ZUCC 正方教务系统 抢课脚本 抢课流程实现
ZUCC 正方教务系统 抢课脚本 抢课流程实现
新版ZUCC正方教务系统抢课脚本的流程分析与实现,文章结尾有完整项目的所有代码。
个人博客文章链接
流程分析
账号登录进入首页- 模拟请求进入计划内选课界面
- 模拟点击进入某个课程,爬取课程时间分布信息
- 模拟发送抢课数据包
初始化CATCH_PLANNED_COURSE.py这个文件
import LOGIN
from bs4 import BeautifulSoup
import time
class PlannedCourse:
def __init__(self, account):
self.account = account
def enter_planned_course(self):
return
def catch_course(self):
return
def choose_course_class(self):
return
def run(self):
# 进入计划内选课界面
self.enter_planned_course()
# 爬取课程信息
self.choose_course_class()
# 模拟发包抢课
self.catch_course()
这里的account对应了登录时的账号,登录时的会话一直保存在account中,在选课的部分会通过这个会话保持和正方教务系统的连接。
进入计划内选课界面
首先我们需要知道在正常网页下我们是如何进入计划内选课界面的。
一般情况下我们会点击计划内选课进入,但是这样我们是无法获取到真正的界面的。当我们ctrl+点击计划内选课的时候会新建一个标签页,在这个页面中才是计划内选课的真正网址
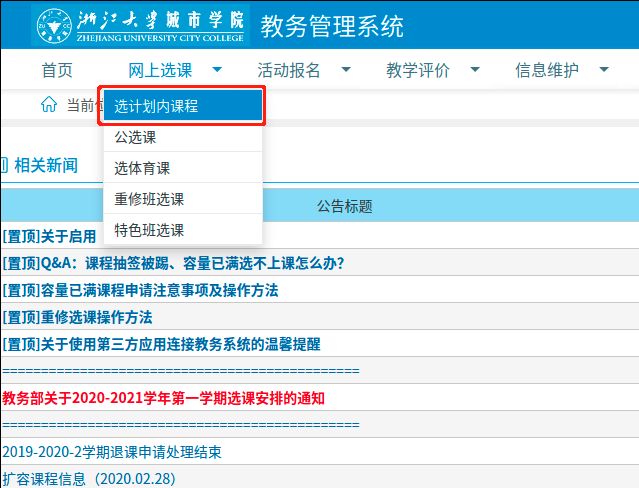
下图是直接点击进入的网站

下图是ctrl+点击进入的网站

所以我们登录成功后可以直接像这个网站发送GET请求,account对象的会话内容就会转移到这个页面。
这里可以通过BeautifulSoup解析一下,确保能出现课程种类就好。
def enter_planned_course(self):
url = LOGIN.ZUCC.PlanCourageURL + "?xh=" + self.account.account_data["username"]
header = LOGIN.ZUCC.InitHeader
header["Referer"] = url
response = self.account.session.get(url=url, headers=header)
"""以下两行代码可以用先解析以下,看下当前是否在我们需要的页面"""
self.account.soup = BeautifulSoup(response.text, "lxml")
#print(self.account.soup)
#return response
能输出以下内容就证明进入了计划内选课界面
课程选择
enter_planned_course.py会返回一个包含课程信息的response,这个response会以参数的形式出现在choose_course_class.py中,所以对应的地方都要更改
def choose_course_class(self,response):
return
def run(self):
# 进入计划内选课界面
response = self.enter_planned_course()
# 爬取课程信息
self.choose_course_class(response)
# 模拟发包抢课
self.catch_course()
首先我们需要选择我们要抢什么课,那我们就需要从刚才的网页中把所有的课程信息给获取出来。这个时候就要用到爬虫来帮我们获取这些网页标签。
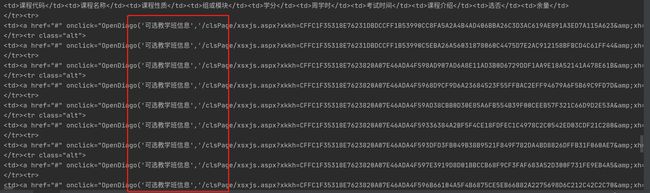
分析之前得到的response中的网页,可以得到每个课程种类信息是以下面这种结构在html文件中呈现出来的。(下面html样例中的超链接部分我删除了)
<tr>
<td>301258td>
<td>操作系统原理td>
<td>必修td>
<td> td>
<td>3.0td>
<td>3.0-0.0td>
<td> td>
<td>查看课程介绍td>
<td>已选td>
<td>1td>
tr>
我们也可以通过Chrome浏览器的F12开发者工具查看。左上角的小箭头点一下后再点击页面中你想要查找的部分就会自动跳转出对应的html部分。

知道它在标签中我们就可以解析这个html,输出所有的标签。
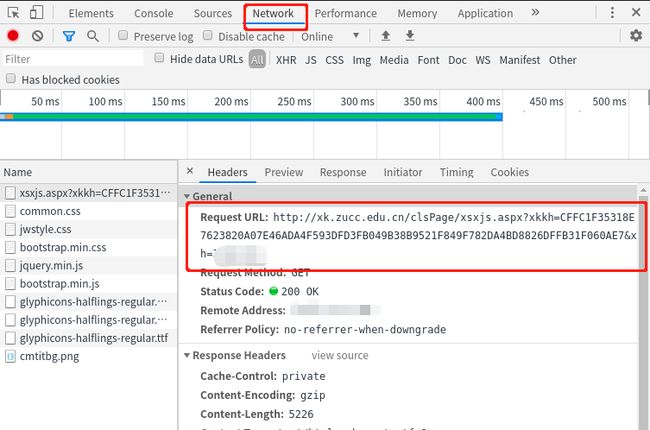
到这一步后还不够,我们还需要进入可选教学班信息部分才能选择课程选课。而这个界面无论是普通的点击还是ctrl+点击都不能出现它最原始的网页,这种时候就需要借助Chrome浏览器F12开发者工具中的Network来进行抓包
打开network界面后,点击课程可以看到发送了一些杂七杂八的东西,找到发送时间最长的那个,打开后可以看到这个http数据包的头部,里面有个Request URL,在这里我们可以看到数据包发送给了这个网址,而这个网址的组成就是/clsPage/xsxjs.aspx 加上点击课程的选课课号以及自己账户的学号。那我们就可以通过这个网址让account对象的会话直接模拟发送一样的Get请求,得到对应的页面。当然网址的组成需要修改。
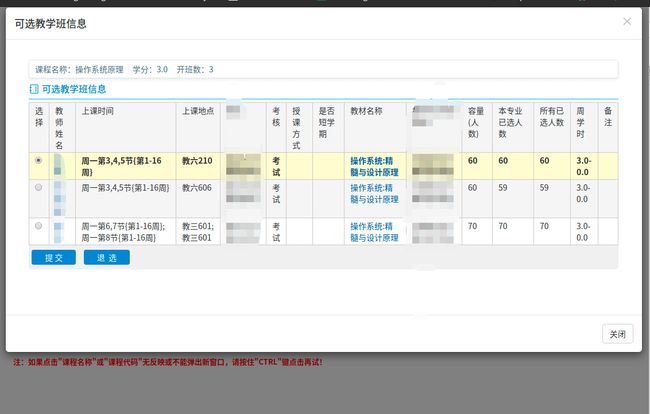
在这之前我们还需要给这一部分做点交互的界面,毕竟需要选择哪个课程种类
# init中加入了两个变量
def __init__(self, account):
self.account = account
# 最终选择的课程种类的url
self.obj_url = ""
# 所有课程种类的url
self.urls = []
# 所有开课信息
self.course_list=[]
# 发送选课数据包的时候要用到
self.obj_viewstate=""
def choose_course_class(self, response):
self.account.soup = BeautifulSoup(response.text, "lxml")
links = self.account.soup.find_all(name="tr")
for num, link in enumerate(links[1:-1]):
tds = link.find_all("td")
print("编号:" + str(num + 1) + "\t课程名称: " + tds[1].text)
url = "http://" + LOGIN.ZUCC.DOMAIN + "/clsPage/xsxjs.aspx?" + "xkkh=" + \
tds[1].find("a").get("onclick").split("=")[1][0:-3] + "&xh=" + self.account.account_data["username"]
# print(url)
self.urls.append(url)
# 在这里,所有的url都被存放在self.urls中,只需要判断输入的数值,读取相应的url,发送get请求就行了.
n = input("输入编号:")
url = self.urls[int(n) - 1]
self.obj_url = url
header = LOGIN.ZUCC.InitHeader
header["Referer"] = "http://xk.zucc.edu.cn/xs_main.aspx?xh=" + self.account.account_data['username']
item_response = self.account.session.get(url=url, headers=header)
#print(BeautifulSoup(item_response.text, 'lxml'))
return
创建一个新的类用来存放选择的课程的开课信息
class PlannedCourseInfo:
def __init__(self, num, code, teacher, time):
self.num = str(num)
self.code = str(code)
self.teacher = str(teacher)
self.time = str(time)
def show_course_info(self):
print("课程编号:" + self.num
+ "\t课程代码:" + self.code
+ "\t课程教师:" + self.teacher
+ "\t课程时间:" + self.time)
def __contains__(self, item):
if item in self:
return True
else:
return False
同时我们获得到的课程信息可以通过之前的方式,找到开课信息的元素,将这些元素的内容加入到课程list中
def choose_course_class(self, response):
self.account.soup = BeautifulSoup(response.text, "lxml")
links = self.account.soup.find_all(name="tr")
for num, link in enumerate(links[1:-1]):
tds = link.find_all("td")
print("编号:" + str(num + 1) + "\t课程名称: " + tds[1].text)
url = "http://" + LOGIN.ZUCC.DOMAIN + "/clsPage/xsxjs.aspx?" + "xkkh=" + \
tds[1].find("a").get("onclick").split("=")[1][0:-3] + "&xh=" + self.account.account_data["username"]
# print(url)
self.urls.append(url)
n = input("输入编号:")
url = self.urls[int(n) - 1]
self.obj_url = url
header = LOGIN.ZUCC.InitHeader
header["Referer"] = "http://xk.zucc.edu.cn/xs_main.aspx?xh=" + self.account.account_data['username']
item_response = self.account.session.get(url=url, headers=header)
#print(BeautifulSoup(item_response.text, 'lxml'))
item_soup = BeautifulSoup(item_response.text, "lxml")
self.obj_viewstate = item_soup.find_all(name='input', id="__VIEWSTATE")[0]["value"]
item_trs = item_soup.find_all(name="tr")
for num, item_tr in enumerate(item_trs[1:]):
try:
tds = item_tr.find_all("td")
code = tds[0].find('input').get('value')
teacher = tds[2].text
time = tds[3].text
lessen = PlannedCourseInfo(num + 1, code, teacher, time)
self.course_list.append(lessen)
except BaseException:
return
return
做到这里就已经可以获取到这门课的所有可选时间老师教室等等内容,这些内容都存放在PlannedCourse.course_list中。
接下来就是发送选课数据包了。
发送抢课数据包
在发送抢课数据包之前,还需要知道发送数据包的内容。这里要再次使用network的工具,模拟点击提交选课信息,抓取发送的数据包。
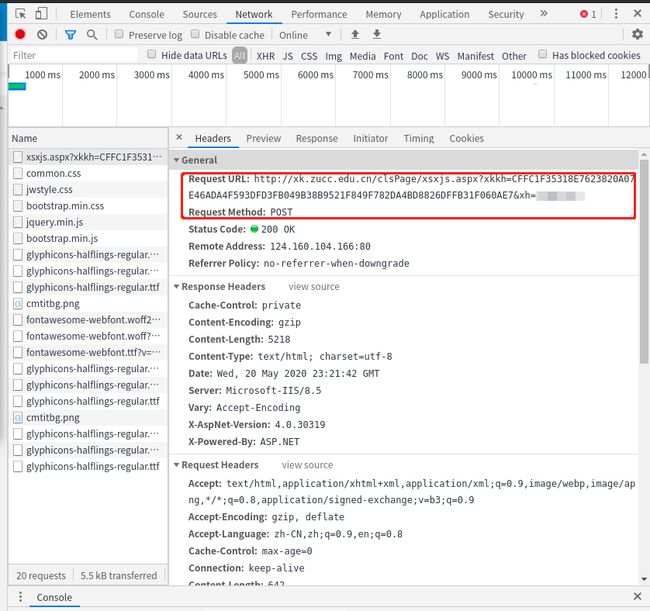
这里的数据包发送的是POST请求,直接向后台发送选课数据,能成功发送就可以正常抢课。

发送的数据包主要内容如下:
__EVENTTARGET: 这里指的是两个按钮,看你发送了哪一个,提交按钮是Button1
__VIEWSTATE: 这个是之前某个网页的随机码,这个码在上一部分已经提取过了,存放在了PlannedCourse.obj_viewstate变量中。
__VIEWSTATEGENERATOR: 不知道有啥用但是万年不变,就没必要爬取了,就直接写在数据包吧
xkkh: 字面意思选课课号,这个东西存放在PlannedCourse.course_list
最后加上一些交互的内容,将POST请求发送出去就行
def catch_course(self):
for info in self.course_list:
info.show_course_info()
n = input("输入编号(0退出):")
while True:
if n == "0":
return
elif int(n) < 0 or int(n) > len(self.course_list):
print("请输入正确的数字")
else:
break
post_data = {"__EVENTTARGET": "Button1",
"__VIEWSTATEGENERATOR": "55DF6E88",
"RadioButtonList1": "1",
"xkkh": self.course_list[int(n) - 1].code,
"__VIEWSTATE": self.obj_viewstate}
while True:
response = self.account.session.post(url=self.obj_url, data=post_data)
soup = BeautifulSoup(response.text, "lxml")
try:
reply = soup.find('script').string.split("'")[1]
except BaseException:
reply = "未知错误"
print(reply + "\t\t" + str(time.strftime('%m-%d-%H-%M-%S', time.localtime(time.time()))))
if reply == "选课成功!":
return
完整项目地址https://github.com/VinceMockghy/zucc_xk_ZhengFang