【无标题】
文章目录
- 神经网络的推理
-
- 神经网络的推理的全貌图
- 层的类化及正向传播的实现
- 神经网络的学习
-
- 损失函数
- 导数和梯度
- 链式法则
- 计算图
-
- 乘法节点
- 分支节点
- Repeat节点
- Sum节点
- MatMul节点
- 梯度的推导和反向传播的实现
-
- Sigmoid层
- Affine层
- Softmax with Loss层
神经网络的推理
神经网络的推理的全貌图
一、神经网络中进行的处理可以分为学习和推理两部分
二、神经网络就是一个函数。函数是将某些输入变换为某些输出的变换器,与此相同,神经网络也将输入变换为输出。
三、我们来考虑输入二维数据、输出三维数据的函数。为了使用神经网络进行实现,需要在输入层准备2个神经元,在输出层准备3个神经元。然后,在隐藏层(中间层)放置若干神经元,这里我们放置4个神经元。
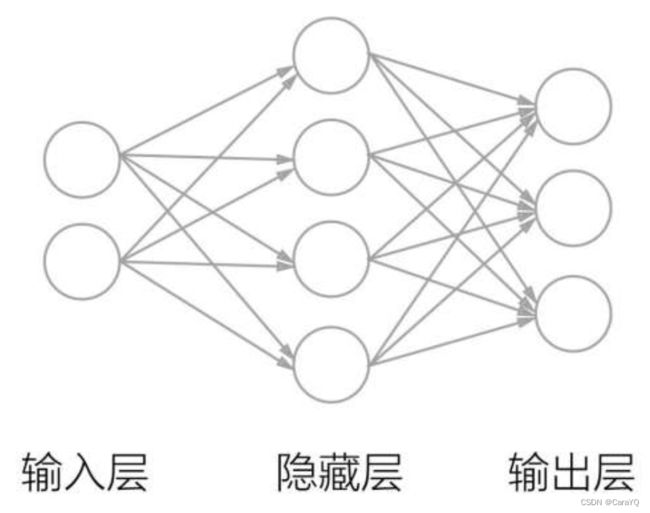
上图中,用〇表示神经元,用箭头表示它们的连接。此时,在箭头上有权重,这个权重和对应的神经元的值分别相乘,其和(严格地讲,是经过激活函数变换后的值)作为下一个神经元的输入。另外,此时还要加上一个不受前一层的神经元影响的常数,这个常数称为偏置。因为所有相邻的神经元之间都存在由箭头表示的连接,所以上图的神经网络称为全连接网络。
用(x1,x2)表示输入层的数据,用w11和w12表示权重,用b1表示偏置。这样一来,图1-7中的隐藏层的第1个神经元就可以如下进行计算:
![]()
所以,隐藏层的神经元是基于加权和计算出来的,并且可以通过矩阵乘积整体计算。实际上,基于全连接层的变换可以通过矩阵乘积如下进行整理:

这里,隐藏层的神经元被整理为(h1, h2, h3, h4),它可以看作1×4的矩阵(或者行向量)。另外,输入是(x1, x2),这是一个1×2的矩阵。再者,权重是2×4的矩阵,偏置是1×4的矩阵。这样一来,式(1.3)可以如下进行简化:
这里,输入是x,隐藏层的神经元是h,权重是W,偏置是b,这些都是矩阵。
四、我们将单独的样本数据保存在矩阵x的各行中,每行的一列表示一个特征
五、上面我们讲的全连接层的变换是线性变换。激活函数可以赋予它“非线性”的效果。激活函数有很多种,这里我们使用sigmoid函数(sigmoid function):

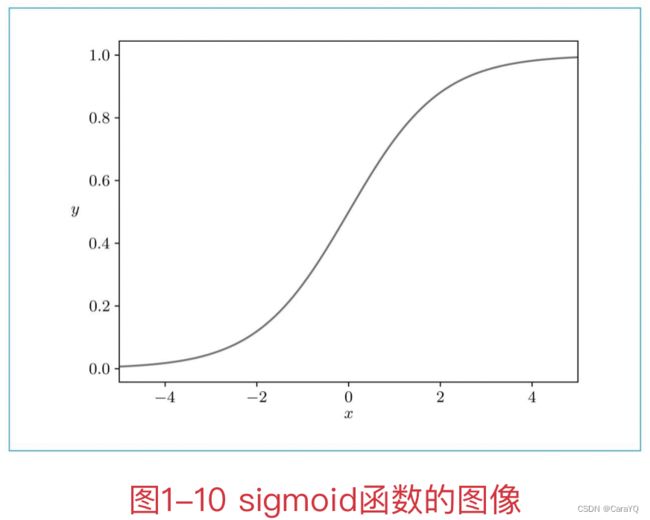
sigmoid函数接收任意大小的实数,输出0~1的实数。
使用非线性的激活函数,可以增强神经网络的表现力。
六、以上内容,使用python代码实现:
import numpy as np
# 定义sigmoid函数
def sigmoid(x):
return 1 / (1 + np.exp(-x))
x = np.random.randn(10, 2)# 生成一个10行2列具有标准正态分布的数组
W1 = np.random.randn(2, 4)
b1 = np.random.randn(4)
W2 = np.random.randn(4, 3)
b2 = np.random.randn(3)
h = np.dot(x, W1) + b1# np.dot():矩阵乘法运算
a = sigmoid(h)
s = np.dot(a, W2) + b2
七、上面的神经网络输出了三维数据。因此,使用各个维度的值,可以分为3个类别。在这种情况下,输出的三维向量的各个维度对应于各个类的“得分”(第1个神经元是第1个类别,第2个神经元是第2个类别……)。在实际进行分类时,寻找输出层神经元的最大值,将与该神经元对应的类别作为结果。
八、得分是计算概率之前的值。得分越高,这个神经元对应的类别的概率也越高。后面我们会看到,通过把得分输入Softmax函数,可以获得概率。
对于二分类问题,使用sigmoid激活函数;这里是多(三)分类问题,则使用software激活函数。
层的类化及正向传播的实现
一、将全连接层的变换实现为Affine层,将sigmoid函数的变换实现为Sigmoid层。因为全连接层的变换相当于几何学领域的仿射变换,所以称为Affine层。另外,将各个层实现为Python的类,将主要的变换实现为类的forward()方法。
二、神经网络的推理所进行的处理相当于神经网络的正向传播。顾名思义,正向传播是从输入层到输出层的传播。此时,构成神经网络的各层从输入向输出方向按顺序传播处理结果。之后我们会进行神经网络的学习,那时会按与正向传播相反的顺序传播数据(梯度),所以称为反向传播。
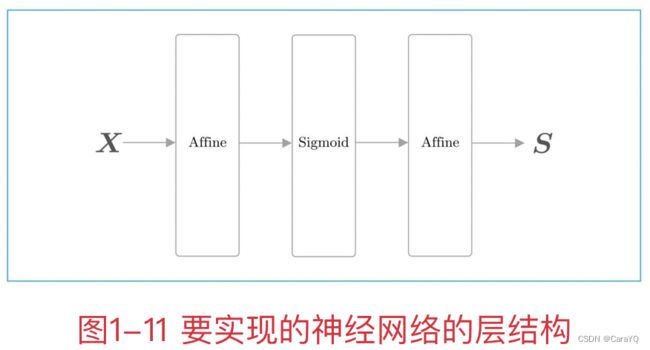
三、我们将这个神经网络实现为名为TwoLayerNet的类,将主推理处理实现为predict(x)方法。
class TwoLayerNet:
def__init__(self, input_size, hidden_size, output_size):
I, H, O = input_size, hidden_size, output_size
# 初始化权重和偏置
W1 = np.random.randn(I, H)
b1 = np.random.randn(H)
W2 = np.random.randn(H, O)
b2 = np.random.randn(O)
# 生成层
self.layers = [
Affine(W1, b1),
Sigmoid(),
Affine(W2, b2)
]
# 将所有的权重整理到列表中
self.params = []
for layer in self.layers:
self.params += layer.params
def predict(self, x):
for layer in self.layers:
x = layer.forward(x)
return x
我们使用TwoLayerNet类进行神经网络的推理。
x = np.random.randn(10, 2)
model = TwoLayerNet(2, 4, 3)
s = model.predict(x)
四、Python中可以使用+运算符进行列表之间的拼接。
>>> a = ['A' , 'B']
>>> a += ['C' , 'D']
>>> a
['A', 'B', 'C', 'D']
神经网络的学习
神经网络的学习任务是寻找最优参数,即找到损失尽可能小的参数。
损失函数
一、损失:评价神经网络学习得如何的一个指标
损失指示学习阶段中某个时间点的神经网络的性能。基于监督数据(学习阶段获得的正确解数据)和神经网络的预测结果,将模型的恶劣程度作为标量(单一数值)计算出来,得到的就是损失。
二、计算神经网络的损失要使用损失函数(loss function)。进行多类别分类的神经网络通常使用交叉熵误差(cross entropy error)作为损失函数。此时,交叉熵误差的值由神经网络输出的各类别的概率和监督标签求得。
三、将Softmax层和Cross Entropy Error层新添加到网络中。用Softmax层求Softmax函数的值,用Cross Entropy Error层求交叉熵误差。
X是输入数据,t是监督标签,L是损失。此时,Softmax层的输出是概率,该概率和监督标签被输入CrossEntropy Error层。
- Softmax函数可由下式表示:

式(1.6)当输出总共有n个时,计算第k个输出yk时的算式。这个yk是对应于第k个类别的Softmax函数的输出,yk对应于第k个类别的Softmax函数的输出。
Softmax函数的分子是得分sk的指数函数,分母是所有输入信号的指数函数的和。Softmax函数输出的各个元素是0.0~1.0的实数。另外,如果将这些元素全部加起来,则和为1。
- 交叉熵误差可由下式表示:

tk是对应于第k个类别的监督标签。log是以纳皮尔数e为底的对数(严格地说,应该记为loge)。监督标签以one-hot向量的形式表示,比如t=(0, 0, 1)。
one-hot向量是一个元素为1,其他元素为0的向量。因为元素1对应正确解的类,所以式(1.7)实际上只是在计算正确解标签为1的元素所对应的输出的自然对数(log)。
- 在考虑了mini-batch处理的情况下,交叉熵误差可以由下式表示:
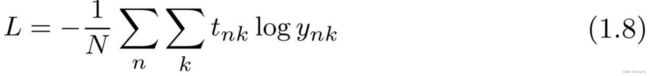
这里假设数据有N笔,tnk表示第n笔数据的第k维元素的值,ynk表示神经网络的输出,tnk表示监督标签。
式(1.8)除以N,可以求单笔数据的平均损失。通过这样的平均化,无论mini-batch的大小如何,都始终可以获得一致的指标。
导数和梯度
一、导数:这个dx/dy的意思是变化程度,就是x的无限小变化会导致y发生多大程度的变化。
二、梯度:
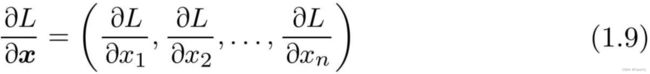
如式(1.9)将关于向量各个元素的导数罗列到一起,就得到了梯度(gradient)。
链式法则
一、学习阶段的神经网络在给定学习数据后会输出损失。这里我们想得到的是损失关于各个参数的梯度。只要得到了它们的梯度,就可以使用这些梯度进行参数更新。我们可以利用误差反向传播法求神经网络的梯度
二、理解误差反向传播法的关键是链式法则。链式法则是复合函数的求导法则,其中复合函数是由多个函数构成的函数。
三、这里考虑y=f(x)和z=g(y)这两个函数。如z=g(f(x))所示,最终的输出z由两个函数计算而来。此时,z关于x的导数可以按下式求得:

如式(1.11)所示,z关于x的导数由y=f(x)的导数和z=g(y)的导数之积求得,这就是链式法则。链式法则的重要之处在于,无论我们要处理的函数有多复杂(无论复合了多少个函数),都可以根据它们各自的导数来求复合函数的导数。也就是说,只要能够计算各个函数的局部的导数,就能基于它们的积计算最终的整体的导数。
用相应的神经网络来说明链式法则之所以可以实现反向传播就在于:无论我们处理的神经网络有多复杂(无论有多少层),都可以根据它们各自的梯度(的乘积)来计算输出层的梯度。也就是说,只要能计算各层的梯度,就可以基于它们的积计算最终(输出层)的梯度。
计算图
一、在计算图中,用节点表示计算,处理结果有序(本例中是从左到右)流动。这就是计算图的正向传播。
二、梯度沿与正向传播相反的方向传播,这个反方向的传播称为反向传播。
三、在神经网络的学习阶段,计算图的最终输出是损失,它是一个标量
四、如下图所示,处理z=x+y这一计算时,反向传播用蓝色的粗箭头表示,在箭头的下方标注传播的值。此时,传播的值是指最终的输出L关于各个变量的导数。
根据刚才复习的链式法则,反向传播中流动的导数的值是根据从上游(输出侧)传来的导数和各个运算节点的局部导数之积求得的。因此:
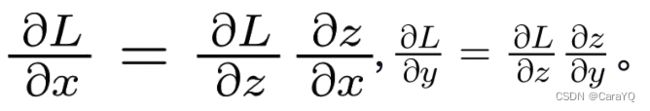
因为:
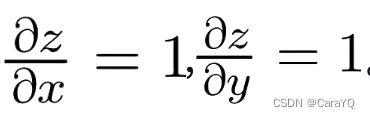
所以,如图1-18所示,加法节点将上游传来的值乘以1,再将该梯度向下游传播
五、在构成计算图的运算节点中,除了这里见到的加法节点之外,还有很多其他的运算节点。下面,我们将介绍几个典型的运算节点。
乘法节点

当张量流过加法节点(或者乘法节点)时,只需独立计算张量中的各个元素。也就是说,在这种情况下,张量的各个元素独立于其他元素进行对应元素的运算。
分支节点
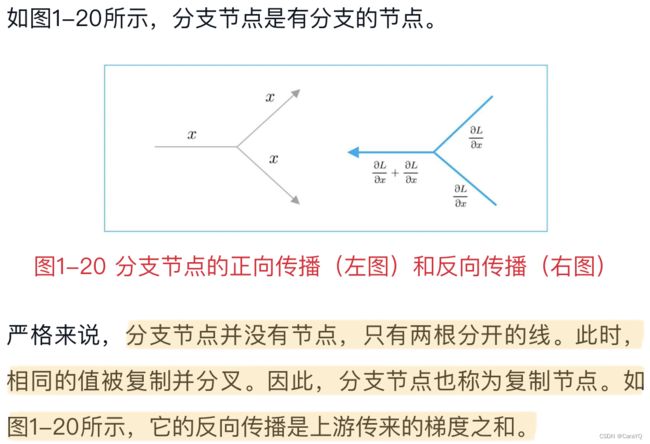
Repeat节点
分支节点有两个分支,但也可以扩展为N个分支(副本),这里称为Repeat节点。
>>> import numpy as np
>>> D , N = 8 , 7
>>> x = np.random.randn(1 , D) # 输入
>>> y = np.repeat(x , N , axis=0) # 正向传播
# 通过指定axis,可以指定沿哪个轴复制。
>>> dy = np.random.randn(N , D) # 假设的梯度
>>> dx = np.sum(dy , axis=0 , keepdims=True) # 反向传播
# 通过指定axis来指定对哪个轴求和。
# 另外,通过指定keepdims=True,可以维持二维数组的维数。
# 当keepdims=True时,np.sum()的结果的形状是(1,D);
# 当keepdims=False时,形状是(D,)。
NumPy的广播会复制数组的元素,也可以使用np.repeat()方法进行元素的复制
Sum节点
MatMul节点
一、将矩阵乘积称为MatMul节点
梯度的推导和反向传播的实现
Sigmoid层
Affine层
Softmax with Loss层
将Softmax函数和交叉熵误差一起实现为Softmax withLoss层。