即插即用 | S-FPN全新的金字塔网络,更适合轻量化模型的FPN
FPN(特征金字塔网络)已经成为大多数优秀One-Stage检测器的基本组成部分。以往的许多研究已经多次证明,FPN可以让多尺度特征图更好、更精确地描述不同大小的目标。然而,对于大多数Backbone,如VGG、ResNet或DenseNet,由于池化操作或与stride=2的卷积,每一层的特征映射都被缩小,使得其FPN不能更好地融合这些特征。
本文提出了一种新的金字塔网络,SFPN(合成融合金字塔网络),该结构在原始FPN层之间创建各种合成层,以提高轻量CNN Backbone的精度,更准确地提取目标的视觉特征。最后,实验证明了SFPN架构对于各种Backbone的有效性。

计算机视觉研究院推荐搜索关键词列表:目标检测yolo深度学习
1简介
过去的许多研究表明,特征金字塔中的特征图可以在不同尺度上捕捉物体的视觉特征。浅层保留了细节,如纹理、角落等;深层覆盖了更广泛的语义特征。在真实的场景中,不同大小的物体经常出现在一起,如何同时检测它们成为一个关键问题。而FPN的出现显著提高了目标检测性能,并成为大多数SoTA目标检测器的标准组成部分。
然而,这个FPN中的映射在x和y方向上都被缩放为1/2、1/4、1/8等等。FPN相邻两层之间的尺度差距很大,导致2个大小相似的物体被预测并分到为不同的层。例如,2个维度为32×32和31×31的目标在FPN中位于不同的预测图上。这种尺度截断问题可以通过在这个FPN中添加一个合成层来改进。
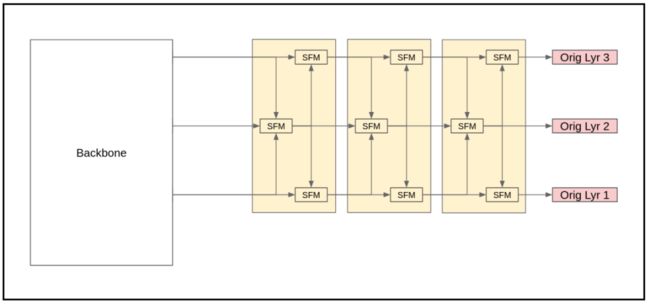
图2-a SFPN基本结构,SFPN-3
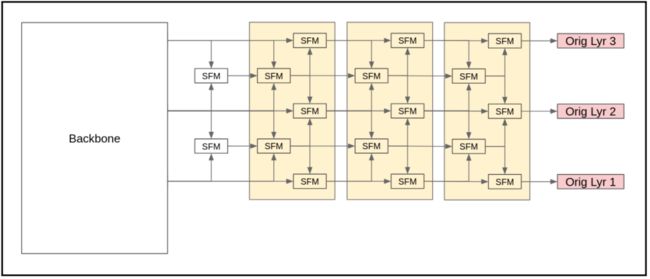
图2-b SFPN基本结构,SFPN-5
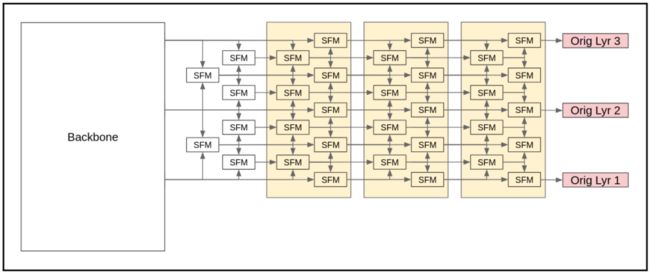
图2-c SFPN基本结构,SFPN-9
本文提出了一种新的金字塔网络SFPN(见图2),将密度图缩放为1/2、1/3、1/4、1/6等,以减少尺度截断的影响。作者相信添加中等尺度的特征图可以使不同尺度的过渡更平滑,从而更好地在轻量级体系结构上检测目标。基于这个想法构建了一个只有3个输出层的Baseline,然后逐步综合插入中间尺度的层。fpn被称为融合金字塔网络(SFPN)。
然后,将SFPN分别集成在VGG-16和MobileNetV2上,并在MS-COCO数据集中进行评估。不出所料发现大型和轻量级的Backbone都可以从合成层中获益。同样的方案再次应用于将最终的输出层分离到更多的层,令人惊讶的是,它仍然优于Baseline。
此外,作者可视化了SFPN的证据图,以显示合成层如何帮助模型更好地适应目标。合成层可以使原始层为目标表示保留更多的信息。这些发现证实了合成层的性能增益。
2相关方法
2.1 多尺度预测
目标检测是计算机视觉中一个非常活跃的领域,根据其网络体系结构可以分为两类:两阶段方法和单阶段方法。一般来说,Faster-RCNN等两阶段方法可以获得较高的检测精度,但计算时间较长,而YOL等单阶段方法运行速度较快,但精度较低。本文专注于对单阶段的调研。
SSD采用了网络内的多重特征图来检测具有不同形状和大小的目标。多特征设计使SSD比YOLOv1具有更好的鲁棒性。为了更好地检测小目标,基于FPN的特征金字塔网络(FPN)以对小目标实现更高的检测精度。目前,FPN被广泛应用于SoTA检测器中,用于检测不同尺度的目标,从自上而下路径的最后一层提取空间和上下文特征,以进行精确的目标检测。这种自顶向下聚合现在是在两阶段和单阶段检测器中提高尺度不变性的常用做法。
2.2 双向FPN
众所周知,由于池化的移位效应,FPN中的自上而下的路径不能保持准确的目标定位。双向FPN可以从浅层中恢复丢失的信息,提高小目标检测能力。例如,PANet在自底向上之后增加了自上向上的方向,显著提高了FPN的表达能力。在LRF中构建了轻量级scratch网络和双向网络,以高效地传播低级和高级语义信息。在NAS-FPN的启发下提出了一种BiFPN,以更好地、更高效地检测小物体。最近的YOLOv4修改了路径聚合方法PANet用add替换了cat方法,以更好地检测小目标。以上所有方法均证明了该FPN在两个方向上的性能优于原始FPN。
3本文方法
CNN Backbone中使用的池化操作(或与stride=2卷积)通常将图像维度降到一半,使特征图在x和y方向上缩放到1/2、1/4、1/8,以此类推。作者认为尺度差距太大,导致各层的特征融合不平滑。如图2所示,在原始层之间创建各种合成层,使预测图缩放到1/2、1/3、1/4、1/6等,从而提供一个更平滑的尺度空间来拟合尺度不断变化的GT。本部分将描述如何生成这些合成层。在此之后可视化SFPN,以显示合成层扫描如何帮助模型更好地拟合和检测对象。
3.1 合成融合模块(SFM)
FPN沿着自上而下的方向融合了不同层的特征,PANet发现自下而上的方向也可以提高性能。后来的Backbone,如NAS-FPN采用类似的双融合结构,以获得更好的性能。本文提出了一种SFM(合成融合模块),可以在原始层之间生成各种合成层,从而将预测图缩放到1/2、1/3、1/4、1/6等。它包含3个可选的输入,首先是线性缩放输入,然后逐像素add它们,然后与conv-3×3融合。该模块可以从原始层中合成合成层,也可以简单地用于融合特征。其体系结构如图3所示。
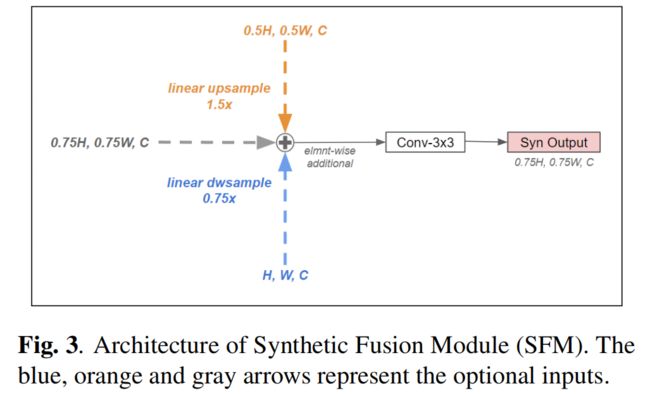
图3 合成融合模块
3.2 合成融合块(SFB)
SFB由多个SFMs构建。它将这些图层分成两批。首先,将特征从第一批层传递到第二批层,然后从第二批层传递到第一批层。该体系结构如图2中的黄色方块所示。简而言之,这个想法可以被视为集中合并特征,然后向外辐射特征。SFB集成了自顶向下和自顶向下的方向。多个SFB的叠加可以执行多个特征融合,以获得更好的性能。实验中的所有模型都由3个SFB叠加。
3.3 合成融合金字塔网络(SFPN)
将SFB堆叠3次的FPN称为合成融合金字塔网络(SFPN),将包含X个输出层的SFPN称为SFPN-X。
1、Build Baseline(SFPN-3)
为了验证合成层是否是一种有效的策略,使用SFBs构建了一个只有原始层的SFPN,称为SFPN-3。SFPN-3保持了与FPN相同的原始大小。它采用了双向特征融合,与其他包含合成层的SFPN完全相同。在实验中,使用SFPN-3作为Baseline。
图2-a SFPN基本结构,SFPN-3
2、 SFPN-5和SFPN-9
SFM可以生成合成层,因此在SFPN的前面添加几个SFM可以生成几个合成层,然后输入以下3个SFBs。扩展到5层称为SFPN-5,扩展到9层称为SFPN-9。这2个网络分别增加了3层和6个合成层,这是验证合成层有效性的主要模型。
图2-b SFPN基本结构,SFPN-5
图2-c SFPN基本结构,SFPN-9
3、带有合成输出层的SFPN
所提出的合成层使特征的尺度更加连续,在特征融合阶段转移更平滑。为了进一步探索该组件的能力,作者添加了SFPN-5和SFPN-9的合成输出层。这些网络被记录为SFPN-5-SOL和SFPN-9-SOL。
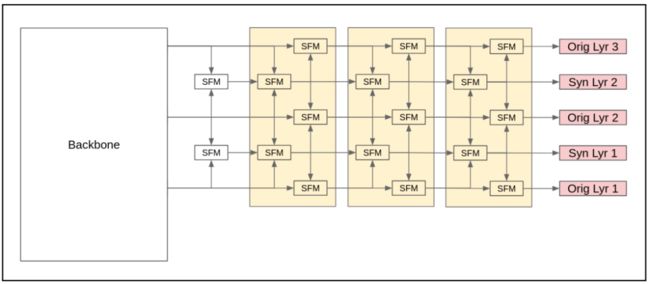
图6-a SFPN-5-SOL

图6-a SFPN-9-SOL
3.4 Naive Anchors for SOL
将SFPN连接到YOLO-Head。在YOLO架构中,Anchor的生成方法和分配策略对目标检测器的性能有显著的影响。YOLO使用k-means在训练集中找到k个先验框作为Anchor。CSL-YOLO发现,当输出层数增加时,k-means将产生许多不符合输出层比例的Anchor。作者采用了一种直接的Anchor生成方法来消除这一显著的干扰因素。作者使用比例为1×、2×和4×的优先级框作为输出特征映射的每个像素上的Anchor。该方法使3层、5层和9层的输出获得尺度拟合和一致的Anchor,证明了性能增益来自合成输出层。
4实验
4.1 SOTA对比
最终的实验结果如表1所示。如果视觉置信度图只提供直观的证据,那么MS-COCO上的性能就是直接证据。当Backbone为VGG-16时,无论输入的图像大小是224还是320,更多的合成层都可以得到更高的AP。另一方面,当Backbone是MobileNetV2时,AP的增加更为明显。可以说,SFPN的特征捕获能力在较弱的小模型上更为突出。
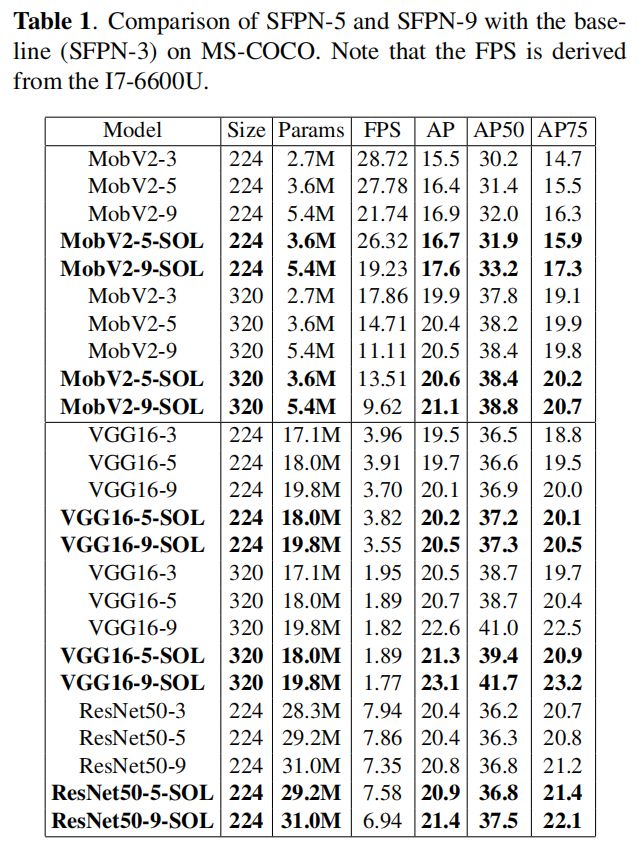
在融合的SFPN-5和SFPN-9上添加最后一个合成层作为输出层,并预测新的输出层的测试集。作者想用这个实验来评估连续尺度的合成输出层是如何显著提高性能的。实验结果如表1所示。虽然改良的SFPN-5-SOL和SFPN-9-SOL丢失了一些FPS,但是也更多地超过了Baseline,证实了合成层不仅在特征融合阶段,而且在输出阶段都发挥了重要作用。
4.2 可视化特征

图4 置信度图
增加更多的合成层可以使SFPN的输出层数从3层增加到5层,最后增加到9层。为了进一步探究这些合成层带来的级联效益,作者将SFPN-5输出的置信度图可视化,并将其绘制在上面的原始图像上,如图4所示。

图5
合成层的尺度介于原始层的上下2层之间,使得原始层能够更流畅地传递特征,从而减少特征的损失。另一方面,一些目标的大小比原始层更符合合成层的特征描述,这使得模型能够获得更合适的目标表示能力,如图5所示。总的来说,该方法使原始层减少了特征损失,同时考虑了更多不同大小的目标,新的合成层也能更适应不同的目标大小,预测出更合适的包围框。