实训可视化项目小结 --- 开启Python初始之旅
Python初试感悟
语言之间是相通的,大多数时候,百分之八十的问题,都可以用常用的容器以及内置函数来辅助解决。之前从未认真接触过Python,但此次学校实训要求使用Python做一个可视化,东西不难,我个人负责爬虫部分的编写。
学习步骤:
- 学会常用的容器和基本函数,以及爬虫需要用到的库
- 学习爬虫的原理和流程
- 尝试多次练习,熟练爬虫的过程和细节.
- 在解决问题中接触学习更多的细节问题
个人感悟:
- 语言之间互通。起码在容器,面向过程这些基本的每门编程语言必备的语法traits上是一致的。
- 再往上走的面向对象设计编程呀,并发呀。更多的语法糖。可以慢慢来,学习这些东西嘛,可以需要用到时深入了解和总结使用是最好的。毕竟语法糖是学不完的。学过C++的应该都有此感想。更何况如今有了只能AI,chat,这可以更方便的辅助我们,减少人脑对于一些庞大繁杂知识的容量。而更多的积累整体框架,弱化细节,更具整体的一个把握性。
- 然后自然是了解Python的开发工具以及必备库... (Python的库是辅助每个方向的开发的,像我这次使用爬虫,自然需要用到他的web访问请求相关的库。)
- 然后对比C++和Python. 的确,完全不可否认,诸如Python此类的语言,各种开发方向的生态极其完善。几乎每一步应该怎么做都可以有库作为辅助。我们更多的可以集中在整体的设计,以及过程中细节问题的解决上。 而C++ ,我的认知也很有限,但是对比Python和C++程序跑起来的速度。个人感觉C++的的确确是快上很多。但是两种语言实用范围完全不相同。C++还是更为适合做底层的架子。高性能的框架等一些方面,至于业务,我个人没有工作经验,所以没有发言权。
- 个人得出结论。利用语言的互通有无,对比学习,我们完全有能力在很短的时间内掌握其他门的语言,所以可以更为集中在行业的方向上。而且对语言也无需害怕恐惧,或者排斥,无非,我上手他们不就是一些常用的容器,以及各种内置类对象和基础的对象定义,函数申明,循环,判断等等而已。剩下的更多,随着不断的练习,自然可以掌握
Python 基础语法
对象定义:无需指定类型,根据赋值来自动确定对象的类型。
输入输出:采用 input()和print(); 做格式化输入,输出
# python 中的输入函数input
# 变量名 = input("输入的提示")
# python 中的打印函数(格式化输出)
# pinrt ('辅助内容,%s', %变量名)
案例

然后,思考问题。发现input输入,默认是字符串类型,所以如果需要获取整形数据需要我们类型转换
name = input("what's your name? ")
age = int(input("What's your age? "))
# age = input("What's your age? ") 错误方式,获取的是%s的age
print("hello,%s" %name)
print("hello,%s years: %d" %(name, age))逻辑判断:对比发现,Python中的 if 判断不需要用{}来限定区域,而是通过缩进一致保持同一个代码块的判断.
# if expression:
# 操作
# elif expression:
# 操作
# else:
# 操作
score = int(input('请输入你的成绩:'))
if score >= 90:
print('考的不错喔, 优秀')
elif score >= 60:
print('还可以,及格了')
else:
print('小垃圾,没及格')循环遍历操作 for in range(范围) 用到比较多。遍历容器跟C++迭代器很像,连开闭区间都互通,两者maybe底层一致。
第一种
# for num in 范围:
# 操作
# range(begin, end, interval/gap)
# [begin, end)
第二种:
for value in 容器:
操作
sum = 0
for number in range(0, 10):
sum = sum + number
print(sum)
# 从1累加到9sum = 0
num = 1
while num < 11:
sum += num
num += 1
print(sum)注:另一个小区别,Python力求精简,中间很多的像是判断条件的()包裹。。。给去除掉了。显得代码更为简洁,明了
常用数据结构
列表(对应数组) [] 元组(), 字典(对应map和hashTB), 集合(对应set), 从set变来
python 中
列表就是C/C++中的数组
定义就是
列表名 = [元素]
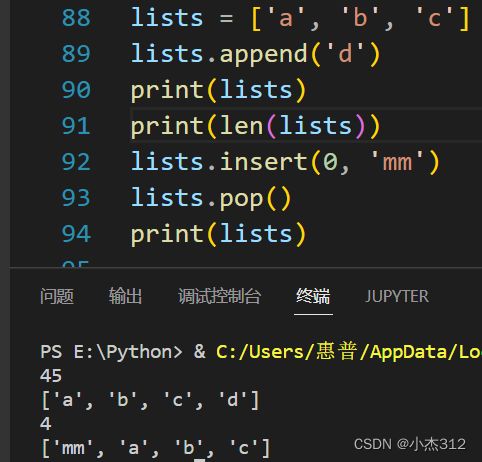
append方法:尾部插入一个元素
列表名.append(元素)
len方法:获取列表长度
len(列表名)
insert方法: 某一下标位置插入元素
inset(iterater/ind, 元素)
pop方法:尾部删除一个元素
列表名.pop()
其实按道理,只要懂得这个对应类对象的定义即可。具体的方法调用都会有提示。方法名也都大差不差。append追加用的多。具体位置插入用的都很少。跟咱刷题用C++, push_back用的多一个道理。插入删除中间元素是不效率不太好。
python中定义一个字典,也就是map或者hashTB
字典名={键:值, 键:值...}
字典插入元素
字典名[新键名] = 值
字典名.pop(键) 删除键对应元素.
print(键 in 字典) 判断字典中是否存在这个键
获取键对应的值
字典名.get(键)
看到字典,我想它的重要程度不言而喻,不管任何语言中都属于最最常用的数据结构,没有之一。它的键值对,可以帮助我们快速检索。而且很多数据的序列化格式就是字典形式。比如说Json。而且字典也是一种特别清晰明了的展开格式。很方便我们人来阅读,以及适合网络传输。
是的,JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,通常用于将数据从服务器传输到客户端。它使用键值对的形式来组织数据,并且可以嵌套多个键值对形成复杂的数据结构。因此,可以说JSON是一种字典形式组织的数据。(剥洋葱,剥菜心。一层一层的剥开里面的data)

集合名 = set([列表]), 集合是在列表的基础上完成的,set(列表)强转
add
remove
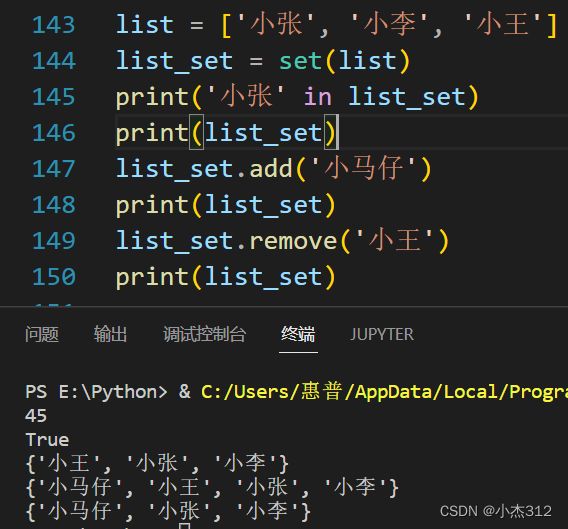
整的挺好,没有再多加别的类型标识符进来,直接复用了[]套个set转换。
# def addone(score):
# return score + 1
# print(addone(99))
'''
最后python的函数命名:
def 函数名(参数名):
函数体
return 返回值
'''
'''
求 1+3+5+7+…+99 的求和,用 Python 该如何写?
'''
# sum = 0
# num = 1
# while num < 100:
# sum += num
# num += 2
# print(sum)
Python爬虫
说的通俗一点吧:就是模拟浏览器访问web服务器的的过程,骗过服务器,爬取到服务器上面的数据并且返回回来。
爬:是真的很简单,难的是爬那里,爬回来之后数据咋做处理,咋个提取出有效数据,或者说我们需要的数据。
下面是找的比较合理的官方的一些定义,以及小杰做的一点笔记。
什么是爬虫?
请求网页并提取数据的自动化程序.
爬虫的基本流程
-
发起请求
通过HTTP库目标站点发起请求, 即发送一个Request, 请求需要包含Header信息(user-agent), 以便服务器识别同意请求.
-
获取响应
通过request的返回值获取response响应, response响应中包含html, Json字符串, 二进制数据(入图片视频) 等类型
-
解析内容
得到的可能是html, 可以用xpath网页解析库进行网页解析, 可能是Json, 转成Json对象解析, 也可能是二进制数据
-
保存数据
保存到数据库, 或者特定格式文件中.
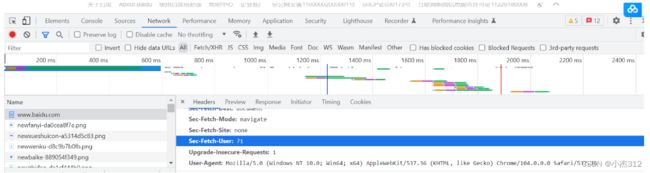
Header信息(请求头部信息)
供服务器检查的信息. (Python中通常是User-Agent),如果不携带, 服务器可能默认是是爬虫等其他陌生客户端访问给拒绝掉.
分析页面
分析我们需要爬取的页面中包含的信息. 打开google或者其他浏览器访问到对应网页。点击F12, 会出现如下一个窗口,其中比较重要的两个就是Element和Network了。一个就是网页的源代码, 另外一个就是发送的网络请求。在网络请求中就可以看见我们需要的User-Agent信息。帮助我们伪装成浏览器访问,一般不太反爬虫的服务器就可以访问成功.
网页组成成分:
-
CSS : 美化,美容
-
HTML :骨架,框架
-
js :动态,动画,动作
XPath:
XPath 是 XML的路径语言, 实际上通过元素和属性导航, 帮我们定位位置. 使用 XPath 定位,你会用到 Python 的一个解析库 lxml。(核心:lxml库的使用方式)![]()
id:唯一选择器 class:(也可选择)但不具备唯一性
过程代码化
访问过程:
# 引入requests库, 对服务器做访问
import requests
# 设置HTTP请求header
header={键:值, 键:值...}
# 设置网址, 定位服务器
url = ""
# 模拟Get访问,并且获取响应报文response
response = requests.get(url, header)
# 打印一下返回状态,看看是否访问成功
print(response.status_code)
对返回数据中的有效数据定位过程,数据解析过程
我只学了两种数据的解析和定位,一种是HTML,另外一种是Json, 说白了就是静态的那点东西。
response.text
#也就是爬取的正文内容了, 但是有时候二进制流解析过来是乱码
# 编码方式不匹配的问题
# soso 使用 content
resp_content = response.content.decode(解编码类型)解析HTML内容
- 方式1: 采用lxml库中的xpath做元素定位.
- 键html字符串文本转变为etree结点对象,方便定位。这个对象maybe底层是树形结构啥的。反正处理html的内容定位很方便。
from lxml import etree #解析html或者xml
html = etree.HTML(resp_content)
# // 模糊匹配, 定位大致范围, 子孙均可 /明确下一级。只能是儿子标签.
html.xpath('定位规则')
html.xpath('//div[@id = "content"]/a/text()')
定位所有的div标签下面的id = content的div标签下面的所有a标签下面的text()标签文本数据
- 方式2:采用re正则表达式库做数据定位处理
import re
pat = re.compile('.*? 匹配任意,老实说这种正则定位方式确实强大,但是我每太学会。不过需要用的时候可以去查,网上总有别人写了现成的匹配方式。我们只需要改很小一部分即可。
解析Json内容
这个最简单,不容质疑。
# 现如今拥有的是resp_content, 是字符串.
# 但是确实满足键值对关系的字符串# 但是,字符串都不够好处理呀。想象一下从臃肿的字符串中切割键值对还是麻烦喔。
# 要是是一个字典容器。键值不要太安逸# 所以呀万能的Python牛人必然要开发一个json库出来将Json串数据转换为对应的数据结构来方便咱们用呀
# 怎么剥洋葱,看下一层,是字典就拨开字典,是列表就拨开列表。直至拨到数据为止
import json
data_container = json.loads(resp_content)
# 接着简单,剥洋葱。扒衣服例子eg:
# dict 扒衣服
# list中是字典
rankings_list = dict_content["data"]["rankings"]
for value in rankings_list:
print(value["univNameCn"]+":"+value["ranking"])具体的实际案例:
实践过程中的一个经验,翻页啥的,或者网页嵌套啥的,都知识尾部后缀suffix做改变,所以我们可以将嵌套网页后缀搞个数组,或者是搞个翻页+= 多少啥的来处理
eg1: 爬取百度贴吧lol吧留言:
# 贴吧
# https://tieba.baidu.com/f?kw=lol&ie=utf-8&pn=0
# https://tieba.baidu.com/f?kw=lol&ie=utf-8&pn=50
import re
import requests
import json
tiebaName = 'lol'
basic_url = "https://tieba.baidu.com/f?kw={}&ie=utf-8&pn={}"
headers = {
"User-Agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36'
}
# 构造五页的数据
for i in range(5):
url = basic_url.format(tiebaName, i*50)
response = requests.get(url, headers)
content = response.content.decode('UTF-8')
pat = re.compile('eg2: 爬取一个Json格式网页的中国大学排名
#导入第三方库
import pymysql
import random
import json
import requests #发送请求
from lxml import etree #解析html或者xml
#url = 'https://music.163.com/weapi/comment/resource/comments/get?csrf_token='
url = 'https://www.shanghairanking.cn/api/pub/v1/bcur?bcur_type=11&year=2020'
# user-agent列表,用于构造随机取值
header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36'
}
resp1 = requests.get(url, header)
#print(resp1.text)
dict_content = json.loads(resp1.content)
print(type(dict_content))
# dict 扒衣服
# list中是字典
rankings_list = dict_content["data"]["rankings"]
for value in rankings_list:
print(value["univNameCn"]+":"+value["ranking"])eg3: 项目,我做的部分,爬取每一科目的每一个大学的对应排名
import requests
import re
from lxml import etree #解析html或者xml
import pymysql
headers = {
"User-Agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36'
}
url = "https://www.shanghairanking.cn/rankings/bcsr/2022"
response = requests.get(url, headers)
text_content = response.content.decode('UTF-8')
html = etree.HTML(text_content)
def is_number(input_string):
try:
float(input_string)
return True
except ValueError:
return False
info = html.xpath('//div[@id="__nuxt"]//span/text()')
suffix_list = []
subject_info_list = []
i = 2
while i < len(info):
if (is_number(info[i])):
if (len(info[i]) > 2):
suffix_list.append(info[i])
i += 1
subject_info_list.append(info[i])
i += 1
# print(subject_info_list)
# print(suffix_list)
basic_url = "https://www.shanghairanking.cn/rankings/bcsr/2022/"
connection = pymysql.connect(host="", user="", passwd=""
, database="visualize", charset="utf8")
# 创建游标
curoser = connection.cursor()
sql = 'insert into subject_school_rank values(%s, %s, %s)'
for i in range(len(suffix_list)):
value = suffix_list[i]
url = basic_url + value
# print(url)
response = requests.get(url, headers)
text_content = response.content.decode('UTF-8')
html = etree.HTML(text_content)
rank_info = html.xpath('//div[@id="content-box"]//div[@class="ranking"]/text()')
univ_name_info = html.xpath('//div[@class="logo"]/img/@alt')
univ_rank_info = []
for value in rank_info:
value = re.sub("\D", "", value)
univ_rank_info.append(value)
# print(univ_name_info)
# print(univ_rank_info)
# print(len(univ_name_info))
# print(len(univ_rank_info))
curoser.execute(sql, (subject_info_list[i], univ_name_info[0], univ_rank_info[0]))
for j in range(len(univ_rank_info)):
curoser.execute(sql, (subject_info_list[i], univ_name_info[j], univ_rank_info[j]))
j += 1
i += 1
print(i)
#编写 sql 语句
# sql = 'insert into school values(%s, %s, %s, %s)'
# for ind in range(len(univ_score)):
# result = curoser.execute(sql, (univ_rank[ind], univ_name[ind], univ_score[ind], univ_type[ind]))
# print("死循环啦?")
connection.commit()
curoser.close()
connection.close() Python数据库操作
# 导入库
import pymysql
# 连接数据库
connection = pymysql.connect(认证参数。。。)
数据库嘛都是那点参数
ip:
user:
port:
passwd:
# 创建游标,python中依赖游标执行sql
curoser = connection.cursor()
# 编写sql
sql = 'insert into subject_school_rank values(%s, %s, %s...)'
# 执行操作 (注意,以元组形式打包插入)
curoser.execute(sql, (元组数据))
# 提交操作
connection.commit()
# 关闭数据库和游标
curoser.close()
connection.close() Python学习的必要性 --- 个人浅显认知
Python学习成本相较于Java和C++更低,而且如果读研,到了实验室绝对要用。它可以帮助我们在C++难以快速深入和触及的方向让我们对一个项目,前后端呀感受的更多。而且它用来写个脚本,做个可视化。写个爬虫,部署一个框架,搭建服务器。都是非常的方便。学习,术业有专攻,方向要专一自然不错。但是如果有一颗包容的心,不畏惧新的东西,去学他。其实最后发现是可以学会的。也并没有我们想象的那么神秘。 ----- 最后祝大家天天开心,多锻炼身体,IT的学习枯燥,我们更要注重身体的保养。