AI服务的并发处理【Python】
有一段时间,我专注于机器学习的研究方面,为不同的任务开发定制的机器学习解决方案。 但是最近,新项目进来了,有时自己负责初始部署比寻求其他开发人员的帮助更快。 我发现了几个在规模、易用性、定价等方面不同的部署选项。
今天,我们将讨论一种简单而强大的机器学习模型部署方法。 它允许我们同时处理多个请求并在需要时扩展应用程序。 我们还将讨论数据科学家在将机器学习模型投入生产时的职责,以及如何使用一些方便的 Python 工具对 Web 应用程序进行负载测试。

推荐:用 NSDT设计器 快速搭建可编程3D场景。
1、数据科学家的职责
你几乎可以为每项任务找到大量开源解决方案。 一些现有服务甚至可以处理数据验证和处理、数据存储、模型训练和评估、模型推理和监控等。
但是,如果你仍然需要定制解决方案怎么办? 你必须自己开发整个基础架构。 这就是我一直在思考的问题:数据科学家到底负责什么? 它只是模型本身,还是我们必须将其投入生产?
通常,数据科学家的职责因公司而异。 我和我的首席技术官讨论了这个问题。 我们讨论了数据科学家应该具备专业知识的一些案例。 他们应该能够将他们的解决方案作为 API 交付,将其容器化,并且理想情况下,开发解决方案以同时处理多个请求。
对于移动设备,通常向移动开发人员提供转换为相应格式的模型就足够了。 最重要的是,你可以提供文档来描述模型将什么作为输入以及它作为输出返回什么。
如果一个 Docker 容器无法处理预期的流量,数据科学家应该将进一步扩展委托给合适的专家。
2、Flask 和并发
我们将使用 Flask 作为一个简单应用程序的一部分来进行试验。 它是一个用 Python 构建的微型 Web 框架,旨在用于小型应用程序。
当收到请求时,此应用程序将向 httpbin.org 发送请求——这是一项可帮助你试验不同请求的服务。 发送请求后,我们的应用程序将收到两秒延迟的响应。 我们需要这种延迟来试验并发性。
from flask import Flask
import requests
import json
app = Flask(__name__)
@app.route('/')
def test_request():
response = requests.get('https://httpbin.org/delay/2').json()
return response
if __name__ == "__main__":
app.run(host='0.0.0.0')
纯 Python 有其“臭名昭著”的 GIL 限制,它实质上限制了一次只能运行一个 Python 线程(在此处阅读)。 如果希望应用程序在给定时间内处理更多请求,我们有两个选择:线程和多进程处理。 使用哪个取决于应用程序的瓶颈。
3、什么时候选择多线程?
只要存在等待时间,就应该使用多线程。 我们的应用程序的编写方式代表了典型的 I/O 绑定操作。 因此,大部分执行时间都花在了等待其他服务(如操作系统、数据库、互联网连接等)上。 在这种情况下,我们可以从多线程中获益,因为它有助于利用等待时间。
4、什么时候选择多进程?
另一方面,当你想要提高应用程序性能时,应该使用多处理。 假设我们的应用程序主动使用 CPU(例如,通过神经网络前向传递数据),其性能完全取决于 CPU 的计算能力。 此应用程序被描述为受 CPU 限制。 为了提高应用程序的性能,我们需要多处理。 与线程不同,我们创建单独的解释器实例并并行执行计算。
Flask 的内置服务器从 1.0 版本开始默认是线程化的。 那么,为什么不完全使用 Flask 部署应用程序呢? Flask 的网站明确指出“Flask 的内置服务器不适合生产”,因为它不能很好地扩展。
我们将在一分钟内查看另一个部署解决方案。 但首先,我建议测试应用程序以了解它处理负载的能力。
5、使用 Locust 进行负载测试
在向 API 发送流量之前对其进行负载测试非常重要。 一种方法是使用名为 Locust 的 Python 库。 它在本地主机上运行一个 Web 应用程序,并有一个简单的界面,允许我们自定义测试和可视化测试过程。
让我们在本地主机上的 Flask 应用程序上运行一些测试。
1)使用以下命令安装locust:
pip3 install locust
2)创建脚本并将其添加到我们的项目目录:
from locust import HttpUser, between, task
class MyWebsiteUser(HttpUser):
wait_time = between(5, 15)
@task
def load_main(self):
self.client.get("/")
3)使用以下命令运行应用程序:
python3 demo.py
4)使用另一个命令运行我们的负载测试应用程序:
locust -f load_testing.py --host=http://0.0.0.0:5000/
5)在浏览器中访问 http://localhost:8089,你会看到 Locust 界面
6)指定生成的唯一用户数和每秒发送的请求数
7)根据需要选择参数

6、测试多线程
现在我们来看看应用程序在有和没有启用多线程的情况下的测试。 它将使我们了解它是否有助于在给定时间内处理更多请求。 请记住,我们在从服务器获得响应之前设置了两秒的延迟。
下图是关闭多线程的情况:
...
if __name__ == "__main__":
app.run(host='0.0.0.0', threaded=False)
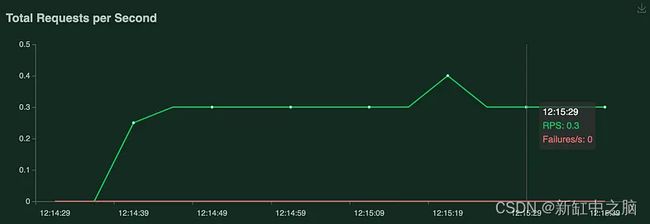
下一个测试是打开线程。 为此,请删除前面提到的参数。

如你所见,使用线程可以获得更高的 RPS(每秒请求数)率。
但是,如果我们开发一个应用程序来对图像进行分类呢? 此操作会主动使用我们的 CPU。 在这种情况下,与其使用线程,不如使用单独的进程来处理请求会更好。
7、使用uWSGI处理并发
要设置并发请求,我们需要使用 uWSGI。 它是一种允许我们更好地控制多处理和线程的工具。 uWSGI 为我们提供了足够的功能和灵活性来部署应用程序,同时仍然可以访问。
让我们更改之前创建的 Flask 应用程序,使其看起来更像一个真正的机器学习服务:
from flask import Flask
import numpy as np
import tensorflow as tf
app = Flask(__name__)
model = tf.keras.applications.MobileNetV2(input_shape=(160, 160, 3),
include_top=True,
weights='imagenet')
@app.route('/')
def predict():
data = np.zeros((1, 160, 160, 3))
model.predict(data)
return "Hello, World!"
if __name__ == "__main__":
app.run(host='0.0.0.0')
运行后,它会初始化模型。 每次收到模拟真实应用程序功能的请求时,它都会通过模型执行零数组的前向传递。
首先,让我们看一下没有 uWSGI 的应用程序的 RPS(每秒请求数):

关闭多线程

开启多线程
我们将“服务”作为一个纯 Flask 应用程序进行了测试,分别使用 threaded=False 和 threaded=True。 如你所见,虽然当 threaded=True 时 RPS 更高,但改善并不多。 这是因为应用程序仍然主要依赖于 CPU。
8、使用 uWSGI 进行测试
首先,我们需要安装uWSGI:
pip3 install uwsgi
然后,我们需要将配置文件添加到我们的项目目录中。 该文件包含 uWSGI 需要与我们的应用程序一起运行的所有参数。
[uwsgi]
module = demo:app
master = true
processes = 2
threads = 1
enable-threads = true
listen = 1024
need-app = true
http = 0.0.0.0:5000
让我们回顾一下你将在此配置文件中看到的最重要的参数:
- module = demo:app — 这是包含我们的 application:Flask 对象名称的脚本名称
- master = true — 这是重复调用 worker、记录和管理其他功能所必需的主要 uWSGI 进程。 在大多数情况下,这应该设置为“true”
- processes = 2 / threads = 1 — 这指定要运行的进程和线程的数量。 你还可以使用 uWSGI 的名为 cheaper 的子模块来自动缩放进程和线程的数量
- enable_threads = true — 这在多线程模式下运行 uWSGI
- listen=1024 — 这是请求队列的大小
- need-app = true——这个标志阻止uWSGI在找不到或无法运行应用程序时运行。 如果它等于 False,uWSGI 将忽略任何导入问题并返回请求的 500 状态。
- http = 0.0.0.0:5000 — 这是访问应用程序的 URL 和端口。 它仅在用户直接向应用程序发送请求时使用。
默认情况下,uWSGI 加载你的应用程序然后fork它。 但是你可以指定 lazy-apps = true。 这样,uWSGI 为每个 worker 分别加载你的应用程序。 它可以帮助避免 TensorFlow 模型错误或在工作人员之间共享其他数据。
另一个关键参数是 listen。 必须将此参数设置为你希望在重新加载期间排队的最大唯一用户数。 否则,其中一些可能会出错。 默认情况下,listen 等于 100。在此处阅读更多相关信息。
uWSGI 有更多有用的参数,但现在,让我们运行应用程序:
uwsgi uwsgi.ini
现在,我们可以查看封装到 uWSGI 中的 Flask 应用程序的负载测试结果:

uWSGI - 1个进程/2个线程

uWSGI - 2个进程/1个线程
使用两个单独的进程从根本上提高了 RPS。 但是,应用程序是受 I/O 限制还是受 CPU 限制并不总是很明显。 在多处理和多线程之间进行选择有点棘手。可以 看看这篇文章以获得更好的理解。
9、结束语
希望现在你明白为什么这个问题一直萦绕在我的脑海中。 数据科学家是否需要更多地关注让模型准备好部署,如果需要,限制是什么? 理想情况下,使用 Flask 和 uWSGI,你已经具备启动和运行它的基本要素。 但天空是极限,你的情况可能需要更多。
最后,如果你希望应用程序向全世界开放,应该注意安全性。 我们没有在本文中介绍安全性,因为它完全是另一个主题,但你应该牢记这一点。
一如既往,我希望这篇文章对你有用。 注意安全。
原文链接:AI服务的并发处理 — BimAnt