ORACLE RAC ASM磁盘规划
基于ASM冗余设计架构实现的数据库双活方案,如何规划ASM?
ASM使用独特的镜像算法:不镜像磁盘,而是镜像盘区。作为结果,为了在产生故障时提供连续的保护,只需要磁盘组中的空间容量,而不需要预备一个热备(hot spare)磁盘。不建议用户创建不同尺寸的故障组,因为这将会导致在分配辅助盘区时产生问题。ASM将文件的主盘区分配给磁盘组中的一个磁盘时,它会将该盘区的镜像副本分配给磁盘组中的另一个磁盘。给定磁盘上的主盘区将在磁盘组中的某个伙伴磁盘上具有各自的镜像盘区。ASM确保主盘区和其镜像副本不会驻留在相同的故障组中。
磁盘组的冗余可以有如下的形式:双向镜像文件(至少需要两个故障组)的普通冗余(默认冗余)和使用三向镜像(至少需要3个故障组)提供较高保护程度的高冗余。 一旦创建磁盘组,就不可以改变它的冗余级别。为了改变磁盘组的冗余,必须创建具有适当冗余的另一个磁盘组,然后必须使用RMAN还原或DBMS_FILE_TRANSFER将数据文件移动到这个新创建的磁盘组。三种不同的冗余方式如下:
1、 外部冗余(external redundancy):表示Oracle不帮你管理镜像,功能由外部存储系统实现,比如通过RAID技术;有效磁盘空间是所有磁盘设备空间的大小之和。
2、 默认冗余(normal redundancy):表示Oracle提供2份镜像来保护数据,有效磁盘空间是所有磁盘设备大小之和的1/2 (使用最多)
3、 高度冗余(high redundancy):表示Oracle提供3份镜像来保护数据,以提高性能和数据的安全,最少需要三块磁盘(三个failure group);有效磁盘空间是所有磁盘设备大小之和的1/3,虽然冗余级别高了,但是硬件的代价也最高。
至于如何选择,不言而喻。
一个简单的案例:
A中心存储的LUN在系统上看到的设备文件名叫: hdisk1,hdisk2,100G hdisk3,hdisk4,20G, hdisk5,1G
B中心存储的LUN在系统上看到的设备文件名叫: hdisk6,hdisk7,100G hdisk8,hdisk9,20G, hdisk10,1G
仲裁中心的LUN在系统上看到的文件名叫:hdisk11,1G
DATA磁盘组: 规划两个failuregroup:
failuregroup1=(hdisk1,hdisk2) failuregroup2=(hdisk6,hdisk7)
策略=n
ormal
FRA磁盘组:规划两个failuregroup:
failuregroup1=(hdisk3,hdisk4) failuregroup2=(hdisk8,hdisk9)
策略=normal
OCR磁盘组:
hdisk5,hdisk10,hdisk11
ASM磁盘组规划
(1)磁盘组相关
除了OCR磁盘组之外,一般建议建立磁盘组不超过2个,一个是存放数据的数据磁盘组(+DATA),另外一个是存放日志的闪回区磁盘组(+FRA)。假设我们选择磁盘组的冗余策略为Normal,那么建议磁盘数目为偶数个并且至少为4个相同大小相同性能配置,一方面考虑到冗余为2份,另外一方面保障Failure Group里面数目的条带化分布,可以保障磁盘组的读写性能。如果是其他冗余策略,那么按照同样的思路去选择磁盘组的数目。另外Lun的大小不能超过2T(容易引起ORA-15196、ORA-15099问题)。
(2)磁盘分配单元及文件条带
AU是ASM Disk Group磁盘空间分配单元。Strip实际上是文件层面的条带,准确说法应该是文件的扩展块儿。对于文件的扩展块儿来讲就是文件切割的单元。它有两种模式(coarse & fine)。对于coarse模式来讲,扩展块儿大小等于AU大小,对应的参数固定不变(_asm_stripesize=AU,_asm_stripewidth=1)。对于fine模式来讲,扩展块儿大小是可以进行调整,根据我们的业务需求进行适当调整。例如设置为256K,那么原来1M的文件写在一个磁盘中的AU中,那么现在可以并行写入到赐个磁盘的4个AU当中。充分发挥了小IO的并行读写性能。但是对于某些大IO的数据库业务,那么AU可以适当调整到4M,同时启用操作系统的大页读写参数。文件扩展块儿可以保持corse模式。对于一般的OLTP业务来讲,数据文件、归档文件一般设置为corse;而redo日志、控制文件、flashback日志设置为fine。对于11g之后的oracle,这些参数基本不需要我们去主动调整,除非确实有性能问题与之相关。
2.5 ASM内存管理参数
(1)内存参数相关
db_cache_size: 缓冲区,存放metadata块儿的buffer cache,建议值为64M。
shared_pool: 管理ASM实例所需要的内存池,建议值为128M。
Large_pool: 用来存储 extent maps,建议值为64M。
(2)其他参数相关
在11g当中,如果多个数据库共享ASM实例的话,那么建议按照以下规则计算process的数目设置。
ASM processes = 25 + (10 + max(可能的并发数据文件变化))* 数据库的数目。当然这个数目需要一个经验的评估,需要根据集群环境数据库的情况以及业务IO的判断来估算。
2.6 异步IO配置
一般来讲数据库应用都是要启用异步IO来提高数据库的IO性能。同时需要打开操作系统的异步IO参数和数据库的异步IO参数。以Linux为例,在操作系统层面需要设置参数 aio-max-nr=1048576(11g 中设置为 4194304),表示同时可以拥有的异步IO请求数目。然后在Oracle数据库层面设置以下两个参数:filesystemio_option=setall;disk_asynch_io=true。对于AIX来说,需要设置以下三个参数(aix_maxservers, aix_minservers,aio_maxreqs)对于OLTP业务来讲,IBM官方的建议值为(800,200,16384)。
以上的参数值只是一个通用的参考,但是以上所述的参数具体配置的值还是需要根据自己环境的数据来评估。比如我们需要关注iostat中的io等待情况和aio的一系列指标来判断设置值的科学与否。
2.7 ASMLib & Udev
对于Linux平台而言,Oracle RAC的ASM磁盘管理有三种方式(ASMlib、DM、udev),我们首选的方式是ASMlib,对于 RHEL6(从6.4开始),内核驱动软件包'kmod-oracleasm'已经在 Redhat 平台上启动,并且可以通过RedHat Network (RHN)上的"RHEL Server Supplementary (v. 6 64-bit x86_64)" 渠道进行安装。这个模块的更新将会由 RedHat 提供。
对于ASMlib的方式,它是通过以下命令方式创建ASM磁盘:
# /usr/sbin/oracleasm createdisk disk_name device_partition_name
通过这种方式创建的ASM磁盘组名称(disk_name),唯一绑定的是后面的device_partition_name,因此我们必须保障操作系统在日后的Lun变更过程中,这个命名是不能够变更的。假设我们用的是第三方多路径软件管理方式实现,那么需要通过多路径管理软件的方式来讲磁盘的device_partition_name和磁盘的唯一ID关联。例如emcpowerpath可以用emcadm export/import方式来保障Rac节点上的Lun名称一致。
对于udev的方式,同样道理我们需要将磁盘的scsi-id和最终形成的asm磁盘名称进行关联,而不是用磁盘在操作系统显示的设备名来关联。例如:
KERNEL=="sd*", BUS=="scsi", PROGRAM=="/sbin/scsi_id -g -u -s %p", RESULT=="36000c29a972d7d5fe0bf683b21046b34", NAME="asmgrid_disk1", OWNER="grid", GROUP="asmadmin", MODE="0660"
其中的PROGRAM字段非常重要,它表示我们是用什么方式来关联磁盘在操作系统和ASM之间的对应关系。如果在日后的运维过程中,随着磁盘的增减变化或者服务器的重启变更等导致了磁盘设备名发生变化,那么就会导致ASM磁盘符号紊乱,最终数据库集群无法启动。当然这个问题在11g之后就不存在了,因为11g之后ASM自动会去根据磁盘的唯一ID匹配ASM识别的磁盘ID,节点的读写是根据磁盘的ASM标示来执行的。但是从管理科学角度还是应该按照最佳实践来做从而保障没有任何风险。
2.8 AIX平台关注的存储参数
对于AIX平台而言,存储卷的系统参数必须遵循以下规则。
(1) reserve_lock、reserve_policy
该两个参数其实都是表示操作系统是否持有存储卷的共享锁方式。存储阵列类型为SSA, FAStT, 或者其他 non-MPIO-capable disks,参数设置参照A。存储阵列类型为SS, EMC, HDS, CLARiiON, 或者其他 MPIO-capable disks,参数设置方式参照B。
A. # chdev -l hdiskn -a reserve_lock=no
B. # chdev -l hdiskn -a reserve_policy=no_reserve
(2) 磁盘在加入ASM磁盘组之前,必须清除其盘头PVID信息。否则就会导致ORA-15063、ORA-15040、ORA-15042等磁盘错误。
(3) fc_err_recov。
该参数表示因为AIX平台下光纤断掉场合下,读写错误切换的时间。正常情况下,这个切换会导致数据库IO挂起10分钟。如果是Vote disk,就会导致集群重启。为了避免此类情况发生需要把该参数的值设置为fast_fail,实现快速切换。
(4) max_transfer。
该参数建议设置最少为Oracle最大请求的IO大小,一般超过1M。
(5) queue_depth。
该参数表示Lun的最大IO队列深度,这个参数的设置必须足以支撑数据库并发读写的负载。
(6) max_xfer_size。
该参数表示光纤卡的最大传输大小,这个参数的设置必须与磁盘的吞吐参数保持倍数关系,并且必须大于磁盘设置的参数。
(7) num_cmd_elems。
该参数表示光纤卡接受的最大IO请求数目,这个参数同样与磁盘的queue_depth有着倍数关系,具体值的设定需要看环境当中光纤卡和其所容纳Lun的数目。
3.网络规划设计的关键点
3.1 硬件及参数
从Oracle官方的推荐来看,他们首先推荐使用万兆以太网,至少使用千兆以太网,负载如果很高那么私网可以采用infiniband。当然这个完全取决于客户生产环境的具体业务量及负载情况。这个仅仅是个参考,有条件的情况下可以按照推荐进行配置。私网的连接需要使用交换机,Oracle集群安装并不支持私网的直连架构。网卡及交换机的双攻击速率参数保持正确一致。
3.2 网卡绑定
各种平台都有自己的网卡绑定工具,而且提供负载均衡和主备模式的绑定。首先为了提高公网和私网的网络高可用,网卡需要绑定。对于Linux平台我们需要在配置文件 “/etc/modprobe.d/dist.conf” 中将数mode来控制网卡绑定的具体策略:
mod=0,即:(balance-rr)Round-robin policy(平衡抡循环策略)。
mod=1,即: (active-backup)Active-backup policy(主-备份策略)。
mod=2,即:(balance-xor)XOR policy(平衡策略)。
mod=3,即:broadcast(广播策略)。
mod=4,即:IEEE 802.3ad Dynamic link aggregation(IEEE802.3ad 动态链接聚合)。
mod=5,即:(balance-tlb)Adaptive transmit load balancing(适配器传输负载均衡)。
mod=6,即:(balance-alb)Adaptive load balancing(适配器适应性负载均衡)。
对于私网网卡绑定方式mode=3&6会导致ORA-600,公网网卡绑定方式mode=6会导致BUG9081436。对于具体的绑定模式,对于平台版本低而且网络架构非常复杂的场合,还是建议主备模式,因为主备模式更稳定,不容易产生数据包路径不一致的问题。如果是负载均衡模式的场合,如果网络参数设置不是很科学的情况下,很容易出现从一个物理网卡发送报文,但是回报文却回到另外一个物理网卡上,网络链路再加入防火墙的规则之后,非常容易导致丢包问题发生。
而对于AIX平台来讲,将参数mode修改为NIB或者Standard值。Standard是根据目标IP地址来决定用哪个物理网卡来发送报文,是基于IP地址的负载均衡,也不易产生上述的丢包问题。
3.3 SCAN
Oracle RAC,从11gr2之后增加了SCAN(Single ClientAccess Name)的特性。
SCAN是一个域名,可以解析至少1个IP,最多解析3个SCAN IP,客户端可以通过这个SCAN 名字来访问数据库,另外SCAN ip必须与public ip和VIP在一个子网。启用SCAN 之后,会在数据库与客户端之间,添加了一层虚拟的服务层,就是SCAN IP和SCAN IP Listener,在客户端仅需要配置SCAN IP的tns信息,通过SCANIP Listener,连接后台集群数据库。这样,不论集群数据库是否有添加或者删除节点的操作,均不会对客户端产生影响,也就不需要修改配置。对于SCAN相关的配置,有以下一些配置注意事项:
(1)主机的默认网关必须与SCAN以及VIP在同一个子网上。
(2)建议通过 DNS,按round-robin方式将 SCAN 名称(11gR2 和更高版本)至少解析为 3 个 IP 地址,无论集群大小如何。
(3)为避免名称解析出现问题,假设我们设置了三个SCAN地址,那么HOSTs文件当中不能出现SAN的记录,因为HOSTs文件当中的记录是静态解析,与DNS动态解析相悖。
3.4 网络参数
操作系统平台上关于网络的内核参数非常重要,直接决定私网公网数据传输的稳定性和性能。不过针对不同的操作系统,相关的参数设置也各有差异。
1.Linux
对于Linux平台的内核参数,有两个非常重要(net.core.rmem_default、net.core.rmem_max)。具体功能解释如下:
net.ipv4.conf.eth#.rp_filter:数据包反向过滤技术。
net.ipv4.ip_local_port_range:表示应用程序可使用的IPv4端口范围。
net.core.rmem_default:表示套接字接收缓冲区大小的缺省值。
net.core.rmem_max:表示套接字接收缓冲区大小的最大值。
net.core.wmem_default:表示套接字发送缓冲区大小的缺省值。
net.core.wmem_max:表示套接字发送缓冲区大小的最大值。
为了获得更好的网络性能,我们需要根据具体情况把以上两个参数从其默认值适当调整为原来的2-3倍甚至更高,关闭或者设置反向过滤功能为禁用0或者宽松模式2。
2.AIX
对于AIX平台的内核参数,以下设置是从Oracle官方文档摘出的最佳配置:
tcp_recvspace = 65536;tcp_sendspace = 65536;
udp_sendspace = ((db_block_size *db_multiblock_read_count) + 4096) ;
udp_recvspace = 655360;
rfc1323 = 1;
sb_max = 4194304;
ipqmaxlen = 512;
第1、2个参数表示TCP窗口大小,第3、4个参数表示UDP窗口大小。rfc1323启用由 RFC 1323(TCP 扩展以得到高性能)指定的窗口定标和时间图标。窗口定标允许 TCP 窗口大小(tcp_recvspace 和 tcp_sendspace)大于 64KB(65536)并且通常用于大的 MTU 网络。默认为0(关),如果试图将 tcp_sendspace 和 tcp_recvspace 设为大于 64 KB则需要先修改此值为1。ipqmaxlen 表示指定接收包的数目,这些包可以列在 IP 协议输入队列中。sb_max指定一个 TCP 和 UDP 套接字允许的最大缓冲区大小。
3.5 安全配置事项
1.Linux平台下的防火墙需要关闭,否则会引起公网或者私网的通讯问题。
# chkconfig iptables stop
2.Linux平台下的selinux安全配置项需要关闭,配置文件为/etc/security/config。
SELINUX=disabled
3.如果是Power System主机的PowerVM虚拟化架构下的AIX平台,如果发现Oracle RAC的两个节点之间有大量丢包现象或者是以下几种事件:
Cache Fusion "block lost"
IPC Send timeout
Instance Eviction
SKGXPSEGRCV: MESSAGE TRUNCATED user data nnnn bytes payload nnnn bytes
那么我们需要检查VIOS分区操作系统的补丁信息,如果没有APAR IZ97457,那么我们需要将这个补丁打上,详细需到IBM官网找到相应的补丁及其详细解释。
3.6 通用注意事项
1.系统主机名、域名等配置不允许有下划线。
2.网卡名称在两个节点上保持一致(例:public->eth1ð1,private->eth2ð2)。
3.网卡设备名称当中不能包含“.”等特殊字符。
4.私网地址需遵守RFC1918标准,采用其所规定的ABC三类企业内部私网地址。否则会引起BUG4437727发生。A类:10.0.0.0 -10.255.255.255 (10/8比特前缀); B类:172.16.0.0 -172.31.255.255 (172.16/12比特前缀); C类:192.168.0.0 -192.168.255.255 (192.168/16比特前缀)。而且私网VLAN需要与上述no-routeable子网之间需要是1:1的映射关系,以免引起BUG9761210。
5.从11gr2起,私网网段配置需要支持组播功能,因为私网需要通过组播模式实现通讯。
3.7 send (tx) / receive (rx)
UDP包传输的过程中,接受进程会读取数据包头的校验值。任何校验值损坏都会使这个包被丢弃,并导致重发,这会增加CPU的使用率并且延缓数据包处理。
由于网卡上开启了Checksum offloading 导致了checksum 错误,如果出现这样的问题请检查checksum offloading的功能是否被禁用,测试后考虑关闭网卡上的该项功能。在Linux系统上执行ethtool -K
3.8 MTU
不匹配的MTU大小设置会导致传输过程中出现 "packet too big" 错误并丢失数据包,导致global cache block丢失和大量的重传(retransmission)申请。而且私网中不一致的MTU值会导致节点无法加入集群的问题。
对于以太网(Ethernet),大多数UNIX平台的默认值是1500字节。私网链路中所有设备都应该定义相同的MTU。请确认并监控私网链路中的所有的设备。为ping ,tracepath,traceroute命令指定大的,非默认尺寸,ICMP probe 包来检查MTU设置是否存在不一致。使用ifconfig或者厂商推荐的工具为服务器网卡(NIC)的MTU设置合适的值。
Jumbo Frames 并不是IEEE 标准配置。单个Jumb Frame的大小是9000 bytes左右。Frame 的大小取决于网络设备供应商,在不同的通信设备上的大小可能是不一致的。如果默认的MTU 尺寸不是9000bytes,请保证通信路径中的所有设备(例如:交换机/网络设备/网卡)都能够支持一个统一的MTU值,在操作的过程中必须把Frame Size(MTU Size)配置成这个值。不合适的MTU设置,例如:交换机上配置MTU=1500,但是服务器上的私网网卡配置成MTU=9000,这样会造成丢包,包的碎片和重组的错误,这些都会导致严重的性能问题和节点异常宕机。大部分的平台上我们都可以通过netstat –s命令的‘IP stats’输出发现包的碎片和重组的错误。大部分的平台上我们可以通过ifconfig –a命令找到frame size的设置。关于交换机上的配置查询,需要查看交换机提供商的文档来确定。
-------------------------------------------------------------------------------------------------------------------------------------------------------
二、RAC软件模块
为了更加深入的理解Oracle RAC我们看一下其内部软件模块的组成。整个数据库层面没有太多差异,这里面主要多出了如下内容:虚拟IP(VIP)、ASM、Clusterware和仲裁磁盘。这些新组件配合起来完成了Oracle的多活集群功能。
虚拟IP是应用访问数据库的入口,该IP并不与任何服务器绑定,而是可以在集群的任意服务器间漂移。由于具有这个特性,当出现服务器宕机等情况时,数据集集群可以保证通过相同的接口对外提供服务。
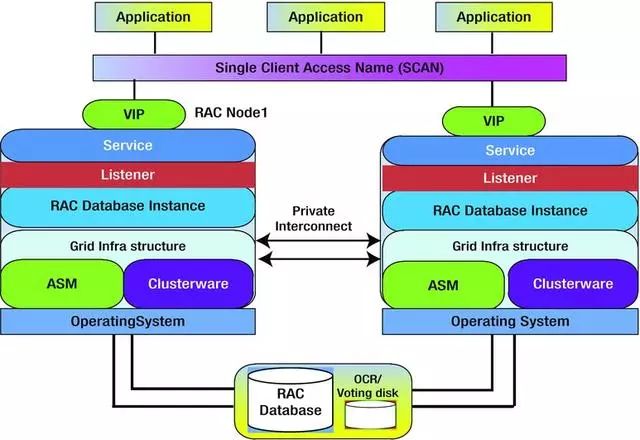
图5 Oracle RAC软件模块图
ASM与Clusterware实现了集群管理功能,其中ASM实现对磁盘的管理,避免同时访问磁盘导致数据不一致的风险,而Clusterware则用于管理Oracle集群的软件进程及资源调度。
仲裁磁盘用于集群中服务器的异常判断,集群中的节点通过定时更新仲裁磁盘中特定区域的数据标示自身的健康状态。其它节点可以根据该数据判断该节点是否宕机。
-----------------------------------------------------------------------------------------------------------------------
(四)RAC、DG和OGG的区别
RAC和DG是高可用体系中的常用的两种工具,每个工具既可以独立应用,也可以相互配合使用。但是它们各自的侧重点不同,适用场景也不同。
RAC是本地的高可用集群,每个节点用来分担不同或相同的应用,以解决运算效率低下、单点故障这样的问题,它是几台硬件相同或不相同的服务器加一个共享存储来构成的。RAC的强项在于解决单点故障和负载均衡,所以,RAC方案常用于7*24的核心系统,但RAC方案中的数据只有一份,尽管可以通过RAID等机制避免存储故障,但是数据本身是没有冗余的,因此需要加强备份。
DG是Oracle的远程复制技术,它有物理和逻辑之分,但是总的来说,它需要在异地有一套独立的系统,是一种异地容灾的解决方案。DG通过冗余数据的方式来提供数据保护,通过日志同步机制保证冗余数据和主库之间的同步,这种同步可以是实时、延时、同步或异步等多种形式。DG常用于异地容灾和小企业的高可用性方案,可以在备库上执行只读地查询操作,从而分散主库的性能压力。
OGG软件是一种基于日志的结构化数据复制备份软件,它通过解析源数据库在线日志或归档日志获得数据的增量变化,再将这些变化应用到目标数据库,从而实现源数据库与目标数据库的同步。OGG可以实现一对一、广播(一对多)、聚合(多对一)、双向复制、层叠、点对点、级联等多种灵活的拓扑结构,可以实现只复制某几个表的功能。
Oracle高可用性产品比较见下表:
| 双机热备/Failsafe |
OPS(Oracle Parallel Server) |
RAC |
DG(DataGuard) |
OGG |
|
| 共享存储 |
不是 |
有 |
有 |
独立存储 |
不是 |
| 保护类型 |
热备只有1个实例,1个数据库,做不了并发和负载均衡 |
实例冗余,负载均衡 |
实例级冗余 |
数据库层次冗余 |
schema或表级别冗余 |
| 需要的软硬件资源 |
只有两台机器和磁盘阵列,有一个漂移的IP,不能共享存储 |
有两台机器和磁盘阵列,有两个虚拟IP |
可以有多台机器和磁盘阵列,1个节点有1个虚拟IP |
有独立的机器和独立的存储 |
有独立的机器和独立的存储 |
| 优缺点 |
Failsafe是免费的,一台服务器闲置,硬件浪费较大 |
在并发读写性能上较差 |
读写并发性能较好,但是对于DBA的技能和专业性要求较高,软件上也需要单独购买 |
是一个轻量级的容灾系统,从Oracle 11g开始还能在备库节点上进行读写和自动故障转移 |
可以在表或schema级别实现实时复制,可以实现双向同步 |
| 拓扑结构 |
支持一对多模式,只能实现单向同步 |
支持一对一、一对多、多对一、双向复制等多种拓扑结构 |