VALSE 2023 无锡线下参会个人总结 6月12日-3
VALSE2023 无锡线下参会个人总结 6月12日-3
- 6月12日会议日程安排
- Workshop:多模态大模型与提示学习
-
- 左旺孟:预训练模型和语言增强的零样本视觉学习
- 余宙:知识增强的多模态预训练和提示学习
- 王云鹤:多模态交织:高效模型架构和融合方法
- 邵婧:基于LLM的多模态提示学习:框架、提示数据及评测标准
- 朱霖潮:模态鸿沟与交互式提示学习
- Panel 环节
- Workshop:优秀学生论坛
-
- 张博航:Rethinking the Expressive Power of GNNs via Graph Biconnectivity
- 许牧天:基于遮蔽建模的三维室内场景自监督预训练方法及大规模多视角图片数据集
- 陈涵晟:基于单阶段扩散NeRF的3D生成与重建
- 杨啸:Towards Effective Adversarial Textured 3D Meshes on Physical Face Recognition
- 董伯文:Self-Promoted Supervision for Few-Shot Transformer
- 杨木李:Towards Distribution-Agnostic Novel Class Discovery
- 黄振宇:Noisy Correspondence: A New Paradigm for Learning with Noisy Label
- 方浩树:人类级别的通用机器人抓取
- 张曦予:3D Registration with Maximal Cliques
写在前面
今年 VALSE 2023 的举办地刚好在博主目前就读学校的所在地,江苏无锡,欢迎各方学者前来参会。先预告下,今年的确是大模型、多模态的主场了,ChatGPTA、AGI 等等百花齐放。
会议持续 3 天(6月10-12日),7个特邀报告,12 个APR报告,20 场 Workshop,186 篇左右的顶会顶刊 Poster。报告对比去年更多了,论文少了 10 几篇。
第二天开始就是 Workshop 了,都是同时开展的,所以就是各大会场分开跑,这里的顺序按照我参加的 workshop 来排列。
没想到第三天上来就是个大惊喜:多模态大模型与提示学习,开始看就挪不动脚了。确实精彩,而且有意外的惊喜
下午的优秀学生论坛倒是比去年差一些了,但是老师们很强。
每篇博文的内容太多消化不了,请移步以下链接分别浏览:
- VALSE 2023 无锡线下参会个人总结 6月10日-1
- VALSE 2023无锡线下参会个人总结 6月11日-2
- VALSE 2023 无锡线下参会个人总结 6月12日-3
另外,VALSE 官方的微信文章也出来了:VALSE 2023 在无锡成功召开,5500 余人共舞学术华尔兹。
PS:2023 年每周一篇博文阅读笔记,主页更多干货,欢迎关注。有问题私信或者留言都可,笔者看到后第一时间回复,期待 5 千粉丝有你呦 ~
6月12日会议日程安排
Workshop:多模态大模型与提示学习

左旺孟:预训练模型和语言增强的零样本视觉学习
今天早上看到一篇知乎文章解读:【Valse 2023】预训练模型和语言增强的零样本视觉学习——左旺孟老师











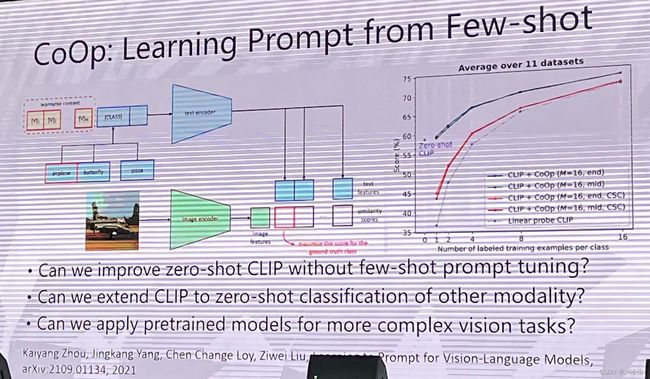

余宙:知识增强的多模态预训练和提示学习

余宙老师真的是给了我个很大的惊喜,往下看~




喏,就是这,MCAN,我的研究入门的文章团队作者之一,顺便知道了一作的情况。往下看!


这里余老师太谦虚了,说自己的 ROSITA 系列工作刚好赶在变革前夕。






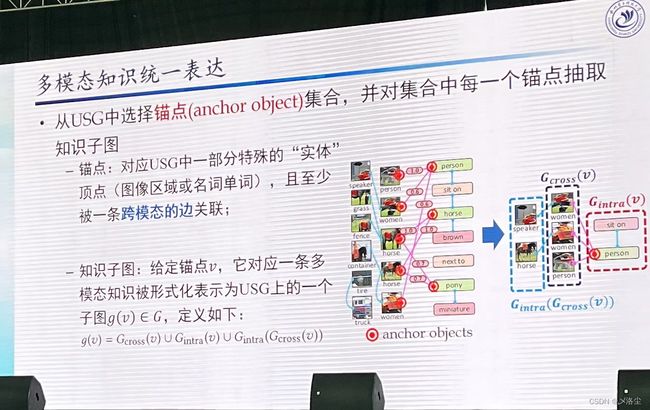






















余老师的 PPT 到这就结束了,一眼看上去绝对是诚意满满的演讲,各自方方面面都总结到了。
接下来是一作的情况:

这才是真正的研究者呀,吾辈景仰!
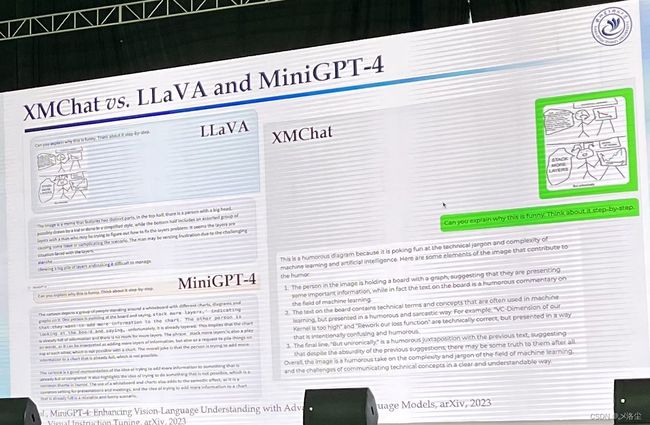
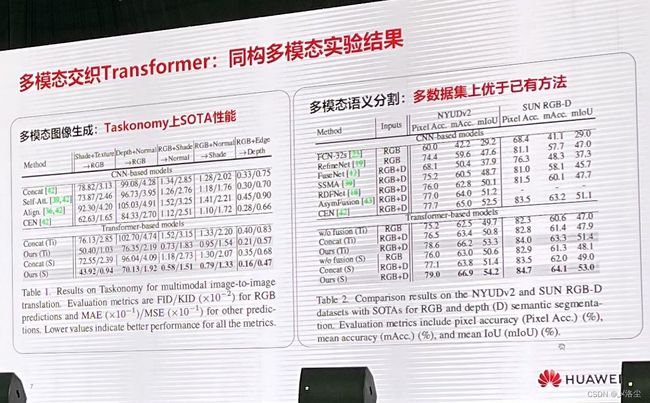
王云鹤:多模态交织:高效模型架构和融合方法


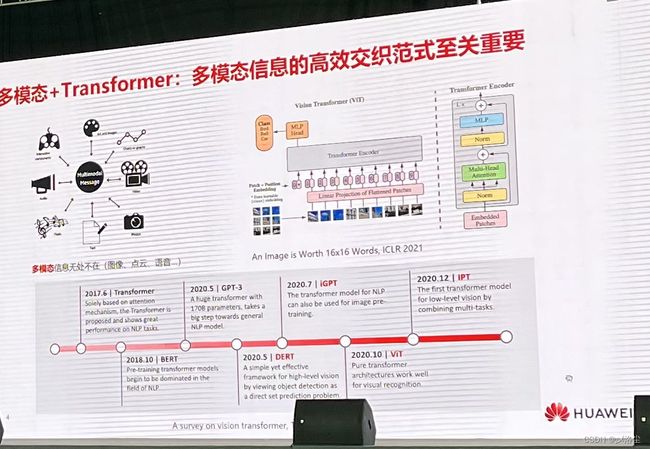
围绕着 Transformer 展开的一系列工作。
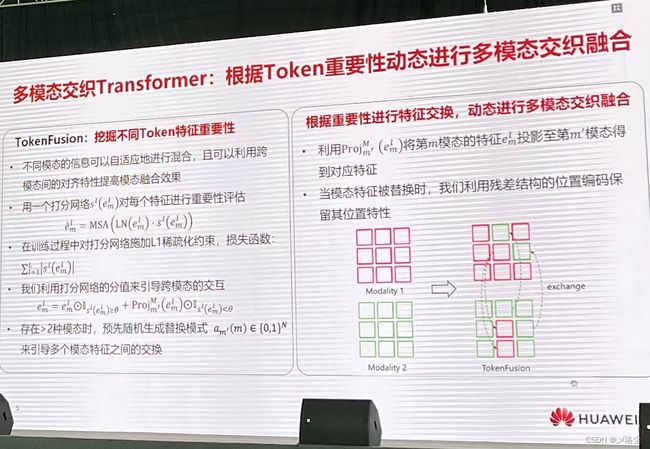
这篇文章也是想办法减少 Token 的数量来降低计算量。类似的有:
- Token系列:Joint Token Pruning and Squeezing Towards More Aggressive Compression of Vision Transformers
- 减小模型训练成本的视频动作识别 Efficient Video Transformers with Spatial-Temporal Token Selection 论文精读笔记
- Vit 中的 Token 改进版本:Token Mreging: Your Vit But Faster 论文阅读笔记



这类方法利用 GPT-4 作为桥梁来生成高质量的文本。



接下来的 VanillaNet 可以说华为确实 6。有一些解读:华为诺亚极简网络,靠13层就拿下83%精度(附源代码)





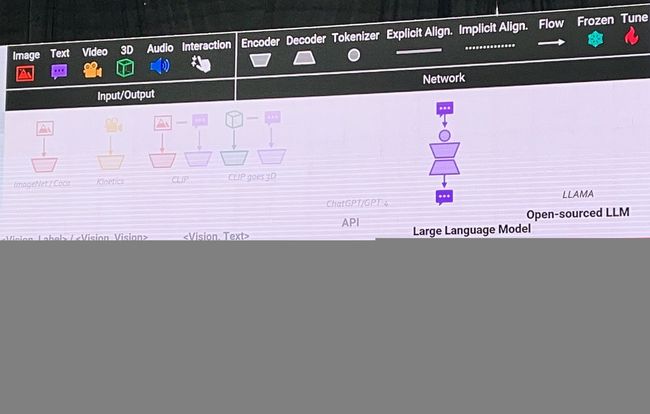
邵婧:基于LLM的多模态提示学习:框架、提示数据及评测标准
温馨提示:邵老师很幽默,看起来是个能干者。


很多图片违规了,放不出来,简言之,打篮球的某明星,生动诠释了啥叫“关必黑”呀~


朱霖潮:模态鸿沟与交互式提示学习






挖坑:博弈交互,这啥?
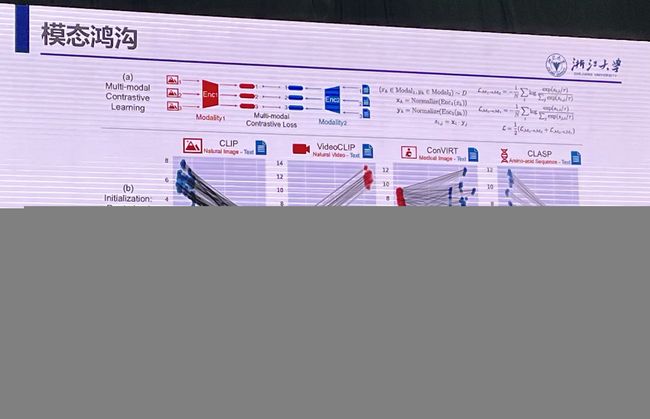
这部分有点意思,挖坑:“模态鸿沟”。








Panel 环节

Workshop:优秀学生论坛
下午的优秀学生论坛有点小失望,失望的是这些学生并未讲解自己写第一篇论文的过程,而是在谈自己的代表作或者最新工作。
另外组委会没有把同方向的老师和学生安排在一起,导致后面的讨论有点不着调了。
主持人安排的学生问题呢,也不是特别有激发灵感。
最后没人问学生问题,我就代表 Juer 问:去年 VALSE 的学生论坛以目标检测、分割为主,今年的不是这些,那么现在还有必要研究目标检测、分割的模型结构吗?
台上一位的回答:“有足够的好奇心可以坚持下去”。怎么说呢,答案没有带点启发,真正有好奇心的已经是巨佬级别了。
当然精彩的地方在于给老师们准备的问题,例如如何应对菜鸟学生以及如何指导写作,新入职的青椒如何应对非升即走,从老师的角度如何应对每周的组会。哈哈,非常有意思。
对了,我给到明年优秀学生论坛的建议一定有:希望邀请报告的优秀学生能着重讲一下他们的第一篇工作,另外合理安排方向一致的老师和同学们在同一个圆桌上。
张博航:Rethinking the Expressive Power of GNNs via Graph Biconnectivity


许牧天:基于遮蔽建模的三维室内场景自监督预训练方法及大规模多视角图片数据集


陈涵晟:基于单阶段扩散NeRF的3D生成与重建




杨啸:Towards Effective Adversarial Textured 3D Meshes on Physical Face Recognition

董伯文:Self-Promoted Supervision for Few-Shot Transformer

杨木李:Towards Distribution-Agnostic Novel Class Discovery

黄振宇:Noisy Correspondence: A New Paradigm for Learning with Noisy Label












方浩树:人类级别的通用机器人抓取


张曦予:3D Registration with Maximal Cliques

说实话,优秀学生论坛的我是真的没听懂,方向确实不一样哇。基本上他们都有自己的 Github 主页,感兴趣的可以 Follow 下他们的工作。
写在后面
为期三天的 VALSE 2023 大会顺利结束,其中一些老师提点的概念以及未来的研究方向值得细细思考。尤其是准备或正在读博的同学,这些 topic 都有可能成为博士论文的一部分。最后,期待下明年的 VALSE 2024 大会将在哪里召开。
接下来的论文阅读所选的文章真的不用发愁了,太多了(๑ŐдŐ)b。
(每天在会场门前打太极的老人家)

快捷跳转链接:
- VALSE 2023 无锡线下参会个人总结 6月10日-1
- VALSE 2023无锡线下参会个人总结 6月11日-2
- VALSE 2023 无锡线下参会个人总结 6月12日-3
- VALSE 2023 在无锡成功召开,5500余人共舞学术华尔兹