SpringBoot的日志
SpringBoot的日志
- 日志是什么
- 日志的作用
- 日志级别
-
- 日志级别的作用
- 日志级别的分类
- 日志级别的设置
- 打印日志
-
- 打印日志
- 具体内容划分
- 常用的日志框架
-
- 为什么这样设计
- 对比System.out.ptintln()与日志框架
- 日志的持久化
- Lombok—更简单的打印日志
-
- 对比得到日志的方式
- 创建SpringBoot项目时忘记添加Lombok怎么办
- 结尾
日志是什么
日志
记录软件运行状态, 事件和错误信息的一种机制
如图即为 Spring Boot 的日志
日志的作用
- 记录软件的运行状态, 错误信息, 警告信息
(目的是为了在出现问题时能够快速定位和解决问题) - 分析软件的性能, 用户的行为
(目的是为了优化软件产品) - 监控软件的运行情况
(目的是为了保证软件的稳定性)
日志级别
日志级别的作用
- 快速筛选出重要的日志
- 根据环境的不同设置不同的日志级别
举个栗子
当前环境是开发环境, 通常设置的日志级别为 debug
当前环境是生产环境, 通常设置的日志级别为 warn / error
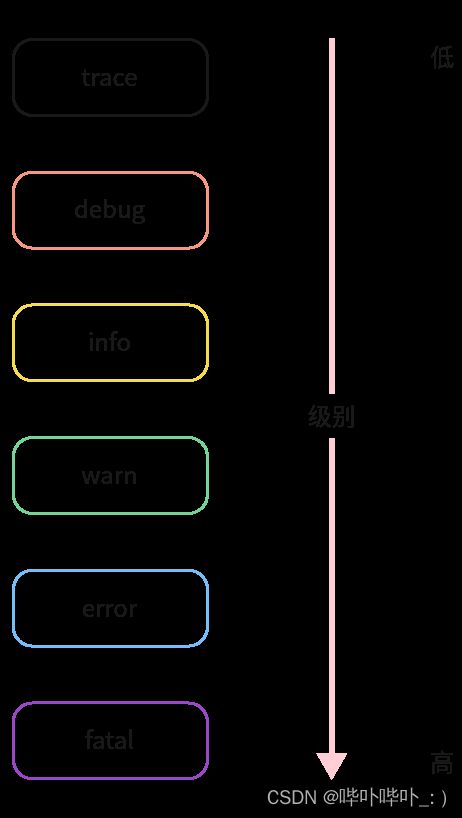
日志级别的分类
- trace → 微量, 少许(级别最低)
- debug → 调试
- info → 普通的打印信息(默认日志级别)
- warn → 警告⚠(出现警告不影响使用, 但需要注意警告的问题)
- error → 错误
- fatal → 致命的(不能自定义设置, 代码异常导致程序退出)
日志级别的设置
日志级别的设置通常在对应的环境中进行设置, 而不是直接在配置文件中设置
logging:
level:
root: error # root -> 设置全部的日志级别
对应的包名:
对印的类名: 设置对应类的日志级别

打印日志
打印日志
打印日志分为 2 个步骤
- 得到日志
- 使用日志打印相关内容
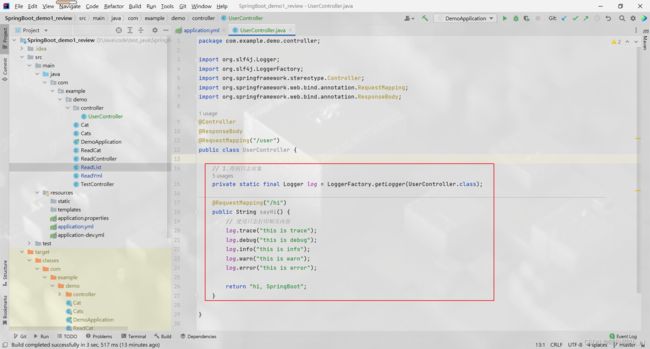
得到日志
private static final Logger log = LoggerFactory.getLogger(UserController.class);
对于getLogger(), 括号中的内容为日志的归属类
即打印的日志信息是关于哪个类的信息
使用日志打印相关内容
log.trace("this is trace");
log.debug("this is debug");
log.info("this is info");
log.warn("this is warn");
log.error("this is error");
运行查看结果

结果分析
想要显示的日志内容为 5 个, 分别是
- this is trace
- this is debug
- this is info
- this is warn
- this is error
运行结果却只显示其中 3 个
这是因为日志级别的缘故
默认的日志级别是 info
日志级别 ≥ 默认级别时才会被打印
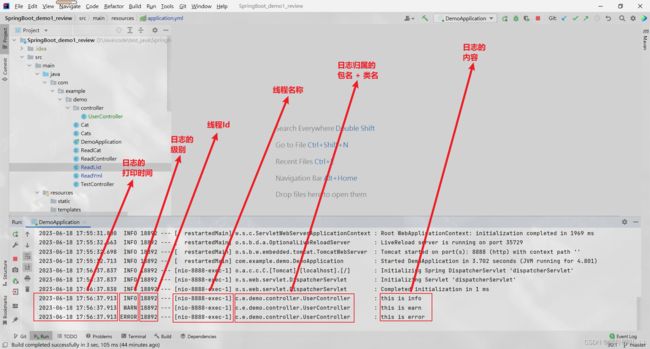
具体内容划分
日志的内容可划分为 6 个部分
- 日志的打印时间
- 日志的级别
- 线程Id
- 线程名称
- 日志归属的包名 + 类名
- 日志的内容
常用的日志框架
- Spring Boot 内置的日志框架
- SLF4J
- logback

举个栗子
将 Spring Boot 框架看作是餐厅
日志门面看作是餐厅的服务员
日志实现看作是餐厅的厨师
而我们则是来餐厅吃饭的顾客
顾客来到餐厅 → 喊服务员点餐 → 服务员将菜单送给厨师 → 厨师根据菜单做菜
在这个过程中顾客并不关心菜是如何制作的, 只要保证能将菜做好即可
Spring Boot 框架也是如此
程序员(顾客)来到餐厅 → 喊服务员(日志门面)点餐 → 服务员(日志门面)将菜单送给厨师(日志实现) → 厨师(日志实现)根据菜单做菜
为什么这样设计
根据上面的描述提出一个疑问
为什么这样设计?
解耦合
上述流程是这样的
程序员调用日志门面, 日志门面调用日志实现
(程序员 → 日志门面 → 日志实现)
但如果程序员直接调用日志实现
(程序员 → 日志实现)
则会面临如下情况
程序员编写对应的 logback 代码
有一天 logback 这个对应的接口出现了严重的 BUG
无奈之下, 只能更换为其他接口
由于之前一直使用 logback 这个接口, 因此需要修改的业务量比较庞大
(即使全部修改, 也会面临其他接口他日出现重复的问题)
这就导致了高耦合
对比System.out.ptintln()与日志框架
- System.out.ptintln() 能够打印信息, 但与日志框架相比, 缺少打印的时间, 信息的来源, 信息归属的包名 + 类名…
- System.out.ptintln() 只能将信息打印, 无法隐藏(日志框架可以通过设置日志的级别进行相关日志的隐藏 / 显示)
日志的持久化
日志的持久化
将日志中的内容保存至指定位置的过程
name, 保存日志的名称(可省略, 省略则使用默认提供的名称spring.log)
path, 保存日志的路径(可省略, 省略则使用默认提供的路径)
logging:
file:
name:
path:
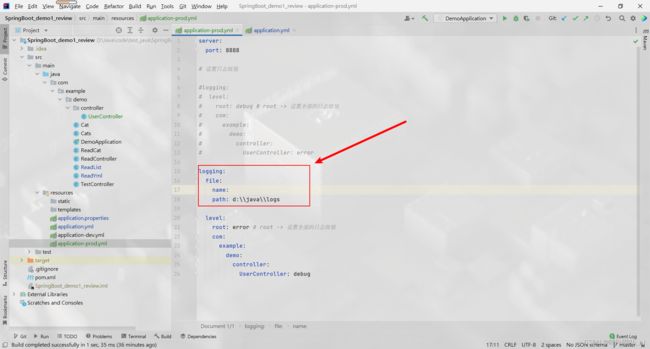
保存的指定路径 + 默认名称
注意
保存的路径不存在时, 系统会自动创建

保存的默认路径 + 指定名称
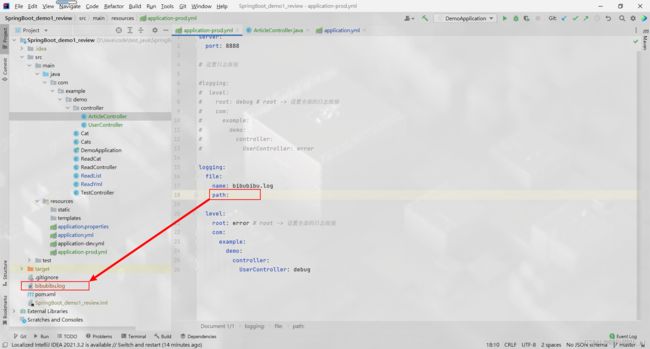
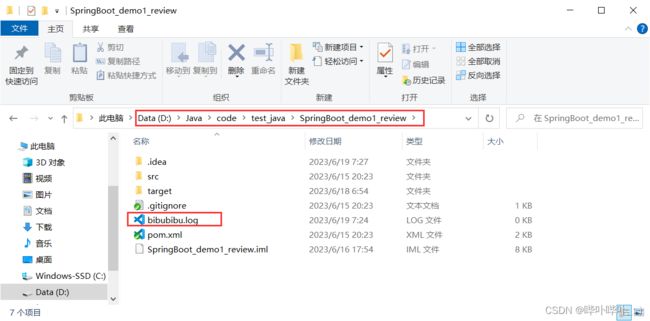
注意
日志的存储方式是追加而非覆盖
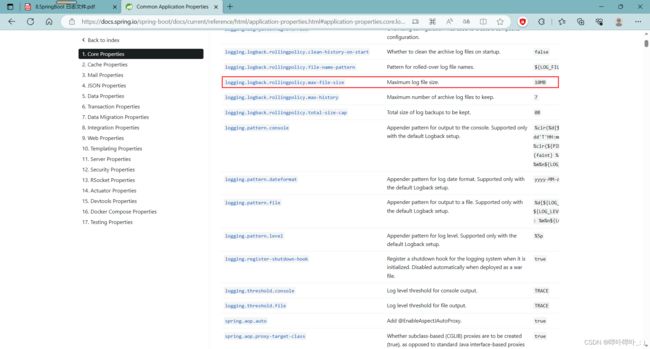
存储日志的最大容量默认为 10MB
超过该容量会自动创建一个新的文件进行存储
追加, 即在原日志文件的基础上继续存储新的日志内容(但超过 10MB 后会自动创建一个新的日志文件承接原日志文件)
覆盖, 即新的日志内容将原日志文件进行更替
Lombok—更简单的打印日志
对比得到日志的方式
一般得到日志的方式
private static final Logger log = LoggerFactory.getLogger(ArticleController.class);
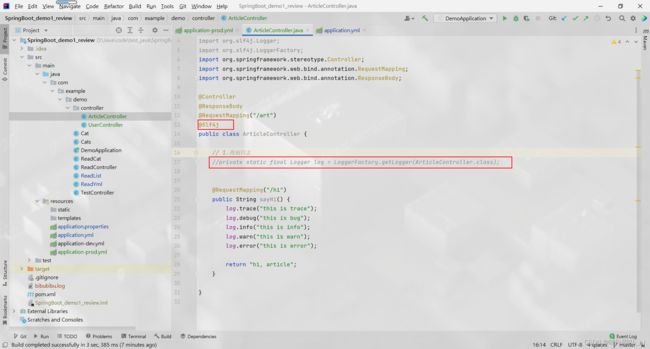
Lombok 得到日志的方式
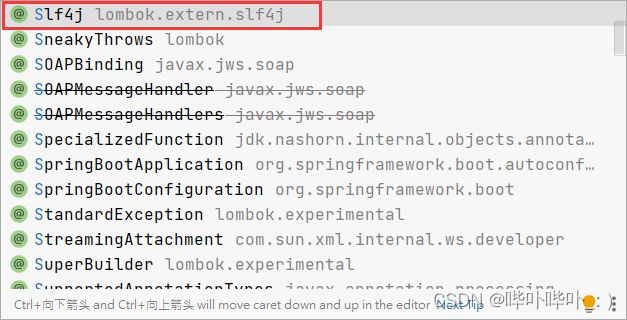
@Slf4j
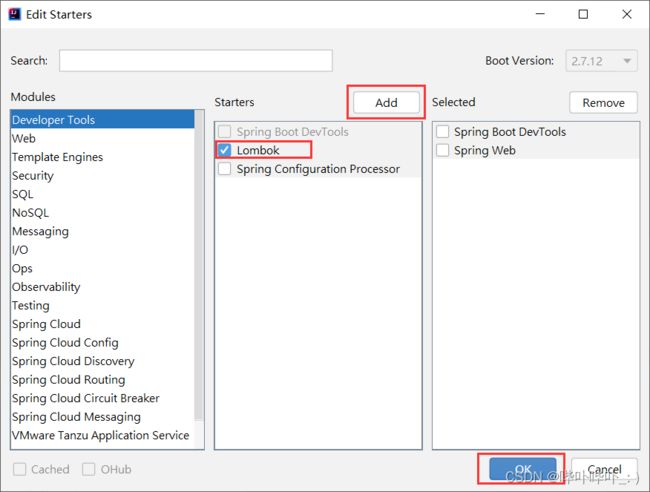
创建SpringBoot项目时忘记添加Lombok怎么办
- 引入插件
- 在 pom.xml 文件中进行添加
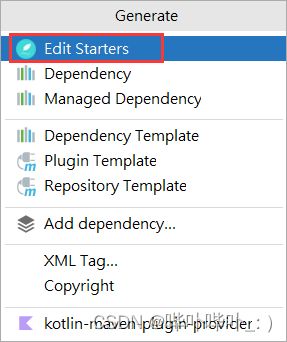
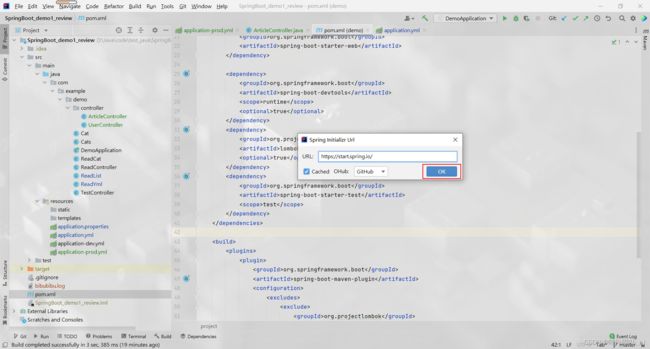
引入 EditStarters 插件

在 pom.xml 文件中单击右键 → Generate → Edit Starters → OK → 添加 Lombok

结尾
创作不易,如果对您有帮助,希望您能点个免费的赞
大家有什么不太理解的,可以私信或者评论区留言,一起加油