o.*,
p.name,
p.description
FROM
(SELECT
*
FROM
orders
WHERE
order_status = FALSE AND region = 'beijing'
) AS o
LEFT JOIN products AS p ON o.product_id = p.id
WHERE
o.price > 45.0 OR o.customer_name = 'John'
4.3.3.4 测试小结
针对比较复杂的SQL,例如两表在JOIN时且其中左表来自于子查询SELECT * FROM orders WHERE order_status = FALSE,行级过滤条件region = 'beijing'只会追加到子查询的里面。
4.3.4 三表JOIN
4.3.4.1 行级权限条件
| 序号 | 用户名 | 表名 | 行级权限条件 |
|---|---|---|---|
| 1 | 用户A | orders | region = ‘beijing’ |
| 2 | 用户A | products | name = ‘hammer’ |
| 3 | 用户A | shipments | is_arrived = FALSE |
4.3.4.2 输入SQL
SELECT
o.*,
p.name,
p.description,
s.shipment_id,
s.origin,
s.destination,
s.is_arrived
FROM
orders AS o
LEFT JOIN products AS p ON o.product_id=p.id
LEFT JOIN shipments AS s ON o.order_id=s.order_id;
4.3.4.3 输出SQL
SELECT
o.*,
p.name,
p.description,
s.shipment_id,
s.origin,
s.destination,
s.is_arrived
FROM
orders AS o
LEFT JOIN products AS p ON o.product_id=p.id
LEFT JOIN shipments AS s ON o.order_id=s.order_id
WHERE
o.region='beijing'
AND p.name='hammer'
AND s.is_arrived=FALSE;
4.3.4.4 测试小结
三张表进行JOIN时,会分别获取orders、products、shipments三张表的行级权限条件: region = 'beijing'、name = 'hammer'和is_arrived = FALSE,然后增加orders表的别名o、products表的别名p、shipments表的别名s,最后组装到WHERE子句后面。
4.3.5 INSERT来自带子查询的SELECT
4.3.5.1 行级权限条件
| 序号 | 用户名 | 表名 | 行级权限条件 |
|---|---|---|---|
| 1 | 用户A | orders | region = ‘beijing’ |
4.3.5.2 输入SQL
INSERT INTO print_sink SELECT * FROM (SELECT * FROM orders);
4.3.5.3 输出SQL
INSERT INTO print_sink (SELECT * FROM (SELECT * FROM orders WHERE region = 'beijing'));
4.3.5.4 测试小结
无论运行SQL类型是INSERT、SELECT或者其他,只会找到查询oders表的子句,然后对其组装行级权限条件。
4.3.6 运行SQL
测试两个不同用户执行相同的SQL,两个用户的行级权限条件不一样。
4.3.6.1 行级权限条件
| 序号 | 用户名 | 表名 | 行级权限条件 |
|---|---|---|---|
| 1 | 用户A | orders | region = ‘beijing’ |
| 2 | 用户B | orders | region = ‘hangzhou’ |
4.3.6.2 输入SQL
SELECT * FROM orders;
4.3.6.3 执行SQL
用户A的真实执行SQL:
SELECT * FROM orders WHERE region = 'beijing';
用户B的真实执行SQL:
SELECT * FROM orders WHERE region = 'hangzhou';
4.3.6.4 测试小结
用户调用下面的执行方法,除传递要执行的SQL参数外,只需要额外指定执行的用户即可,便能自动按照行级权限限制来执行。
/**
* Execute the single sql with user permissions
*/
public TableResult execute(String username, String singleSql) {
System.setProperty(EXECUTE_USERNAME, username);
return tableEnv.executeSql(singleSql);
}
五、源码修改步骤
注: Flink版本1.16.0依赖的Calcite是1.26.0版本。
5.1 新增Parser和ParserImpl类
复制Flink源码中的org.apache.flink.table.delegation.Parser和org.apache.flink.table.planner.delegation.ParserImpl到项目下,新增下面两个方法及实现。
/**
* Parses a SQL expression into a {@link SqlNode}. The {@link SqlNode} is not yet validated.
*
* @param sqlExpression a SQL expression string to parse
* @return a parsed SQL node
* @throws SqlParserException if an exception is thrown when parsing the statement
*/
@Override
public SqlNode parseExpression(String sqlExpression) {
CalciteParser parser = calciteParserSupplier.get();
return parser.parseExpression(sqlExpression);
}
/**
* Entry point for parsing SQL queries and return the abstract syntax tree
*
* @param statement the SQL statement to evaluate
* @return abstract syntax tree
* @throws org.apache.flink.table.api.SqlParserException when failed to parse the statement
*/
@Override
public SqlNode parseSql(String statement) {
CalciteParser parser = calciteParserSupplier.get();
// use parseSqlList here because we need to support statement end with ';' in sql client.
SqlNodeList sqlNodeList = parser.parseSqlList(statement);
List<SqlNode> parsed = sqlNodeList.getList();
Preconditions.checkArgument(parsed.size() == 1, "only single statement supported");
return parsed.get(0);
}
5.2 新增SqlSelect类
复制Calcite源码中的org.apache.calcite.sql.SqlSelect到项目下,新增上文提到的addCondition()、addPermission()、buildWhereClause()三个方法。
并且在构造方法中注释掉原有的this.where = where行,并添加如下代码:
// add row level filter condition for where clause
SqlNode rowFilterWhere = addCondition(from, where, false);
if (rowFilterWhere != where) {
LOG.info("Rewritten SQL based on row-level privilege filtering for user [{}]", System.getProperty(EXECUTE_USERNAME));
}
this.where = rowFilterWhere;
5.3 封装SecurityContext类
新建SecurityContext类,主要添加下面三个方法:
/**
* Add row-level filter conditions and return new SQL
*/
public String addRowFilter(String username, String singleSql) {
System.setProperty(EXECUTE_USERNAME, username);
// in the modified SqlSelect, filter conditions will be added to the where clause
SqlNode parsedTree = tableEnv.getParser().parseSql(singleSql);
return parsedTree.toString();
}
/**
* Query the configured permission point according to the user name and table name, and return
* it to SqlBasicCall
*/
public SqlBasicCall queryPermissions(String username, String tableName) {
String permissions = rowLevelPermissions.get(username, tableName);
LOG.info("username: {}, tableName: {}, permissions: {}", username, tableName, permissions);
if (permissions != null) {
return (SqlBasicCall) tableEnv.getParser().parseExpression(permissions);
}
return null;
}
/**
* Execute the single sql with user permissions
*/
public TableResult execute(String username, String singleSql) {
System.setProperty(EXECUTE_USERNAME, username);
return tableEnv.executeSql(singleSql);
}
六、下一步计划
- 支持数据脱敏(Data Masking)
- 开发ranger-flink-plugin
七、参考文献
- 数据管理DMS-敏感数据管理-行级管控
- Apache Ranger Row-level Filter
- OpenLooKeng的行级权限控制
- PostgreSQL中的行级权限/数据权限/行安全策略
- FlinkSQL字段血缘解决方案及源码
- 基于 Flink CDC 构建 MySQL 和 Postgres 的 Streaming ETL