基于开源Tars的动态负载均衡实践
一、背景
vivo 互联网领域的部分业务在微服务的实践过程当中基于很多综合因素的考虑选择了TARS微服务框架。
官方的描述是:TARS是一个支持多语言、内嵌服务治理功能,与Devops能很好协同的微服务框架。我们在开源的基础上做了很多适配内部系统的事情,比如与CICD构建发布系统、单点登录系统的打通,但不是这次我们要介绍的重点。这里想着重介绍一下我们在现有的负载均衡算法之外实现的动态负载均衡算法。
二、什么是负载均衡
维基百科的定义如下:负载平衡(Load balancing)是一种电子计算机技术,用来在多个计算机(计算机集群)、网络连接、CPU、磁盘驱动器或其他资源中分配负载,以达到优化资源使用、最大化吞吐率、最小化响应时间、同时避免过载的目的。使用带有负载平衡的多个服务器组件,取代单一的组件,可以通过冗余提高可靠性。负载平衡服务通常是由专用软件和硬件来完成。主要作用是将大量作业合理地分摊到多个操作单元上进行执行,用于解决互联网架构中的高并发和高可用的问题。
这段话很好理解,本质上是一种解决分布式服务应对大量并发请求时流量分配问题的方法。
三、TARS 支持哪些负载均衡算法
TARS支持三种负载均衡算法,基于轮询的负载均衡算法、基于权重分配的轮询负载均衡算法、一致性hash负载均衡算法。函数入口是selectAdapterProxy,代码在 TarsCpp 文件里,感兴趣的可以从这个函数开始深入了解。
3.1 基于轮询的负载均衡算法
基于轮询的负载均衡算法实现很简单,原理就是将所有提供服务的可用 ip 形成一个调用列表。当有请求到来时将请求按时间顺序逐个分配给请求列表中的每个机器,如果分配到了最后列表中的最后一个节点则再从列表第一个节点重新开始循环。这样就达到了流量分散的目的,尽可能的平衡每一台机器的负载,提高机器的使用效率。这个算法基本上能满足大量的分布式场景了,这也是TARS默认的负载均衡算法。
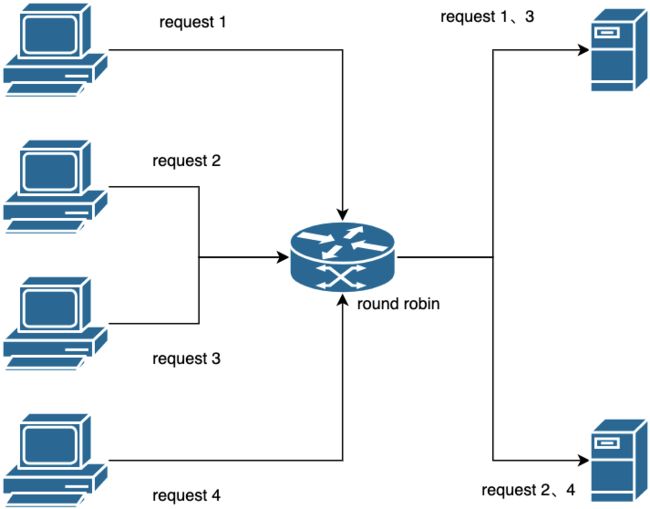
但是如果每个节点的处理能力不一样呢?虽然流量是均分的,但是由于中间有处理能力较弱的节点,这些节点仍然存在过载的可能性。于是我们就有了下面这种负载均衡算法。
3.2 基于权重分配的轮询负载均衡算法
权重分配顾名思义就是给每个节点赋值一个固定的权重,这个权重表示每个节点可以分配到流量的概率。举个例子,有5个节点,配置的权重分别是4,1,1,1,3,如果有100个请求过来,则对应分配到的流量也分别是40,10,10,10,30。这样就实现了按配置的权重来分配客户端的请求了。这里有个细节需要注意一下,在实现加权轮询的时候一定要是平滑的。也就是说假如有10个请求,不能前4次都落在第1个节点上。
业界已经有了很多平滑加权轮询的算法,感兴趣的读者可以自行搜索了解。

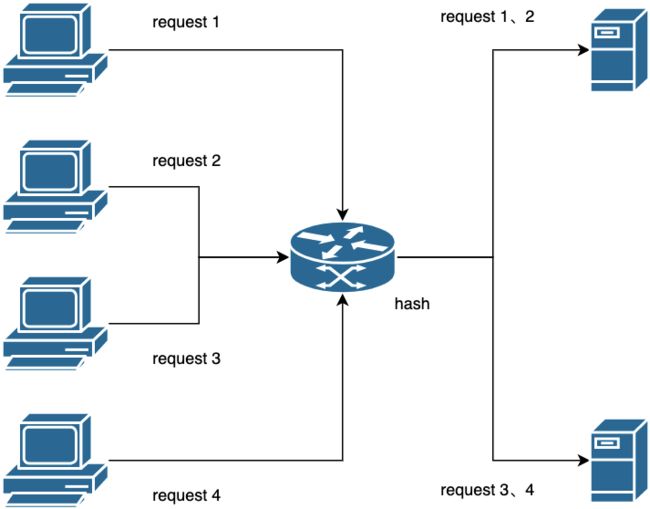
3.3 一致性Hash
很多时候在一些存在缓存的业务场景中,我们除了对流量平均分配有需求,同时也对同一个客户端请求应该尽可能落在同一个节点上有需求。
假设有这样一种场景,某业务有1000万用户,每个用户有一个标识id和一组用户信息。用户标识id和用户信息是一一对应的关系,这个映射关系存在于DB中,并且其它所有模块需要去查询这个映射关系并从中获取一些必要的用户字段信息。在大并发的场景下,直接请求DB系统肯定是抗不住的,于是我们自然就想到用缓存的方案去解决。是每个节点都需要去存储全量的用户信息么?虽然可以,但不是最佳方案,万一用户规模从1000万上升到1亿呢?很显然这种解决方案随着用户规模的上升,变得捉襟见肘,很快就会出现瓶颈甚至无法满足需求。于是就需要一致性hash算法来解决这个问题。一致性hash算法提供了相同输入下请求尽可能落在同一个节点的保证。
为什么说是尽可能?因为节点会出现故障下线,也有可能因为扩容而新增,一致性hash算法是能够在这种变化的情况下做到尽量减少缓存重建的。TARS使用的hash算法有两种,一种是对key求md5值后,取地址偏移做异或操作,另一种是ketama hash。
四、为什么需要动态负载均衡?
我们目前的服务大部分还是跑在以虚拟机为主的机器上,因此混合部署(一个节点部署多个服务)是常见现象。在混合部署的情况下,如果一个服务代码有bug了占用大量的CPU或内存,那么必然跟他一起部署的服务都会受到影响。
那么如果仍然采用上述三种负载均衡算法的情况下,就有问题了,被影响的机器仍然会按指定的规则分配到流量。也许有人会想,基于权重的轮询负载均衡算法不是可以配置有问题的节点为低权重然后分配到很少的流量么?确实可以,但是这种方法往往处理不及时,如果是发生在半夜呢?并且在故障解除后需要再手动配置回去,增加了运维成本。因此我们需要一种动态调整的负载均衡算法来自动调整流量的分配,尽可能的保证这种异常情况下的服务质量。
从这里我们也不难看出,要实现动态负载均衡功能的核心其实只需要根据服务的负载动态的调整不同节点的权重就可以了。这其实也是业界常用的一些做法,都是通过周期性地获取服务器状态信息,动态地计算出当前每台服务器应具有的权值。
五、动态负载均衡策略
在这里我们采用的也是基于各种负载因子的方式对可用节点动态计算权重,将权重返回后复用TARS静态权重节点选择算法。我们选择的负载因子有:接口5分钟平均耗时/接口5分钟超时率/接口5分钟异常率/CPU负载/内存使用率/网卡负载。负载因子支持动态扩展。
整体功能图如下:
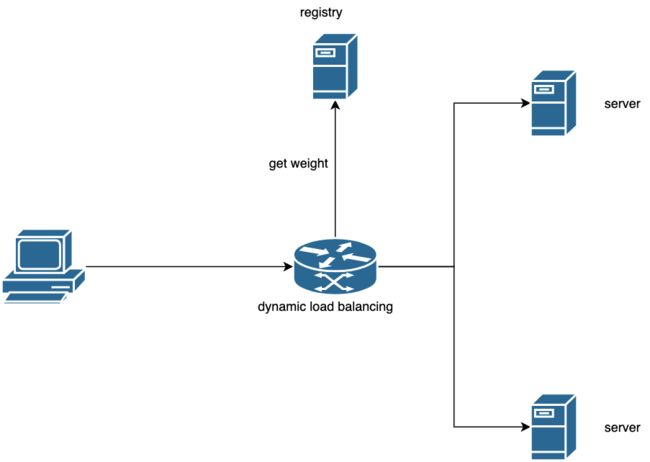
5.1 整体交互时序图

rpc调用时,EndpointManager定期获得可用节点集合。节点附带权重信息。业务在发起调用时根据业务方指定的负载均衡算法选择对应的节点;
RegistrServer定期从db/监控中习获取超时率和平均耗时等信息。从其它平台(比如CMDB)获得机器负载类信息,比如cpu/内存等。所有计算过程线程异步执行缓存在本地;
EndpointManager根据获得的权重执行选择策略。下图为节点权重变化对请求流量分配的影响:
5.2 节点更新和负载均衡策略
节点所有性能数据每60秒更新一次,使用线程定时更新;
计算所有节点权重值和取值范围,存入内存缓存;
主调获取到节点权重信息后执行当前静态权重负载均衡算法选择节点;
兜底策略:如果所有节点要重都一样或者异常则默认采用轮询的方式选择节点;
5.3 负载的计算方式
负载计算方式:每个负载因子设定权重值和对应的重要程度(按百分比表示),根据具体的重要程度调整设置,最后会根据所有负载因子算出的权重值乘对应的百分比后算出总值。比如:耗时权重为10,超时率权重为20,对应的重要程度分别为40%和60%,则总和为10 * 0.4 + 20 * 0.6 = 16。对应每个负载因子计算的方式如下(当前我们只使用了平均耗时和超时率这两个负载因子,这也是最容易在TARS当前系统中能获取到的数据):
1、按每台机器在总耗时的占比反比例分配权重:权重 = 初始权重 *(耗时总和 - 单台机器平均耗时)/ 耗时总和(不足之处在于并不完全是按耗时比分配流量);
2、超时率权重:超时率权重 = 初始权重 - 超时率 * 初始权重 * 90%,折算90%是因为100%超时时也可能是因为流量过大导致的,保留小流量试探请求;
对应代码实现如下:
void LoadBalanceThread::calculateWeight(LoadCache &loadCache)
{
for (auto &loadPair : loadCache)
{
ostringstream log;
const auto ITEM_SIZE(static_cast(loadPair.second.vtBalanceItem.size()));
int aveTime(loadPair.second.aveTimeSum / ITEM_SIZE);
log << "aveTime: " << aveTime << "|"
<< "vtBalanceItem size: " << ITEM_SIZE << "|";
for (auto &loadInfo : loadPair.second.vtBalanceItem)
{
// 按每台机器在总耗时的占比反比例分配权重:权重 = 初始权重 *(耗时总和 - 单台机器平均耗时)/ 耗时总和
TLOGDEBUG("loadPair.second.aveTimeSum: " << loadPair.second.aveTimeSum << endl);
int aveTimeWeight(loadPair.second.aveTimeSum ? (DEFAULT_WEIGHT * ITEM_SIZE * (loadPair.second.aveTimeSum - loadInfo.aveTime) / loadPair.second.aveTimeSum) : 0);
aveTimeWeight = aveTimeWeight <= 0 ? MIN_WEIGHT : aveTimeWeight;
// 超时率权重:超时率权重 = 初始权重 - 超时率 * 初始权重 * 90%,折算90%是因为100%超时时也可能是因为流量过大导致的,保留小流量试探请求
int timeoutRateWeight(loadInfo.succCount ? (DEFAULT_WEIGHT - static_cast(loadInfo.timeoutCount * TIMEOUT_WEIGHT_FACTOR / (loadInfo.succCount
+ loadInfo.timeoutCount))) : (loadInfo.timeoutCount ? MIN_WEIGHT : DEFAULT_WEIGHT));
// 各类权重乘对应比例后相加求和
loadInfo.weight = aveTimeWeight * getProportion(TIME_CONSUMING_WEIGHT_PROPORTION) / WEIGHT_PERCENT_UNIT
+ timeoutRateWeight * getProportion(TIMEOUT_WEIGHT_PROPORTION) / WEIGHT_PERCENT_UNIT ;
log << "aveTimeWeight: " << aveTimeWeight << ", "
<< "timeoutRateWeight: " << timeoutRateWeight << ", "
<< "loadInfo.weight: " << loadInfo.weight << "; ";
}
TLOGDEBUG(log.str() << "|" << endl);
}
}
相关代码实现在RegistryServer,代码文件如下图:

核心实现是LoadBalanceThread类,欢迎大家指正。
5.4 使用方式
- 在Servant管理处配置-w -v 参数即可支持动态负载均衡,不配置则不启用。
如下图:

- 注意:需要全部节点启用才生效,否则rpc框架处发现不同节点采用不同的负载均衡算法则强制将所有节点调整为轮询方式。
六、动态负载均衡适用的场景
如果你的服务是跑在Docker容器上的,那可能不太需要动态负载均衡这个特性。直接使用Docker的调度能力进行服务的自动伸缩,或者在部署上直接将Docker分配的粒度拆小,让服务独占docker就不存在相互影响的问题了。如果服务是混合部署的,并且服务大概率会受到其它服务的影响,比如某个服务直接把cpu占满,那建议开启这个功能。
七、下一步计划
目前的实现中只考虑了平均耗时和超时率两个因子,这能在一定程度上反映服务能力提供情况,但不够完全。因此,未来我们还会考虑加入cpu使用情况这些能更好反映节点负载的指标。以及,在主调方根据返回码来调整权重的一些策略。
最后也欢迎大家与我们讨论交流,一起为TARS开源做贡献。
作者:vivo互联网服务器团队-Yang Minshan