项目Es、kafka、mysql容量评估方案和服务器资源预估方案
目录
1、Es 评估计划
一个接口jmeter压测qps 1万, logstash 读取日志文件写入es
Logstash配置
Es容量变化前后差值/1万 * 1.67 * (1+副本数) ~= 次接口es 容量 (日志数据30kb)
影响es存储的主要原因
通过 kibana 查看 堆栈》索引》
通过数据中的值 / 压测的数量 = 平均容量
编辑
服务器资源预估计算公式
多级别预估
2、Kafka评估计划
基准测试
创建test主题
基准测试 生产数据
基准测试 消费数据
先用程序插入1万条当前业务数据
使用如下命令 查看主题占用大小
容量计算规则参考es 建议定期清理时间设置方案
体量计算
3、Mysql 评估计划
普遍上浮情况
1、Es 评估计划
一个接口jmeter压测qps 1万, logstash 读取日志文件写入es
Jmeter 配置简单 配置一个http 加执行1万次请求即可
-
Logstash配置
input{
file{
path=>["D:/export/log/autxxsystem/automatxxsystem_detail.log"]
start_position=>"beginning"
}
}
filter{
grok {
match => {"message" => "%{LOGLEVEL:loglevel} "}
}
}
output{
elasticsearch{
hosts=>["127.0.0.1:9200"]
index => "logstash2-%{+yyyy.MM.dd}"
}
stdout{
codec=>rubydebug
}
}
Es容量变化前后差值/1万 * 1.67 * (1+副本数) ~= 次接口es 容量 (日志数据30kb)
-
影响es存储的主要原因
| 副本数量 |
建议副本数量为1 |
| 数据膨胀 |
除原始数据外,ES 需要存储索引、列存数据等,一般膨胀10% |
| 内部任务开销 |
ES 占用约20%的磁盘空间,用于 segment 合并、ES Translog、日志等 |
| 操作系统预留 |
Linux 操作系统默认为 root 用户预留5%的磁盘空间,用于关键流程处理、系统恢复、防止磁盘碎片化问题等 |
| 估算公式 |
|
| 实际空间估算公式 |
实际空间 = 源数据 × (1 + 副本数量) × (1 + 数据膨胀) / (1 - 内部任务开销) / (1 - 操作系统预留) |
| 存储容量估算公式(预留15%的存储空间) |
存储容量 = 源数据 × (1 + 副本数量) × 1.45 × (1 + 预留空间) |
-
通过 kibana 查看 堆栈》索引》

-
通过数据中的值 / 压测的数量 = 平均容量
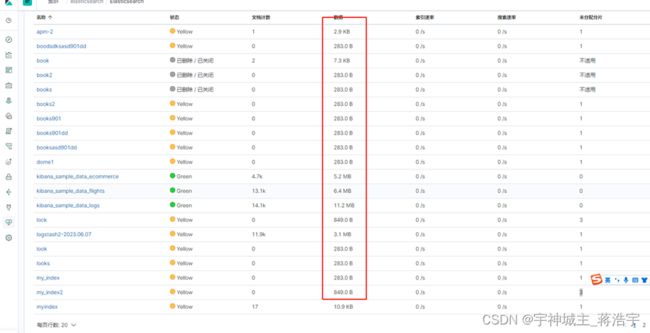
服务器资源预估计算公式
- 日调用 60tps * 60s * 60m * 24h = 5,184,000 (日500万)笔
- 每天生产 500万笔 * ES 每笔平均容量30kb ~= 155520000kb /1024 =151875M /1024 = 148GB
- 可以支持(总6T / 日容量 148Gb = 40)天数
多级别预估
- 日调用 1000万比 6T 可支持天数
- 日调用 5000万笔 6T 可支持天数
- 日调用1亿笔 6T 可支持天数
2、Kafka评估计划
基准测试
创建test主题
kafka-topics.bat --create --topic test6 --bootstrap-server localhost:9092 --partitions 1 --replication-factor 1
基准测试 生产数据
kafka-producer-perf-test.bat --topic test6 --num-records 500 --throughput -1 --record-size 1000 --producer-props bootstrap.servers=localhost:9092 acks=1
bin/kafka-producer-perf-test.sh
--topic topic的名字
--num-records 总共指定生产数据量(默认5000W)
--throughput 指定吞吐量——限流(-1不指定)
--record-size record数据大小(字节)
--producer-props bootstrap.servers=192.168.1.20:9092,192.168.1.21:9092,192.168.1.22:9092 acks=1 指定Kafka集群地址,ACK模式
日志
500 records sent, 1014.198783 records/sec (0.97 MB/sec), 30.99 ms avg latency, 443.00 ms max latency, 30 ms 50th, 32 ms 95th, 34 ms 99th, 443 ms 99.9th.
发送了500条记录,1014.198783条记录/秒(0.97 MB/秒),平均延迟30.99毫秒,最大延迟443.00毫秒,第50条30毫秒,第95条32毫秒,第99条34毫秒,第99.9条443毫秒。
基准测试 消费数据
#命令
kafka-consumer-perf-test.bat --broker-list localhost:9092 --topic test6 --fetch-size 1048576 --messages 500
#介绍
bin/kafka-consumer-perf-test.sh
--broker-list 指定kafka集群地址
--topic
指定topic的名称
--fetch-size 每次拉取的数据大小
--messages 总共要消费的消息个数
#日志
start.time, end.time, data.consumed.in.MB, MB.sec, data.consumed.in.nMsg, nMsg.sec, rebalance.time.ms, fetch.time.ms, fetch.MB.sec, fetch.nMsg.sec
2023-06-14 18:18:28:927, 2023-06-14 18:18:29:576, 0.4768, 0.7347, 500, 770.4160, 531, 118, 4.0410, 4237.2881
开始时间、结束时间、在MB中的数据消耗、MB.sec、在.nMsg中的数据损耗、nMsg.sec、再平衡时间.ms、回迁时间.ms,回迁MB秒、回迁.nMsg.sec
2023-06-14 18:18:28:927、2023-06-16 18:18:29:576、0.4768、0.7347、500、770.4160、531、118、4.0410、4237.2881
先用程序插入1万条当前业务数据
3个消息生产者,3个消息消费者
使用如下命令 查看主题占用大小
>kafka-log-dirs.bat --describe --bootstrap-server localhost:9092 --topic-list "test"
Querying brokers for log directories information
Received log directory information from brokers 0
{"version":1,"brokers":[{"broker":0,"logDirs":[{"logDir":"D:\\tmp\\kafka-logs","error":null,"partitions":[{"partition":"test-0","size":163026,"offsetLag":0,"isFuture":false}]}]}]}
D:\kf\kafka_2.12-3.4.0\bin\windows>
size":163026, bytes 163026/1024 = 159 kb
容量计算规则参考es 建议定期清理时间设置方案
多少磁盘支持多少天 、建议定期清理时间设置方案
网络一般采用千兆光纤
内存对应几台机器默认设置机器一半jvm
4c8g 一半使用 4g 堆大小然后横向扩展
体量计算
按照 60 tps * 60s * 60m *24h = 日 5百万多点qps
按照 120 tps * 60s * 60m *24h = 日 1千万多点qps
按照 1200 tps * 60s * 60m *24h = 日 1亿多点qps
按照 12000 tps * 60s * 60m *24h = 日 10亿多点qps
按照这个比例更具自己业务规模提前做好扩容准备
根据基础资源大小服务器数量 横向扩展(通过增加机器实现扩容,可别想着提升技术实现降低成本)
正确的思想更具大厂经验建议(空间换技术)也就是机器多换技术简单(别把技术玩的太极限,亏钱的时候剩下那点就是九牛一毛,所以建议靠谱技术加横向扩展机器为最稳定方案)
3、Mysql 评估计划
查看表大小通过工具查看

数据库可视化工具一般都有 我用的是 dbeaver
计算方式 发送一万条数据 avg每条多少大小
计算avg 日 使用 大小 kb
计算磁盘 几t 在 日 百万qps 环境下 可支持 几天
计算磁盘 几t 在 日 百万qps 环境下 可支持 几天
计算磁盘 几t 在 日 百万qps 环境下 可支持 几天
计算磁盘 几t 在 日 千万qps 环境下 可支持 几天
计算磁盘 几t 在 日 千万qps 环境下 可支持 几天
计算磁盘 几t 在 日 千万qps 环境下 可支持 几天
普遍上浮情况
- 618 双十一 流量上浮 提前预估 20~30% 预备容量
- 具体更具业务分析上浮容量
ok
持续更新