GPT与GPT-2
GPT与GPT-2
GPT-2与GPT一样,都使用的是单向语言模型
一、GPT
GPT的底层架构是transformer,是由pre-training和fine-tuning两部分构成的。
如果GPT做成双向的,那就没Bert什么事了(不过Bert的Masked LM和Next Sentence Prediction的思想也是功不可没哒~)。之所以这么说,是因为Bert底层架构也是transformer,也是由pre-training和fine-tuning两部分构成的,只不过在transformer那采用的是双向而已~
下面,我们分别从GPT的pre-training、fine-tuning两部分来讲:
1. 无监督pre-training
pre-training是采用transformer框架进行的,不过对transformer改动了一小下。
我们知道transformer里有encoder层和decoder层,而GPT里主要用的是decoder层,不过做了一点改变,就是去掉了中间的Encoder-Decoder Attention层(因为没有encoder层,所以也就不需要Encoder-Decoder Attention这一层啦~)。也有人说用到的是encoder层,做的改变是将Multi-Head Attention换成了Masked Multi-Head Attention。
那么可能有人会问,这两种说法到底哪个正确呢?其实,这两种说法都对,因为仔细分析一下就会发现这两种说法是一个意思,不就是 Masked Multi-Head Attention + Feed Forward 嘛 ~ 如下图所示:
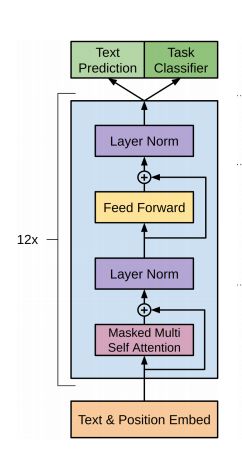
GPT Transformer
整个过程如上图所示,词向量(token embedding)和位置向量(position embedding)的和作为输入,经过12层的Masked Multi-Head Attention和Feed Forward(当然中间也包括Layer Norm),得到预测的向量和最后一个词的向量,最后一个词的词向量会作为后续fine-tuning的输入。
问题1:无监督训练的终止条件是什么呢?训练到什么时候可以停止呢?像聚类是训练到分类比较稳定的情况下就停止了~
答:我们可以通过准确率来评价训练何时停止。训练的时候生成的文本和原文本进行比对,得到准确率,通过准确率是否达到预期值或是准确率是否一直上下波动等来确定是否该停止训练。
2. 有监督fine-tuning
笔者对于微调的粗略理解:
先将大部分的参数通过无监督预训练训练好,然后通过微调确定最后一个参数w的值,以适应不同的任务。利用无监督最后一个词的向量作为微调的输入(个人认为其实可以整句话的词向量作为输入,但是没必要)。
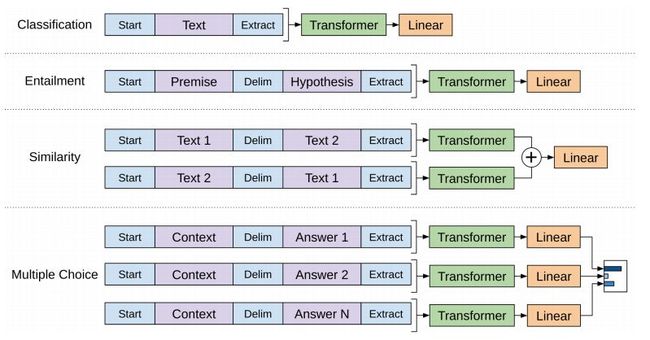
上图展示了对于不同NLP任务的微调过程:
分类任务:输入就是文本,最后一个词的向量直接作为微调的输入,得到最后的分类结果(可以多分类)
推理任务:输入是 先验+分隔符+假设,最后一个词的向量直接作为微调的输入,得到最后的分类结果,即:是否成立
句子相似性:输入是 两个句子相互颠倒,得到的最后一个词的向量再相加,然后进行Linear,得到最后分类结果,即:是否相似
问答任务:输入是上下文和问题放在一起与多个回答,中间也是分隔符分隔,对于每个回答构成的句子的最后一个词的向量作为微调的输入,然后进行Linear,将多个Linear的结果进行softmax,得到最后概率最大的
问题2:对于问答任务,最后多个Linear的结果如何进行softmax?
对于问答任务来说,一个问题对应多个回答,而最后我要取最准确的回答(分值最高)作为结果,我通过对多对问题答案做transformer后,再分别做linear,可以将维度统一,然后对多个linear进行softmax~之前都是对一个linear做softmax,直接取概率值最大的即可,但是现在多个linear如何进行softmax呢?
以上就是GPT的大致描述,采用无监督的预训练和有监督的微调可以实现大部分的NLP任务,而且效果显著,但是还是不如Bert的效果好。不过GPT采用单向transformer可以解决Bert无法解决的生成文本任务。
二、GPT-2
GPT-2依然沿用GPT单向transformer的模式,只不过做了一些改进与改变。那GPT-2相对于GPT有哪些不同呢?看看下面几方面:
1. GPT-2去掉了fine-tuning层:不再针对不同任务分别进行微调建模,而是不定义这个模型应该做什么任务,模型会自动识别出来需要做什么任务。这就好比一个人博览群书,你问他什么类型的问题,他都可以顺手拈来,GPT-2就是这样一个博览群书的模型。
2. 增加数据集:既然要博览群书,当然得先有书,所以GPT-2收集了更加广泛、数量更多的语料组成数据集。该数据集包含800万个网页,大小为40G。当然这些数据集是过滤后得到的高质量文本,这样效果才能更好的哦~
3. 增加网络参数:GPT-2将Transformer堆叠的层数增加到48层,隐层的维度为1600,参数量更是达到了15亿。15亿什么概念呢,Bert的参数量也才只有3亿哦~当然,这样的参数量也不是说谁都能达到的,这也得取决于money的多少啊~
4. 调整transformer:将layer normalization放到每个sub-block之前,并在最后一个Self-attention后再增加一个layer normalization。论文中这块感觉说的模棱两可,如果给个图就好了。不过可以通过代码了解这一细节,下图是我理解如何加layer normalization的示意图,给大家做个参考~~~
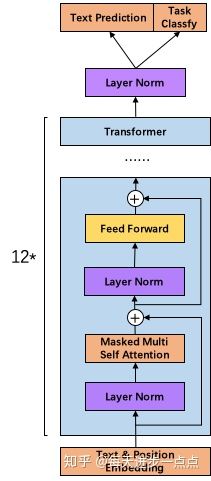
GPT-2 Transformer
5. 其他:GPT-2将词汇表数量增加到50257个;最大的上下文大小 (context size) 从GPT的512提升到了1024 tokens;batchsize增加到512。
三、总结
GPT-2理论部分基本就是这样,可以看到GPT-2在GPT基础上的创新不大,都是用transformer单向建预研模型,只不过是规模要大很多。因此效果也是真的好,目前的效果甚至超过了Bert。
值得一提的是,GPT-2将fine-tuning去掉后,引入大量的训练文本,效果就非常好,这也说明只要训练文本够大,网络够大,模型是可以自己根据输入内容判断需要做的任务是什么的。
突然想起来,还有一点忘了说~
GPT-2的输入是完全的文本,什么提示都不加吗?
当然不是,它也会加入提示词,比如:“TL;DR:”,GPT-2模型就会知道是做摘要工作了。输入的格式就是 文本+TL;DR:,然后就等待输出就行了~