数据仓库技术与Hive入门
文章目录
- 数据仓库
-
- 基本概念
- 场景案例
- 主要特征
- 主流开发语言-SQL
-
- 数仓开发语言概述
- SQL语言介绍
- 结构化数据
- SQL语法分类
- Apache Hive入门
- Apache Hive 安装部署
-
- 元数据
- Hive SQL语言
数据仓库
基本概念

数据仓库(Data Warehouse,简称数仓、DW),是一个用于存储,分析,报告的数据系统
数据仓库的目的是构建面向分析的集成化数据环境,分析结构为企业提供决策支持
数据仓库与数据库不同,数据仓库专注分析
- 数据仓库本身并不“生产”任何数据,其数据来源于不同外部系统
- 同时数据仓库自身不需要“消费”任何数据,其结果开放给各个外部应用使用
这也是为什么叫做数仓,而不是工厂的原因

场景案例
业务数据的存储问题
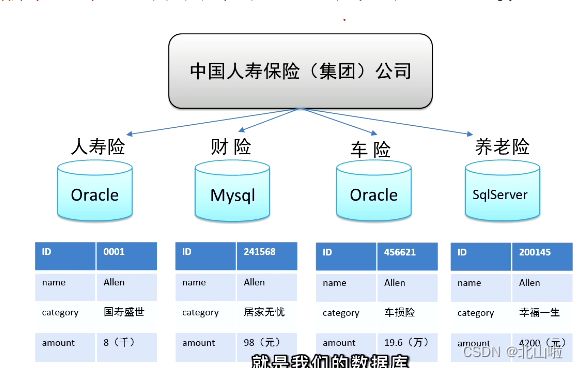
数据仓库是为了分析数据而来,分析结果给企业决策提供支持。以中国人寿保险公司发展为例,中国人寿保险公司有许多业务线:人寿险,财险、车险等。
联机事务处理系统(OLTP)

关系型数据库是OLPT典型应用,比如:Oracle、MySQL、SQL Server等
分析性决策的制定
但随着业务数据越来越多,产生了许多运营相关的困惑:理赔欺诈识别、险种恶化等,为了能够正确认识这些问题
为了能够正确认识这些问题,指定相关的解决措施,基于业务数据开展数据分析,基于分析的结果给决策提供支持,也就是所谓的数据驱动决策的指定

OLTP系统的核心是面向业务,支持业务,支持事务,所有的约为操作可以分为读、写两种操作,一般来说读的压力大于写的压力,利用OLTP环境进行分析,存在如下问题:
- 数据分析对数据进行读取操作,会让读取压力倍增
- OLTP仅存储数周或数月的数据
- 数据分布在不同系统不同表中,字段类型数据不同意
数据仓库构建

主要特征

数据仓库是分析数据的平台,而不是创造数据的平台
数据仓库的数据反映的是相当长的时间历史数据的内容
数据仓库中一般有大量的数据查询操作,但修改和删除操作很少
主流开发语言-SQL
数仓开发语言概述
在理论上,任何一款编程序言只要具备读写数据、处理数据的能力,都可以用于数仓的开发,例如:Python,JAVA、C等
关键在于编程语言是否易学、好用、功能是否强大,不论从学习成本还是开发效率,上述的编程语言不是很友好,在数据分析领域,不得不提的就是SQL,分析领域主流开发语言
SQL语言介绍
SQL:结构化查询语言(Structured Query Language),是一种数据据库查询和程序设计语言,用于存储数据已经更新和管理数据
SQL语言功能强大,核心功能秩序用9个动词,语法接近英语口语,用户很容易学习和使用

虽然SQL本身是为了数据库软件设计的,但在数据仓库领域,尤其是大数据仓库领域,很多数仓软件都会去支持SQL语法,原因在于用户学习SQL成本低,并且SQL对数据分析友好

结构化数据

SQL语法分类
SQL主要语法分为两个部分:数据定义语言(DDL)和数据操作语言(DML)
DDL:创建和删除表,以及数据库、索引等各种对象,但不涉及标中具体数据操作
create database --创建新数据库
create table -- 创建新表
DML:对表中的数据进行插入、更新、删除、查询等操作
select -- 获取数据
update -- 更新数据
delete --删除数据
insert -- 插入数据
Apache Hive入门

Hive是一款建立在Hadoop之上的开源 数据仓库系统,可以存储在Hadoop文件中的结构化、半结构化数据文件映射为一张数据库表,基于表提供一种类似SQL的查询模型,称为Hive查询语言(HQL),用于访问和分析存储在Hadoop文件中的大型数据集
Hadoop核心是将HQL转换为MapReduce程序,然后将程序提交到Hadoop集群执行
Hadoop由Facebook实现并开源
使用Hive处理数据的好处:
- 操作接口类SQL语法,提供快速开发的能力
- 避免直接写MapReduce,减少开发人员的学习成本
- 支持自定义函数,功能扩展很方便
- 背靠Hadoop,擅长存储分析海量数据集
映射信息记录
映射在数学上称为一种对应关系,在Hive中能够写sql处理的前提是针对表,而不是针对文件,因此需要将数据和表之间的对应关系描述记录清楚。映射信息专业的叫法称为元数据信息(metadata)

SQL语法解析、编译
用户写完sql之后,hive需要针对sql进行语法校验,并且根据记录的元数据信息进行读取sql背后的含义,指定执行计划,并且把执行计划转换成MapReduce程序来具体执行,把执行的结果封装返回给用户
最终效果

Apache Hive 安装部署
元数据
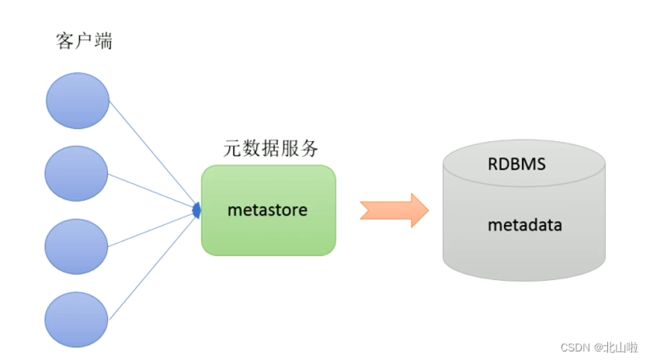
元数据(Metadata),又称中介数据、中继数据,位描述数据的数据,主要是描述数据属性的信息,用来支持如指示存储位置,历史数据,资源查找,文件记录等功能

Metastore即元数据服务,用来管理metadata元数据。就可以多个客户端同时连接,而且这些客户端不需要指导MySQL数据库的用户名和密码,只需要链接metastore服务即可,某种程度上保证了hive元数据的安全
启动Hive之前必须先启动Hadoop集群,特别需要注意,需要等待HDFS安全模式关闭之后再启动运行Hive,Hive不是分布式安装运行的软件,其分布式的特性主要由Hadoop完成,包括分布式存储、分布式计算。
Hive SQL语言
DDL建库建表
Hive数据模型总览

DDL(数据定义语言)语法核心由Create、alter和drop组成,DDL并不是恶疾表内部数据的操作

查看数据库、表结构
show databases; # 查看某个数据库
use 数据库; # 进入某个数据库
show tables; # 展示所有表
desc 表名; # 显示表结构
show partitions 表名; # 显示表名的分区
show create table_name; # 显示创建表的结构
建表
# 建表语句
# 内部表
use xxdb; create table xxx;
# 创建一个表,结构与其他一样
create table xxx like xxx;
# 外部表
use xxdb; create external table xxx;
# 分区表
use xxdb; create external table xxx (l int) partitoned by (d string)
# 内外部表转化
alter table table_name set TBLPROPROTIES ('EXTERNAL'='TRUE'); # 内部表转外部表
alter table table_name set TBLPROPROTIES ('EXTERNAL'='FALSE');# 外部表转内部表
表结构修改
# 表结构修改
# 重命名表
use xxxdb; alter table table_name rename to new_table_name;
# 增加字段
alter table table_name add columns (newcol1 int comment ‘新增’);
# 修改字段
alter table table_name change col_name new_col_name new_type;
# 删除字段(COLUMNS中只放保留的字段)
alter table table_name replace columns (col1 int,col2 string,col3 string);
# 删除表
use xxxdb; drop table table_name;
# 删除分区
# 注意:若是外部表,则还需要删除文件(hadoop fs -rm -r -f hdfspath)
alter table table_name drop if exists partitions (d=‘2016-07-01');
# 字段类型
# tinyint, smallint, int, bigint, float, decimal, boolean, string
# 复合数据类型
# struct, array, map