PostgreSQL BTree(B-Link-tree) 索引 基本 实现原理
文章目录
-
- 背景
-
- BTree
- B+Tree
- B-Link-Tree
- 基本数据结构的插入实现
-
- BTree Insert 实现
- B+Tree Insert 实现
- PostgreSQL BTree实现
-
- 整体结构
- BTree 索引创建实现
-
- _bt_buildadd
- _bt_uppershutdown
- BTree 查询 _bt_search 实现
- BTree 插入 _bt_doinsert 实现
-
- _bt_split 节点分裂
- _bt_insert_parent leftpage high-key插入父节点
- 分裂 page 过程的异常处理
- 总结
背景
BTree 以及 BTree的相关变种数据结构(B+Tree, B-Link-Tree…) 被推出来服务于构建内存索引来高效查找存储于磁盘的数据。
文中涉及到的 PostgreSQL 源代码版本是
REL_12_STABLE
索引是数据库存储部分的性能核心,了解一个基本数据结构的演进历史 以及其在生产级别数据库中实现时的取舍还是非常有趣的。
BTree
BTree 本质是自平衡的多叉树结构,其允许key+value 存储于内部节点,且有序,从而能够将对节点数据的增删改查的时间复杂度降低到O(logn),n 是B-Tree节点的个数。
BTree 的基本性质如下:
- 每一条从root 根节点 到 leaf 叶子 节点的路径高度都是完全相同的。
- root 节点要么是叶子节点(只有一个节点的情况),要么拥有两个子节点
- 对于BTree 的度(degree) t,有一些场景也叫做 order m:
- 除了root 根节点之外的节点至少包含 t - 1 个key 或者 upper ( m /2 ) - 1个key
- 除了 root 节点 以及 leaf 节点之外的内部节点 至少包含 t 个子节点,最多包含2*t个子节点,或者说 内部节点的子节点个数等于其当前包含的 key 个数 + 1
- 每一个节点内部最多存储 2t - 1 个keys
- 节点内部的key 是升序排列
- 大多数key+value数据都在 leaf 节点,也允许 内部节点保存key+value
在学习数据结构实现过程中发现 degree 这个东西youtube 以及 论文中的描述有差异,本质上其就是一个btree节点什么时候分裂/合并的一个配置项,自己配置完全可以。比如 有一些地方描述的degree t 为2,也就有如下的配置:
t = 2 或者 m = 4 都是一样的配置
- max children-nodes(一个节点最多能有多少个子节点) = 2 *t = m = 4
- min children-nodes(一个节点最少能有多少个子节点) = t = upper (m / 2) = 2
- max keys(一个节点内部最多有多少个keys) = 2 * t - 1 = m - 1 = 3
- min keys (一个节点内部最少有多少个keys)= t - 1 = upper(m / 2) - 1 = 1
其中 upper 是说向上取整。有一个细节就是 min children-nodes 以及 min-keys 在实际的degree数据量比较大的时候并不会说一定满足,比如degree 为5,则每一个min-keys 必须要求是4,否则就要进行合并;实际对于叶子节点并不会有 min 相关的性质约束,只会对内部节点有约束。
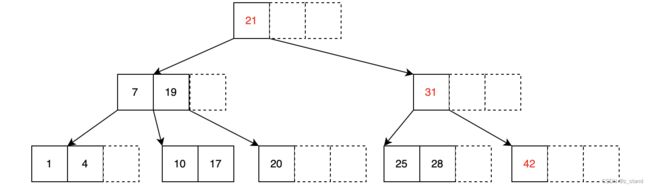
degree t = 2 的 BTree 形态如下:
B+Tree
BTree 对于使用B-Tree的数据库 以及 文件系统应用来说 有一个最大的问题 就是 数据会存储于内部节点。因为上世纪 70 - 90年代,
- 硬件层面 内存以及磁盘之间的性能差异越来越明显,内存本身距离CPU近且利用了高效的存储介质,CPU对其中的数据访问性能相比于距离更远且拥有更慢的存储介质的磁盘(当时主流应该是 hdd/ 以及较少的 sas/sata ssd) 拥有数个量级的差异。所以对于内存的使用应该更为细致 以及高效。
- 软件层面,无论是 xfs 等以btree为主的文件系统 以及 数据库内存+磁盘 这种应用的扫描需求较多,而BTree虽然是有序的,但是对于节点数据的遍历还是需要走中序遍历,会有较多节点的重复访问(需要有节点的回溯),其实并不高效。
在这两个大背景下, B+Tree 这个BTree的变种就应运而生,其在BTree 基础性质的基础上增加了两个性质:
- 所有的key + value 数据都保存在 leaf 叶子节点,root 以及 internal 中间节点仅保存key 用作索引。
- 所有的 leaf 节点之间都维护一个单向/双向指针,方便顺序遍历。
B+Tree 的第一个性质能够保证一个BTree索引的大多数的key 可以被存储在内存中,查找过程就不需要像BTree一样从磁盘读取中间节点的数据了,合理的配置下只需要极少的随机io操作就可以从磁盘读取到要查找的数据。比如 一个 BTree 的 t = 512,也就是一个节点内部最多存储 1023个key,这样的三层B+Tree 能够保存 10亿个key,如果只有root节点被存储到内存,查找一个key的数据也只需要两次随机IO 加载到key所在的叶子节点的pages,并在内存中二分查找即可;当然实际 root 节点 以及 第一层的key肯定都能被存储到内存中,这样的查询效率会更高。
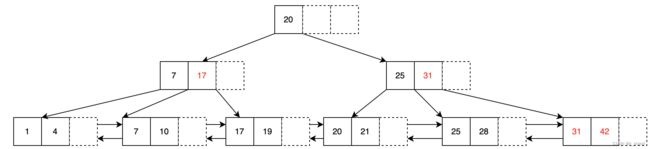
一个degree 为2 的B+Tree的形态如下:
B-Link-Tree
B-Link-Tree的设计来源于论文 1981 ACM论文 “Efficient Locking for Concurrent Operations on B-Trees”,即大名鼎鼎的 L & Y 论文。
纯粹的 B+Tree 数据结构 无法高效得解决并发操作B+Tree的问题,如下时序场景:

其中关键字的语义如下:
C <--- read(x)表示从磁盘page x 读取数据到内存块 C中,用变量x表示其内存数据- examin C;解析内存块C
- get child[1] to y,从解析的内存块中提取child[1]的磁盘page地址,并分配变量y表示这个child[1]指针指向的数据区域
- put (B, y’),将内存块B 中 y’变量的数据写入到磁盘
上图中 在 两个并发操作期间 B+Tree的行为如下:
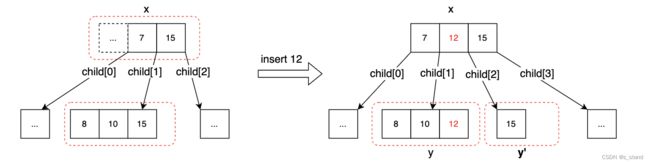
即在 search (15) 操作 和 Insert(12) 并发操作场景中,两种先后要准备读取y page的数据,在此期间 insert(12)先完成 并发生了节点分裂以及leveup,修改了 search操作要访问的磁盘page y 的数据(将15 分裂到了 磁盘page y’ ),导致 search(15)操作最后从磁盘读取的 y page没有找到y。
这个过程其实就是并发访问同一个B+Tree 数据结构的问题,B-Link-Tree的设计就是为了高效解决并发访问问题。
说到高效,肯定就有传统的解决方案。普通的方案就是 整个BTree加锁 或者 查询/修改路径的节点加锁,但是这两种的锁冲突概率都很高,尤其是在修改路径的每一个节点加锁,对于顶层节点来说更容易被访问到,其冲突概率极高;所以需要有一种更高效的解决方案,也就是 L&Y 论文中的优化。
B-Link-Tree 在B+Tree的基础上又增加了两个性质:
- 为每一个内部节点 新增了一个指向兄弟节点的右向指针。
- 为每一个内部节点引入一个额外的key (high-key),它是当前节点以及所有子节点中最大的key。
B-Link-Tree 的形态如下:

通过这两个性质的约束,实际的实现过程中可以保证 正确性的情况下只需要加少量的写锁 以及 读无锁;能够极大得提升 B+Tree 的并发访问性能。
PostgreSQL 的BTree 索引的实现就是采用 B-Link-Tree的 L&Y 方案,但也又一些特有的优化,后续会逐渐展开。
接下来我们先了解一下 数据结构层面的 插入流程实现到底是什么样的,中间主要涉及哪一些操作,方便后续理解 PG 在工业层面的 实现代码。
基本数据结构的插入实现
数据结构的实现主要是以图 + 伪代码为主,能够方便快速理解数据结构的核心。
本篇主要描述的是插入流程,插入过程主要的操作就是节点内部key的个数超过 2*t - 1之后 的分裂,相比于删除操作中合并相关的节点要注意的事项少一些,删除操作后续会再补充介绍。通过插入链路基本能够了解到 工业界在插入流程中的一些考虑,比如并发控制、Crash-recovery一致性、磁盘的读写等。
BTree Insert 实现
BTree的插入流程如下:
- 对于要插入的key,从根节点开始比较,沿着树的路径向下遍历到叶子节点。找到适合插入当前key的叶子节点,插入前需要判断当前节点是否已满:
- 如果该叶子节点未满,即内部key的个数< 2*t - 1个,则二分查找到合适的位置,插入当前key到该叶子节点。
- 如果叶子节点已满,key 个数达到 2*t - 1个,则进行节点分裂:
- 把该key 放到到当前节点之后分裂为两个节点,选择中间key levelup 放入到父节点,并将当前节点中一半的 keys (比如中间key 之后的所有keys)放入到新节点,并更新该新节点的福指针
- 如果父节点 因为子节点中有一个key levelup ,也满了则递归执行上一步的分裂过程,直到整个树的所有节点都满足 BTree的性质。
- 插入完成需要更新一些节点变量,比如节点现有key number等。
流程中的核心分裂操作有几个实现上的地方需要小心:
- 分裂的触发条件是在原有key的数量的基础上判断当前叶子节点是否满,是则先分裂;分裂点的选择在整个BTree的所有分裂场景都要统一,比如5个节点为满,则选择 lower(5/2) 或者 upper(5/2)构造出来的BTree是不一样的,但是两者都满足BTree的性质。
- 插入key 是优先找叶子节点。也就是说分裂都是由叶子节点处罚,可能引起其父亲节点的分裂。
- levelup key的选择是新分裂出来的节点的最大key添加到父亲节点
看如下示例:
对于插入序列 1, 4, 7, 10, 17, 21, 31, 25, 19, 20, 28, 42 ,我们想要构造一个degree为2 的btree,构造之前,该 btree中的一些节点变量的值如下:
- max childens = 4
- internal节点 min childens = 2
- max keys = 2*t - 1 = 3
- min keys = t-1 = 1
当插入 1,4,7都是按照顺序插入,到 插入 10时会触发分裂:
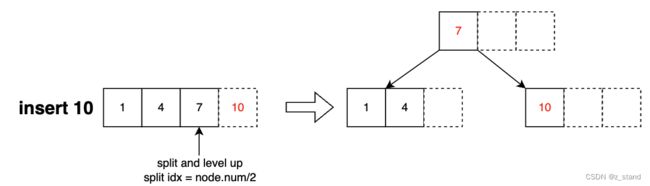
我们这里选择的分裂点是 upper((2*t - 1) / 2),即node.keys[2],包括第三个元素以及其之后的当前节点的key会被划入到新的节点。
这一步分裂逻辑实现可以看作如下几步:
- 确认分裂点为 upper((2*t - 1) / 2)
- 执行节点分裂为 node1 {1,4}, node2{7}。生成一个新的节点,将分裂点以及其之后的keys 插入到新的节点并从旧的节点删除。
- levelup 会选择新的节点的最大的 key 插入到父亲节点中(当然,如果父亲节点满,则重新走一遍分裂流程)
- 将要插入的元素10 和分裂后的node1的max-key做判断,大于node1.max-key,为了维持BTree的平衡,这里会选择将10插入到新的节点之中。
这一部分的伪代码实现可以写成如下逻辑:
void insert(Key key, Value value)
{
BTreeNode *node = findLeafNode(key); // 找到要插入的叶节点
if (!node->isFull()) // 如果该节点还有空间,则直接插入
node->insert(key, value);
else
{
BTreeNode *newChild = split(node); // 将原节点分裂成两个节点
leveupToParent(node, newChild.getMaxKey(), newChild); // levelup 并更新父节点
if (key > node->getMaxKey()) // 判断新键值应该插入哪个节点
newChild->insert(key, value);
else
node->insert(key, value);
}
}
后面会介绍 split 函数以及leveupToParent 函数的流程。
继续按照插入序列插入到BTree中,持续插入,直到插入31时会再次触发节点的分裂:

通过从root节点比较,确认31要插入的叶子节点已满需要分裂,先分裂,再 levelup 新的节点的key: 21,再插入31到新的节点中。
继续插入,到key 20的时候还会触发一次分裂:

找到20要插入的叶子节点,确认其已满,先分裂,将新节点的max-key levelup到父亲节点,在父亲节点上增加新的子节点;再将20插入到新的节点中。
持续插入直到最后一个元素 42,可以发现父亲节点也会需要split
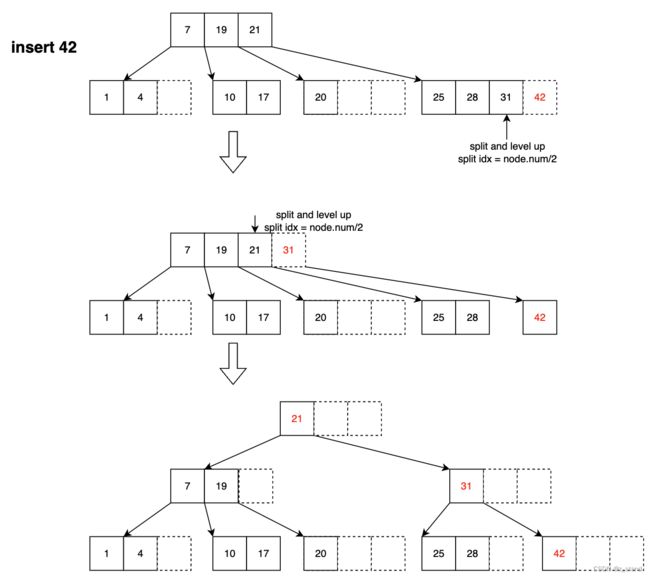
对于21 levelup到父节点之后的父节点相关的分裂以及插入只需要递归完成即可,最后整个BTree的形态就是上图中的结果。
接下来看看split 部分实现的伪代码,很简单:
- 确认分裂点
- 创建新的子节点并移动旧节点中从分裂点划出的元素到新的子节点
BTreeNode* split(BTreeNode *oldnode) // input origin node
{
int mid = (oldnode->getKeyNum() + 1) / 2; // 找到中间位置,选择向上取整
BTreeNode *newChild = createNode(); // 创建新节点
for (int i = mid;i < oldnode->getKeyNum(); i++) // 将一半键值对移动到新节点中
{
newChild->insert(oldnode->getKey(i), oldnode->getValue(i));
oldnode->delete(i)
}
return newChild
}
再看看 levelup到父节点的伪代码实现:
- 确认当前节点是否是root,如果是则需要创建新的root,设置当前节点为新 root 节点的子节点。
- 如果不是root,获取当前节点的父节点,判断是否满
- 如果未满,设置新的子节点和父节点的关联属性
- 否则继续分裂以及leveup操作 (递归)。
void leveupToParent(BTreeNode *node, Key key, BTreeNode *newChild)
{
BTreeNode *newRoot;
BTreeNode *parent;
BTreeNode *newParent;
int childIndex;
if (node->isRoot())
{
/* 1. 操作root节点 */
newRoot = createNode()
newRoot->setChild(1, node)
newRoot->setKey(1, key)
newRoot->setChild(2, newChild)
node->setParent(newRoot)
newChild->setParent(newRoot)
setRoot(newRoot)
}
else
{
/* 2. 操作非root节点 */
parent = node->getParent();
if (parent->isFull()
{
/* 2.1 父节点满,则递归分裂以及leveup */
newParent = split(parent);
leveupToParent(parent, newParent.getMaxKey(), newParent);
childIndex = parent->getChildIndex(node);
/* 完成后绑定父节点和子节点 */
if (key > parent->getMaxKey())
{
newParent->setChild(childIndex + 1, newChild);
newChild->setParent(newParent);
}
else
{
parent->setChild(childIndex + 1, newChild);
newChild->setParent(parent);
}
}
else
{
/* 2.2 父节点未满,绑定新的child节点和父节点 */
childIndex = parent.getChildIndex(node);
parent->insertKey(childIndex, key);
parent->insertChild(childIndex + 1, newChild);
newChild->setParent(parent);
}
}
}
到此,BTree 的基本插入逻辑就介绍清楚了,插入链路的关键点也比较简单:
- 优先插入叶子节点,分裂一定是从叶子节点先开始
- 确认分裂点之后,分裂的过程就是生成新节点以及移动分类的keys
- levelup 时需要对root节点额外操作
- levelup 操作非root节点时,如果父节点满,这个时候需要再走父节点的分裂以及leveup逻辑。
接下来看看B+Tree 的插入,整体实现和BTree基本差不多,但是B+Tree 新增的性质会让最后生成的Tree形态和BTree不同。
B+Tree Insert 实现
介绍流程之前先回顾一下 B+Tree 在 BTree基础上新增的性质:
- 所有的key + value 数据都保存在 leaf 叶子节点,root 以及 internal 中间节点仅保存key 用作索引。
- 所有的 leaf 节点之间都维护一个单向/双向指针,方便某一个节点的顺序遍历。
所有的key+value 都需要保存在叶子节点,也就意味着我们在叶子分裂时的levelup需要在叶子节点存储kv,仅把key 作为索引levelup到父节点;这个过程不是像BTree 允许内部节点保留key+value 一样可以整个kv都可以levelup到父节点。
新增的第二个性质在实现上也就是我们分裂完成之后需要对old 和 new 节点有 额外的指针增加操作。
先对比一下在上面degree 为 2 时 的同样插入序列,构建的 BTree 和 B+Tree 的差异:
插入序列为 1, 4, 7, 10, 17, 21, 31, 25, 19, 20, 28, 42
BTree
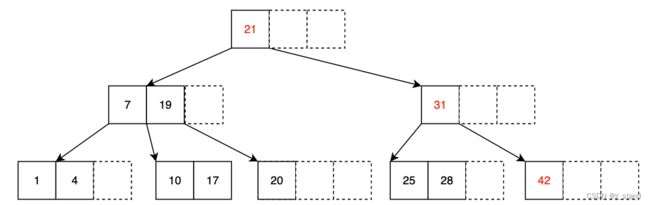
B+Tree
可以看到结果还是有很大的差异。
B+Tree的插入流程和BTree的流程基本一样,大家都需要维持一个多叉树的平衡;只是因为有上面第一个性质的存在而有差异。
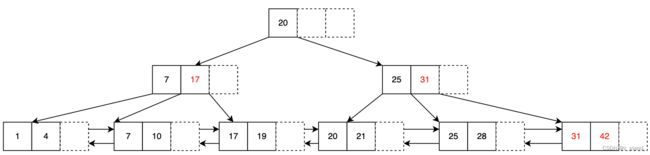
比如 在我们插入kv 为 10 的时候,分裂的差异如下:

对于levelup 的key 7来说,还需要在新的叶子节点继续保留。
比如插入 20 的时候,B+Tree 就一定需要对root节点进行分裂了

插入20之前,B+Tree是下面的形态

20 应该要插入的叶子节点是 node {17,19,21},因为已经满了,需要进行分裂 node {17,19}, node2 {21},分裂之后就需要把20 插入到node2中,并levelup 20这个key到 父节点;绑定node2和父节点parent。
发现父节点也已经满了,对parent进行分裂 parent{7,17,25} 分裂为, parent{7,17}, parent2{25},此时key 20 作为index, 且接下来要插入的是内部节点,同时需要被 levelup,所以不需要插入到 parent2,直接将其作为新的root节点,并绑定 root 节点和 parent 以及 parent2的关系。
看看B+Tree 的insert 伪代码,基本和 BTree一样。
void insert(Key key, Value value)
{
BTreeLeafNode *node = findLeafNode(key); // 找到要插入的叶节点
if (!node->isFull()) // 如果该节点还有空间,则直接插入
node->insert(key, value);
else
{
BTreeLeafNode *newChild = split(node, true /* leaf node*/); // 将原节点分裂成两个叶子节点
if (key > node->getMaxKey()) // 判断新键值应该插入哪个叶子节点
newChild->insert(key, value);
else
node->insert(key, value);
leveupToParent(node, newChild.getMaxKey(), newChild); // levelup 并更新父节点
}
}
只不过是对于叶子节点,该key 一定是需要被插入的。
BTreeNode* split(BTreeNode *oldnode, bool isLeaf) // input origin node and leaf mark
{
int mid = (oldnode->getKeyNum() + 1) / 2; // 找到中间位置,选择向上取整
BTreeNode *newChild = createNode(); // 创建新节点
for (int i = mid;i < oldnode->getKeyNum(); i++) // 将一半键值对移动到新节点中
{
if (isLeaf)
newChild->insert(oldnode->getKey(i), oldnode->getValue(i));
else
newChild->insert(oldnode->getKey(i)); // 对于非叶子节点,只需要插入key就好了
oldnode->delete(i)
}
if(isLeaf) // 构建叶子节点的链表,双向链表 or 单链表
{
if (oldNode->getNext())
{
oldNode->getNext()->setPrev(newChild);
newChild->setNext(oldNode->getNext());
}
oldNode->setNext(newChild);
newChild->setPrev(oldNode);
}
return newChild
}
上面的split 伪代码展现了差异:
- 需要区分两种不同的插入方式,对于非叶子节点只需要插入 key 作为索引就好了 (新增的第一个性质);
- 在完成叶子节点的分裂之后需要构建链表操作(新增的第二个性质)。
对于只传入key 作为参数 的 insert 实现,可以理解为和 BTree一模一样。
再看看 leveupToParent 的伪代码 基本一样,只是分裂的时候需要注意标注非叶子节点:
void leveupToParent(BTreeNode *node, Key key, BTreeNode *newChild)
{
BTreeNode *newRoot;
BTreeNode *parent;
BTreeNode *newParent;
int childIndex;
if (node->isRoot())
{
/* 1. 操作root节点 */
newRoot = createNode()
newRoot->setChild(1, node)
newRoot->setKey(1, key)
newRoot->setChild(2, newChild)
node->setParent(newRoot)
newChild->setParent(newRoot)
setRoot(newRoot)
}
else
{
/* 2. 操作非root节点 */
parent = node->getParent();
if (parent->isFull()
{
/* 2.1 父节点满,则递归分裂以及leveup */
newParent = split(parent, false /* not leaf node */);
leveupToParent(parent, newParent.getMaxKey(), newParent);
childIndex = parent->getChildIndex(node);
/* 完成后绑定父节点和子节点 */
if (key > parent->getMaxKey())
{
newParent->setChild(childIndex + 1, newChild);
newChild->setParent(newParent);
}
else
{
parent->setChild(childIndex + 1, newChild);
newChild->setParent(parent);
}
}
else
{
/* 2.2 父节点未满,绑定新的child节点和父节点 */
childIndex = parent.getChildIndex(node);
parent->insertKey(childIndex, key);
parent->insertChild(childIndex + 1, newChild);
newChild->setParent(parent);
}
}
}
通过上面的B+Tree的插入流程,我们能够直观的感受到 B+Tree 相比于 BTree 会有更多的分裂次数,因为没有办法在中间节点保留value,所以 叶子节点分裂 以及 levelup的时候还需要保留key才行。
不过中间节点毕竟是少数,增加的一些分裂操作相比于带来的收益 其实是微不足道的:内存保存更多的key 从而减少磁盘 IO 以及 高效的按照叶子节点链表顺序扫描的能力。
B-Link-Tree 的流程也差异不大,整体的插入部分只是在内部节点中多了 right 指针 以及 high-key,在 split 的时候增如果是 internal内部节点,增加右向指针 以及 随时更新 internal 节点内部的high-key 就好了。
PG 内部的BTree 实现采用的是 B-Link-Tree 这个变种,后续统一用 BTree来描述,接下来一起看看 BTree 在PG 中的基本实现。
PostgreSQL BTree实现
整体结构
在PG中整个 BTree 作为 Index ,其基本的形态如下:

- PG 中的 BTree 是一个略有变动的 B-Link-Tree,即内部节点增加了左向指针。
- 基本的BTree 索引持久化形态是和 Heap 表基本一样(除了唯一的Meta page),每一个节点保存到一个page,节点内的key 已经 子节点保存的value都会作为index tuple 保存到该 page中。
- Meta page 用来保存当前BTree 的元数据,也是索引page的第0页
- Inner Node 内部节点,其index-tuple 中 仅保存key 以及指向子节点的指针
- Leaf Node 叶子节点,是BTree 索引的最底层,其内部的 index-tuple 保存的是key 以及 指向 数据tuple的 tid。通过 tid 能够访问这个key 对应的实际数据。
- 每一个节点所在的page 内部最后有一部分 Special space空间,保存了当前节点或者说 index-page 的元数据,其是通过
BTPageOpaqueData表示。主要保存这个 page 左右方向指针、page所在 BTree 层级、以及当前页面的状态(叶子节点/内部节点/根节点/删除页面…)
PG中分裂的条件不是依据 每一个节点内部 key的个数,而是节点所在page的大小,比如page 没有插入下一个tuple 的空间了,则才会触发分裂。
PG 中 index-page 中需要注意的是对于 High-Key的保存,因为High-Key表示当前节点最大的key,不期望实时更新,否则 HighKey 所在的tuple 会被频繁得移动位置。所以会在创建Page的时候 在 line-pointer0 预留一个 High-Key的 tuple ,line-pointer1 是指向第一个索引元组。在当前page插入到第 N 个 tuple 导致当前 page满时,会清除 line-pointer N ,再 填充High-Key 并将pointer0 指向这个 High-Key 代表的最后一个tuple.
BTree 索引创建实现
创建索引 create index on table(column); 会走 DDL 得处理逻辑,和 建表类似,只是底层调用栈在 处理实际的 stmt 时 有差异,一个走的是 createTableStmt,另一个走的是 createIndexStmt。
创建索引的调研栈如下:
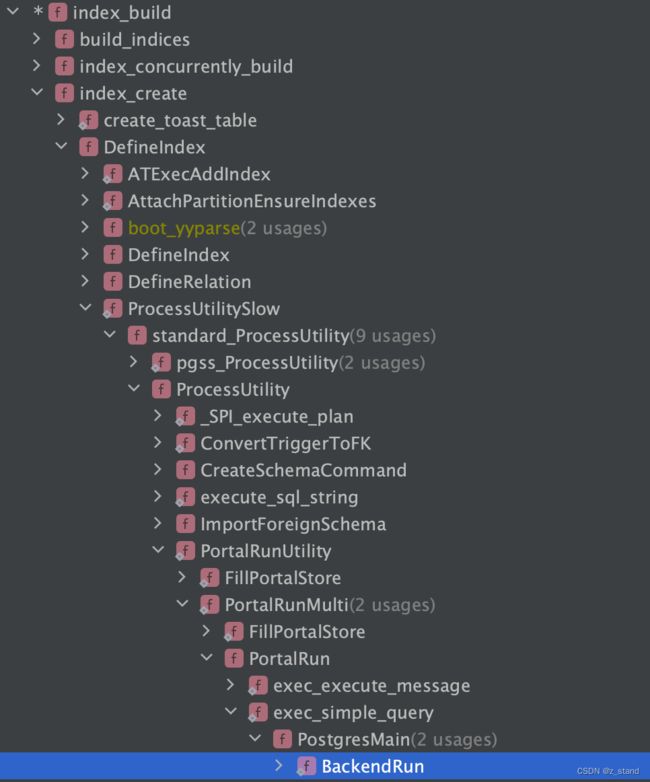
因为本节关注的主要是BTree 这个数据结构的实现,索引链路上的一些细节不会展开,主要也就是一些权限检查,类型检查 以及 各种异常情况的判断。 到 Index_build 时,会去确认用户执行的语句中执行的索引类型,并从 pg_am 系统表中确认该索引是否满足用户的需求(默认时 BTree),通过 btbuild 函数在已有数据的用户表对应的列上完成索引的创建。
介绍btbuild 实现之前,大家需要清楚 这个步骤是在已有数据的基础上构建btree 索引,因为btree索引是有序的,PG 这里在已有数据集的基础上构建 BTree 会先为所有的元组排序,然后再自底向上构建BTree,之所以这样做是因为 先排序 再 自底向上顺序插入 相比于 直接插入(找到合适的位置 O(logn) + 频繁的分裂),排序(O(logn))之后的插入不需要找到合适的位置 且 引入的分裂都是可控的 ,效率更高。
btbuild 的主要流程分为如下几步:
- 通过 table_index_build_scan 遍历数据tuple 并生成对应的 index-tuple,生成 index-tuple 期间 根据提前注册的 callback
_bt_build_callback将 index-tuple 分别添加到 spool 和 spool2(dead tuple)。 - 在
_bt_leafbuild中 通过tuplesort_performsort对 spool 以及 spool2 中的index-tuple分别进行排序 - 排序完成之后通过
_bt_load归并 spool 以及 spool2 并通过_bt_buildadd构建BTree。 - 通过
_bt_uppershutdown完成 BTree 结构的补全,比如 补充最右的Max节点,以及 生成 Meta page。
关于第二步的 tuplesort_performsort,其是PG 执行器的排序节点的核心算法实现(每次下层 seq-scan 输入一个tuple,通过排序节点进行排序),是工业级的排序算法(in-memory, out-memory, topk)的实现,后续介绍执行器的时候会统一介绍,本节不会过多展开。
dead-tuple 是在扫描数据元组时发现的不可见元组,比如该元组被delete 或者 snapshot-read时该元组不可见,这一些扫描出来的元组会被放在 spool2 单独存储。
构建的核心过程是在 _bt_buildadd 函数中,循环处理已经排序好的所有的index-tuples(每一个tuple表示一个BTree节点内部的key),顺序添加到 BTree 中,先添加叶子节点,满了之后叶子节点分裂且 index level-up 并添加父节点。
_bt_buildadd
这个函数的输入参数有三个:
BTWriteState保存一些配置(构建好的节点所在的page 是否需要写入到WAL) 以及 构建 BTree 过程中的一些统计信息(比如 写了多少 pages 数据、分配了多少pages等)BTPageState这是最重要的数据结构,构建过程中每一层都有一个,实时 标识 当前正在构建的 page 以及 保存了一个next指针可以访问到当前节点的父节点。typedef struct BTPageState { Page btps_page; /* workspace for page building */ BlockNumber btps_blkno; /* block # to write this page at */ IndexTuple btps_minkey; /* copy of minimum key (first item) on page */ OffsetNumber btps_lastoff; /* last item offset loaded */ uint32 btps_level; /* tree level (0 = leaf) */ Size btps_full; /* "full" if less than this much free space */ struct BTPageState *btps_next; /* link to parent level, if any */ } BTPageState;- IndexTuple 当前要插入到 BTree 中 的 index-tuple 数据
基本流程如下:
-
当前正在构建的 page 空闲空间 是否足够,是否允许插入新的 index-tuple。
pgspc = PageGetFreeSpace(npage); ... if (pgspc < itupsz + (isleaf ? MAXALIGN(sizeof(ItemPointerData)) : 0) || (pgspc < state->btps_full && last_off > P_FIRSTKEY)) { ... } -
page未满,则通过
_bt_sortaddtup将当前 index-tuple 插入到page的 last_off 位置 并更新 到BTPageState中 last_off。last_off = OffsetNumberNext(last_off); _bt_sortaddtup(npage, itupsz, itup, last_off);需要注意的是 _bt_sortaddtup 这个函数 特殊处理 非叶子节点的第一个位置的key,会去除该位置保存的key 信息,仅保存指向子节点的指针。
-
page 节点满,则创建一个新的page npage, 旧的page 为opage。
-
将 opage 中的最后一个 tuple 插入到 npage 中的
P_FIRSTKEY第一个有效key的位置,输入的要插入的index-tuple 后续才会插入。

-
将前面插入到npage的 opage最后一个tuple 作为
P_HIKEY插入到 opage中

-
如果是叶子节点,会对 opage 的 high-key tuple 尝试进行
_bt_truncate,优化page的空间利用率。 -
如果没有父节点,则创建一个 父节点 page, 和opage 建立连接;并将
BTPageState中保存的 上一个page 的 min_key 插入到新的父page中 ,递归调用_bt_buildadd完成;完成之后将 opage的最后一个tuple otuple 作为新的min_key。
每一个叶子节点的 min_key 可以理解为分裂节点的中间tuple,只是插入的时候全链路有序,我们只需要保存上一个page最大的key 作为min_key,下一个page满了之后该 min_key就可以当作分裂key 提升到父亲节点了。 -
设置 opage 和 npage 的左右指针。
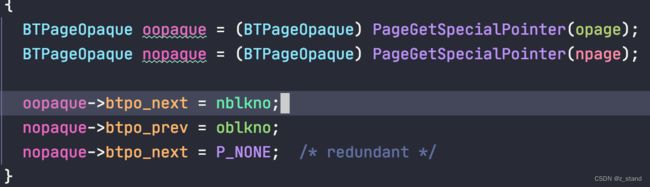
-
将 opage 写入磁盘,并且可以释放opage 占用的buffer 内存空间。
-
-
将当前要插入的 index-tuple插入到 npage,并将npage 设置为
BTPageState正在操作的page,同时更新其 blkno以及 lastoff 字段。
通过这个算法,我们大概能够画出PG 在index-build的过程中 BTree相关节点的构建过程如下:
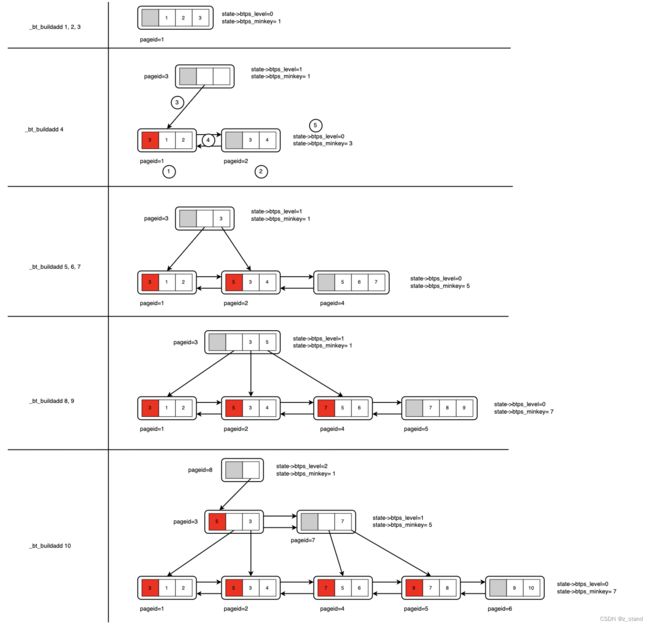
我们以 _bt_buildadd 4 为例,此时已经构建好的情况就是 BTree中已有 pageid 为1 存储的1,2,3;需要注意的是pageid=0 是为meta预留的页面,所以我们构建叶子节点使用的page是从 1开始的。
当要插入index-tuple 为 4时,_bt_buildadd 执行链路如下:
BTPageStat管理的当前page 已满,创建一个新的page, pageid=2,将pageid=1中的最后一个tuple 即3 插入到pageid=3 的page中。- 设置 opage中的high-key 为 opage的最后一个tuple,并将该tuple从opage中踢除
- 因为没有父亲节点,则创建父节点 为其分配pageid=3,设置当前 state->btps_next指向父节点。
- 将level0 state中保存的min_key (此时还是1)对应的tuple 递归调用
_bt_buildadd插入到父节点的page,因插入minkey 的pageid=3,已经不是子节点,在_bt_sortaddtup函数中会丢掉minkey tuple中的key值,仅保留指向子pageid=1的指针。 - 插入父节点完成之后设置当前state的minkey tuple为 otup 即 3,并继续 设置pageid=1和pageid=2的左右指针
依此继续执行,最后在完成 _bt_buildadd 10 得到的当前 BTree 的形态就是上图中最后的树形结构。
可以看到还并不完整,PG实现的最右节点没有High-key。
- 每层的最右节点还没有构建完成,比如最右边的 pageid=6 的还没有父节点指针
- 还需要补充 Meta 页面
_bt_uppershutdown
这个函数主要用来完善 BTree的结构,补充最右节点以及meta page。
基本算法如下:
- 拿着
_bt_buildadd返回的BTPageState结构,自底向上,逐层遍历BTree 所有节点。- 当前节点不是根节点,将当前节点的minkey 调用
_bt_buildadd插入到父节点中。 - 当前节点是根节点,设置根节点标识
- 对于最右节点,通过
_bt_slideleft左移一位(不需要High-key,不需要为High-key预留的 line-pointer0 的位置了)。 - 对当前页面的操作处理完成之后通过
_bt_blwritepage将page落盘。
- 当前节点不是根节点,将当前节点的minkey 调用
- 完成所有的节点操作之后 将meta-page落盘
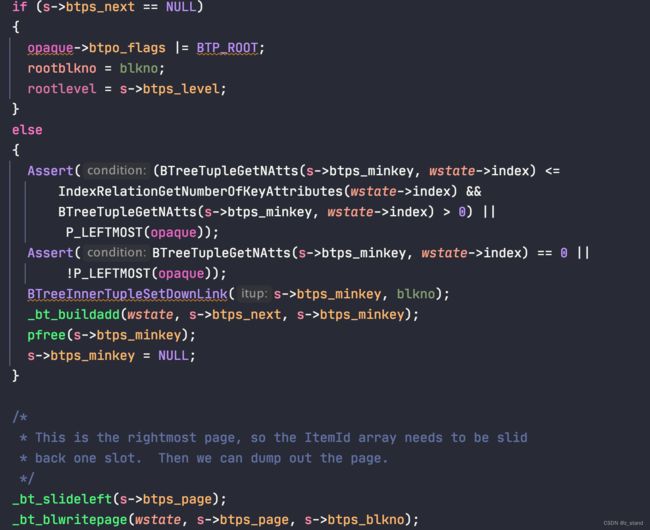
这个代码是循环内部的处理逻辑,meta-page落盘的代码在循环之外。
看看uppershutdown 对前面 _bt_buildadd 构建完成的 BTree 做了哪一些修改:
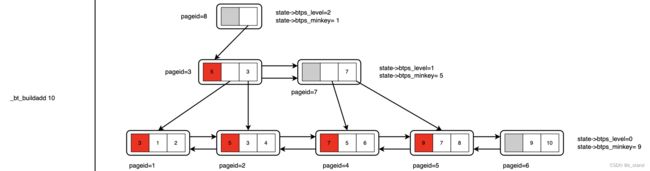
_bt_uppershutdown 补全之后:
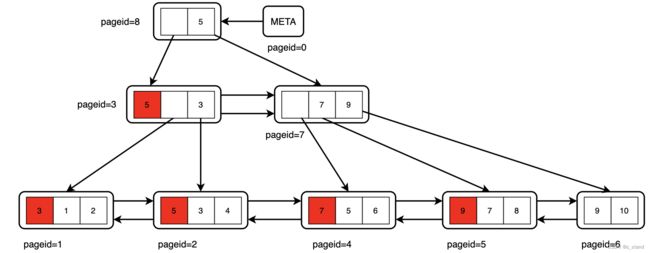
- 通过
_bt_buildadd完成当前层左右节点的 所有 minkey的插入,并进行左移(踢除最右节点的high-key占位),循环该操作直到根节点。可以看到最右节点已经没有high-key的pos位置了。 - 完成所有叶子、内部以及根节点的操作之后构建 meta 节点。
看到我们构建好的 BTree,会发现 拥有 High-key 的节点和实际 High-key的tuple所在的节点并不同,这没有什么影响, 只是说读的时候查询路径是 key >= high-key 时拿右兄弟指针继续查就好了(按照构建过程的算法,high-key 实际的指针 必然保存在当前节点的兄弟节点)。
BTree 查询 _bt_search 实现
在PG 这,从BTree 中查询指定key 比较常见,比如 _bt_doinsert, btgettuple 。
插入链路也会有查找的需求,且其实现和基本的B-Link-Tree 的查找链路基本接近。先看一下 查找的实现 _bt_search,这个函数会返回一条查找路径 以及 从参数ouput 查找key 所在的leaf-page,从根节点 page 到查找key 所在的第一个叶子节点的page。
-
获取根节点,并设置当前查找页面为根节点所在的页面。获取root-page的过程主要是通过读取 meta-page 来完成的。
-
通过
_bt_moveright检测当前操作的页面是否 有并发insert 导致 page-split 的情况。如果发现查找 的key 大于页面的high-key,则通过页面的右指针移动到其兄弟节点。这里需要注意,B-Link-Tree 的实现是为了解决我们最开始介绍 传统BTree 并发操作场景下的数据页面不一致的问题。借用 L&Y 论文中的思路,就是为内部节点引入 right 指针,当我们在当前页面查找的key 已经 不小于了这个页面最大的 high-key的时候,意味着这个页面发生了分裂(确定这个查找页面的时候是由上层节点确定的,但实际查找的时候 key 已经大于这个节点的最大key了),因为节点分裂查找键一定会被分裂到相邻的子节点,所以我们在当前节点右移一个节点即可找到分裂后的 key了。
但是PG 在实现这个逻辑的时候有一些差异,原因是PG 中管理page 是通过shared-buffer管理的,每一个 page 作为一个节点是被整个PG共享的。L & Y 论文中的假设是 每一个节点是独立的,且对节点的操作是原子的,这样在PG 中就需要额外得实现 原子语义。_bt_moveright的主要实现如下(循环处理下面的逻辑):
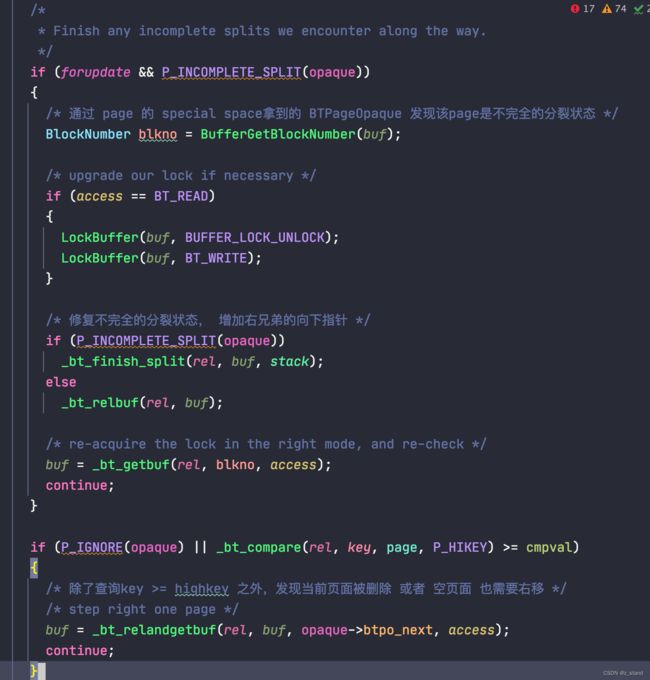
这里面有几个很有意思的地方:- 在实际执行move-right 获取下一个兄弟节点的page之前,可能会发现当前操作的页面状态为
BTP_INCOMPLETE_SPLIT。前面介绍PG BTree 整体数据结构时 提到过这个数据结构,这个状态是在每一个page-special 空间的BTPageOpaque数据结构保存,可以理解为其是page的元数据,除了标识 page 为 meta, root, inner,leaf 之外还有一些其他状态。BTP_INCOMPLETE_SPLIT表示当前节点的右兄弟节点没有 down-link 指向孩子节点的指针,这个状态可能是由于BTree分裂到一半 数据库节点宕机 且 WAL写入的日志不完整就可能进入这个状态。这个情况需要先修复右兄弟节点的异常,才能继续后续右移的操作。 - 在修复
BTP_INCOMPLETE_SPLIT之前入过当前是_bt_moveright是服务于读请求,需要进行锁升级,将对page访问本来加的读锁升级为有冲突的写锁。这样才能保证后续修复该page 状态时对该page的其他读以及修改都会是互斥的状态,从而保证访问的正确性。保护 page 的锁是 LWLock(PG 专门用于保护共享内存/内存中的数据结构的锁),虽然在冲突场景有等待关系,但是在 BTree page 的修改链路上加完锁,并在实际右移之前释放写锁并申请读锁,而读锁不会产生等待关系(不阻塞),所以并不会有死锁的情况。
- 在实际执行move-right 获取下一个兄弟节点的page之前,可能会发现当前操作的页面状态为
-
拿到右移之后的page,如果该page是叶子节点,则终止查找,并返回查找路径
BTStack。 -
通过
_bt_binsrch在拿到的 page(一定是一个内部节点)节点内部进行二分查找,获取对应的index-tuple 并提取其子节点指针。 -
添加子节点所在的page信息到 new_stack中,
-
通过
_bt_relandgetbuf释放父节点的读锁,在子节点上增加读锁。PG中仅仅只会为查询路径中的最后一个节点加读锁,即使有锁升级,这也只是查询路径中的一个节点,后续的_bt_moveright内部并不会发生死锁。 -
将新的 stack节点为尾插入到 起始时构建的保存路径的节点栈(单向链表)中,继续重复步骤2。
整体的查找算法除了有锁的参与保证 对 buf-page 的原子访问之外其他的操作和 L & Y 论文中提到的查找算法基本一样(伪算法实现如下):
BTreeNode *ScanNode(BTreeNode *node, Key key)
{
BTreeNode *t = NULL;
if (key >= node->highKey())
t = node->next(); // 右移指针
else
t = GetChild(node, key);
return t;
}
BTreeNode *Search(Key key)
{
BTreeNode *curr = GetRoot();
BTreeNode *t = NULL;
while (curr->level != LEAF)
// 向下或者向右移动
curr = ScanNode(curr, key);
// 到达叶子节点,继续向右移动,移动不成功则说明没有发生分裂的情况
while (t = ScanNode(curr, key) && t = curr->next())
curr = t;
return Get(curr, key);
}
ScanNode 的右移操作能够避免读的时候有其他人修改导致最后读的状态不一致问题,和前面介绍PG search 算法的时候提到的一样。当我们读一个Node时,这个Node可能在被并发修改(比如 insert 触发的split),但是 B-Tree split 的算法已经约束了split的节点其内部的 split-keys 只能被存储到相邻的兄弟节点,也就是当我们 search时对于路径上的每一个节点,先判断当前节点的 high-key 是否小于 search-key,如果是 则认为节点发生过分裂,我们移动到其右兄弟节点继续search即可。
BTree 插入 _bt_doinsert 实现
接下来看看 PG 中 insert 的实现,核心实现在 _bt_doinsert 函数中,基本流程如下:
- 通过
_bt_mkscankey构建我们的 search-key,主要就是从 输入的tuple中提取我们要插入到BTree 索引的对应列,并构建出 index-tuple 需要的数据结构。 - 调用
_bt_search查询 search-key 拿到查询路径 以及 该 key 所在的叶子节点 page。bt_search内部在完成查询路径的构建之后回对 write 链路(access == BT_WRITE )再尝试进行一次右移,防止再次遇到其他并发操作 造成的split问题。 - 唯一索引检查(本节不太会关注唯一索引的处理),这部分就跳过
- 通过
_bt_findinsertloc在当前找到的页面内找一个合适插入insert-key 的位置,要插入的页面 以及 偏移位置。 - 通过
_bt_insertonpg执行插入逻辑:- 如果page还有空闲空间,直接执行插入 page 操作,并写WAL
- 如果 page 满,则通过
_bt_split实现节点的分裂。 - 完成分裂之后通过
_bt_insert_parent将 旧page 的 high-key 插入到 父节点。
接下来看看我们心心念念的 PG 实现的 BTree 分裂 以及 levelup 的逻辑
_bt_split 节点分裂
回顾一下B-Link-Tree的节点分裂流程:
- 找到分裂点,并创建新的分裂节点
- 将原分裂点右边的keys 移动到新的节点,并分别重置旧节点以及新节点的high-key
- 左右节点维护双向链表的指针
- 将旧节点 的 high-key level-up,插入到父节点中,父节点满,则递归调用insert流程。
在PG的实现中大体流程比较接近,但是因为要兼容的生产环境的情况更多样一些,所以实现逻辑会更为复杂一些,大体流程如下:
- 通过
_bt_findsplitloc找到 origin page 分裂的 offset.- 如果非最右节点分裂,会尽可能选择keys 的中间位置,保持分裂之后两个节点的剩余空间基本相等。
- 如果是最右节点分裂,则先将左节点填满…
- 创建临时 leftpage 作为保存数据的临时左节点(这里之所以有左节点,是与分裂操作的原子性相关,后续的 recovery部分会详细介绍) 以及 lopaque page元数据,并添加新的high-key到leftpage。
- 创建 rightpage 作为右节点,并设置 rightpage 的hight-key。
- 遍历opage,通过
_bt_pgaddtup函数 将其中的keys 分别添加到leftpage 和 rightpage;插入过程将根据 前面找分裂点时通过参数输出 新的用户要插入的tuple 应插入的位置来判断插入左节点还是右节点(都有可能)。 - 通过
PageRestoreTempPage将leftpage拷贝到 opage中,并将rightpage 以及修改后的 opage 写入到WAL中。 - 返回分裂后的 rightpage
_bt_insert_parent leftpage high-key插入父节点
因为 _bt_split 会返回分裂后的右节点 以及 作为参数完成重新填充的左节点,对于 levelup 构造父节点指针来说只需要将左节点的 high-key 作为新的tuple 插入到父节点即可。
所以 _bt_insert_parent 的主要输入参数 包含 buf 左节点, rbuf 右节点 以及 stack (_bt_search 返回的查找路径,能够方便得找到待插入节点的父节点)。
整体流程如下(整体比较简单):
- 通过输入的 stack 找到 search-key的 父节点所在 page
- 将 leftpage 左节点的 High-key 找到,作为index-tuple 通过递归调用
_bt_insertonpg函数插入到父节点 - 如果 当前分裂 以及 插入父节点的页面是根节点, 则在 插入父节点时通过
_bt_newroot创建新的 root节点并更新 meta 节点。
PG 实现的BTree 的基本插入流程和 B-Link-Tree一样,没有太大的差异。
根据前面 build 完成的BTree,我们在此基础上继续尝试 insert 1:
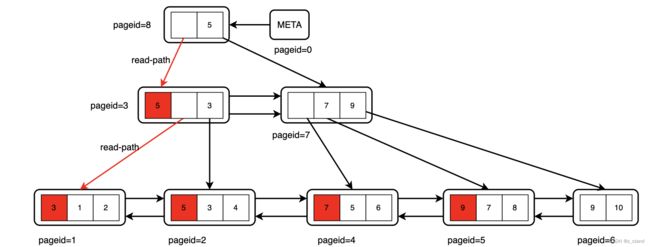
- 构建scan-key (1)
- 通过
_bt_search按照上图路径查找到要插入 叶子节点page1,并返回[page8] <-- [page3] <-- [page1] 这样的一个search stack。当然,search 的 中间过程每一层都会尝试_bt_moveright以及为当前page加读锁就能防止 其他并发insert导致的页面split问题。
接下来将走后续的 insert流程,最终的一个结果如下,中间涉及到的节点修改都已经完成标注:
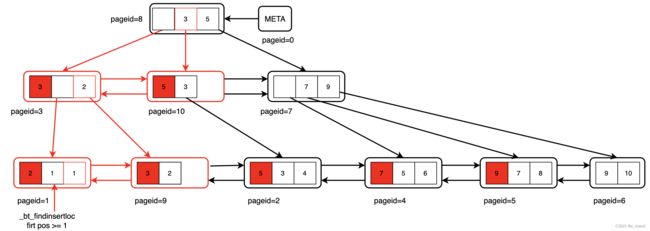
-
先通过
_bt_findinsertloc找到 page1要 插入1的位置,因为是非最右节点,high-key也需要占用position,所以找到第一个 >=1 的offset 位置作为插入点。 -
通过
_bt_insertonpg进行实际的插入操作,因为page1 已经没有freespace 再接受新的插入,所以需要对 page1 先 进行分裂。将原本key 为 1的offset 作为分裂点(非最右节点,尽可能保持分裂后两个节点的空余时间相同),分别创建 left and right page,将page1 的旧数据以 1 为分裂点分别移动到leftpage 和 rightpage,移动完成之后分别设置对应的high-key。leftpage 会设置 righ-page的 第一个key 作为自己的high-key,即2;right-page 会继续使用page1的high-key 3; 然后将leftpage 数据memcpy 拷贝到 page1,并建立 page1和rightpage 的左右link。 -
将 page9 的high-key 作为 要 levelup 的item 通过
_bt_insert_parent插入到父节点 page3,因为page3 也是满状态,则递归调用_bt_insertonpg完成插入。
分裂 page 过程的异常处理
因为 分裂的过程是需要修改 BTree 索引的 index-page的,而且整个分裂的过程会涉及多个节点的修改,如果只完成修改了部分的page,比如将上图 page1 完成分裂 生成page10,这个时候如果数据库宕机,page10 已经保存了数据,但是没有父节点的指针指向,PG 将如何处理这种情况?
思考几种异常情况:
-
当前 index 的插入中间遇到了 IO 异常 或者 其他的异常导致 事务终止,走abort 当前index 插入事务的终止流程,这个时候 index 插入过程中修改的page 该如何处理?
这个问题比较简单,index 的插入过程中生成的page 会被 shared-buffer(共享内存)管理,事务开启的时候会创建一个 InprogressBuf 来记录当前事务内部生成的数据page,如果事务abort(比如 ereport error,通过siglongjmp 跳到abort事务的处理逻辑),则会在 AbortTransaction 中将该事务内部的 InprogressBuf 记录的 page 标记ERROR状态,从而避免后续的checkpointer 进程将这一些page刷盘。当然,对于temp-table 这种backend 可见的临时表,用的是localbuffer,不过走的同样的abort逻辑。 -
当前backend 异常退出(kill),或者 数据库宕机,这一些中间状态的 page 该如何处理?
这个问题的通用解决办法是通过 WAL 维护的一系列中间状态的标记,每生成一个page且该page被持久化到WAL时会设置这个page特有的状态。比如我们 split的时候 分裂的左右两个节点会分别设置对应的WAL page状态:

后续即使没有完成 page 的刷盘,也能通过 WAL redobtree_xlog_split来直接恢复到当前节点的分裂状态,不需要对当前节点重新继续走一遍split的逻辑。对于前面说到的 没有完成构建 rightpage 父节点的向下指针,则是通过 每一个 index-page 的special-space 中
BTPageOpaque数据结构维护的 page状态BTP_INCOMPLETE_SPLIT来解决。当前 page 如果是这个状态,则认为这个page的右兄弟节点没有向下的指针,这样后续的_bt_search会通过_bt_clear_incomplete_split来添加右兄弟节点的向下指针。这个BTP_INCOMPLETE_SPLITpage 状态的标记是在 split 过程中 分裂出左节点时增加的标记:
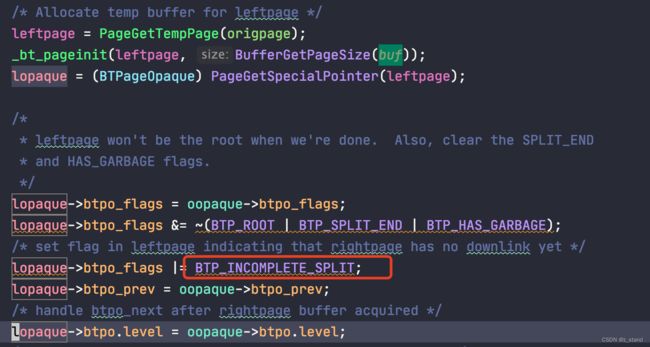
split 完成后 leftpage 会作为 参数被传递出去,再通过_bt_insert_parent过程中递归调用_bt_insertonpg插入到父亲节点,这个标记会持续到父节点完成和右子节点的指针连接之后才会清除。

中间过程数据库发生任何的异常,在下次进行_bt_insert或者_bt_search的时候,检测到这个状态 都会补全这个状态。
总结
本篇 从基本的 BTree 以及其相关变种 B+Tree, B-Link-Tree 算法基本实现看到了 这个数据结构在满足工业界的应用时 的演进思路 到 工业界 PG 在B-Link-Tree 上的基本结构的实现。
BTree 为了更强的扫描性能 有了 B+Tree,为了更好得支持并发操作,有了B-Link-Tree;这一些实现在实际的生产环境还是不够,比如 PG 以及 MySQL 包括 sqlite 这种数据库对 数据的写入都是维护了类似 buffer-pool 这样的结构,数据以 page粒度先写入到 buffer-pool中,再集中刷盘(对 IO 更为友好),所以 工业界实现 BTree时还需要考虑 buffer-pool 中page 的并发操作问题,也就需要有并发控制,比如锁,来保证对每一个BTree page 操作的原子性;同时还需要考虑一致性问题,也就是整个BTree 结构正常 操作期间会有很多page 的中间状态,那么如何保证这一些中间状态(page要落盘,新的page 有一部分落盘但是另一部分没有落盘) 在发生异常场景时还能保证数据访问的正确性,这就是工业界要实现这个数据结构时引入的复杂度。
当然本节并没有介绍 细节更多的 delete 操作 以及 主键唯一索引这个基本特性在BTree 中构建细节,因为 delete 涉及节点的合并,后续会再结合 PG 的 vacuum 细节来详细介绍这个过程。