【ReID】EANet: Enhancing Alignment for Cross-Domain Person Re-identification
【ReID】EANet: Enhancing Alignment for Cross-Domain Person Re-identification
-
-
- 痛点
- 模型
- 实验
- 问题
- 参考文献
-
文章在PCB[1]方法的基础上提出Part Aligned Pooling (PAP),和基于多任务训练的Part Segmentation (PS)约束方法,一个用了pose keypoint estimation,一个用了semantic segmentation,通过对局部切片特征的对齐和分割模型训练,让ReID模型在跨域目标域(无标签)的识别表现得到提高,且这两个方法能跟其他跨域行人重识别方法互补兼容,具备作为通用方法的可能。实验在四个benchmark:Market1501, CUHK03,DukeMTMC-reID,MSMT17上进行。文章方法均达到了当时的SOTA。
论文一览:

痛点
行人重识别是视频监控中的一项基本任务,可用于行人检索和跨摄像机跟踪等。其目的是预测来自不同摄像机的两个图像是否属于同一个人。 借助大规模数据集以及改进的特征提取和度量学习方法,近年来,在单域设定下,这项任务有了很大的改进。
单域学习已经取得了长足的进步,但在跨域场景现有ReID模型表现会遭遇巨大的下降,跨域ReID仍然面临着巨大的挑战。当直接在看不见的领域中使用模型时,性能会大大下降,这在新数据集上测试模型时很明显。 部分原因是由于ReID的zero shot设定,所以在训练过程中从未看到过测试身份。 域之间的数据分布差异也可能很重要,例如 Market1501的行人通常穿着短裤,而DukeMTMC-reID则是裤子和外套。 由于跨摄像机人员分组的成本很高,因此为每个场景构建训练集会很昂贵。 因此,对于跨域ReID,(1)在源域上进行训练时提高模型的通用性;(2)在没有任何目标域标识的情况下使模型适应新域的问题非常重要。

如上图,本文首先拓展了PCB的工作,作者认为PCB虽然达到了当时的SOTA,但无法解决由检测框失误带来的不对齐问题。本文工作根据人体关键点,为局部特征做隐式对齐的pooling,如人体关键点将由单独的pose estimation model从COCO数据集上训练获得。
本文还发现局部特征计算距离矩阵的时候,相邻块的距离太过接近,作者认为这是由于1 模型缺乏定位能力,2 不同区域之间的特征冗余。而这多半是CNN最后层conv感受野已经非常大了导致。作者据此引入了能够提高定位能力的part segmentation约束,在ReID模型上连接分割模块,在COCO Densepose上用一个模型训练好,在目标域制造伪分割标签,最后让ReID根据这个伪分割标签来训练模型,学习分割约束。以此提高模型泛化能力。
模型
回顾一下PCB模型,假设CNN输出的特征图为G,size为(C,H, W),被切分为p块,假设第p块切片的特征向量为g_p,经过第p个嵌入层f_p有e_p = f_p(g_p),最后连接classifier W_p,然后求id loss。PCB中所有切片的loss会求和再backprop。
本文在这个基础上使用人体关键点来对齐 ,利用这些关键点作者定义了9个区域,头,上躯干,下躯干,大腿,小腿,脚,上半身,下半身,全身,如图1。其中有6个区域,类比PCB的6个区域,还有3个多余区域,用来补偿关键点没有检测到的地方。如图1b的情况脚丢失了,这时pooling不进行,而直接令C维向量取0向量,该项的loss也直接取0,公式如下:

test时计算query和gallery的距离有:
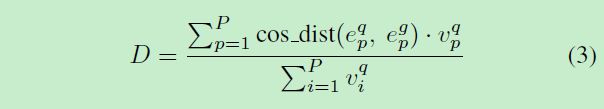
下标p代表第p块切片,上标q和g分别代表query和gallery,v为刚刚的是否可见标志位。如果某块切片不可见则置零,求得的距离也是0。
EANet模型结构图如下:

PS原理也很简单, 直接添加一个语义分割模块,让网络同时进行ReID任务和语义分割任务的训练,相当于把人体分割定位的约束施加给了模型,从而增强网络的定位能力。如上图,PS模块由一个stride=2的3x3 Deconv 和一个1x1 Conv层组成,Deconv用于上采样,而Conv层用于求pixelwise的loss。而语义分割的标签需要自己生成,作者另外使用一个语义分割网络在COCO Densepose数据集预训练,再用于source/target domain的数据集生成分割伪标签,再再用于ReID PS模块的训练,以此引入语义分割对位置定位的监督。
PS求loss如下

这里k表示第k个区域,多个loss(这里用cross-entropy loss)取平均得到总loss,最后对单个loss做优化。求平均可以防止某个大区域主导了loss值,忽视了一些小区域的影响,比如其实脚部也是ReID很重要的辨别区域。
多任务联合训练公式如下:
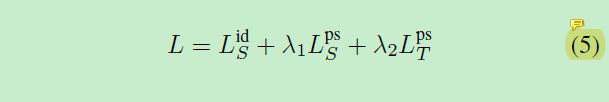
下标S为source域,T为target域,上标id为id loss即ReID任务,ps为分割任务。可以看到target域也要进行分割任务的训练。source域则两个都要。这里λ取1。
实验
本文的实验做的比创新点要出彩,实验在四个benchmark上进行。market1501用M表示,cuhk03用C表示,DukeMTMC-reID用D表示,MSMT17用MS表示。
PCB和使用了PAP的跨域学习对比如下:

PAP基础上加上PS的分离实验如下:

其中的S表示PS只在source域使用,ST表示在source域和target域使用,SA表示PS任务使用了平均分割任务loss的策略。
可视化结果如下:

每三个图为一个对照组,左边的分割结果为只在source域训练的结果,右边为source和target域都有训练的结果。
不同part的距离矩阵如下(一部分),可以看到区分度越来越高了,距离也拉得开了:

对PS在source、COCO域和两者兼有的分离试验:

C表示在COCO上有预训练,StC表示COCO with market1501 style。风格迁移用了SPGAN来完成。
风格迁移与伪标签的实验如下:
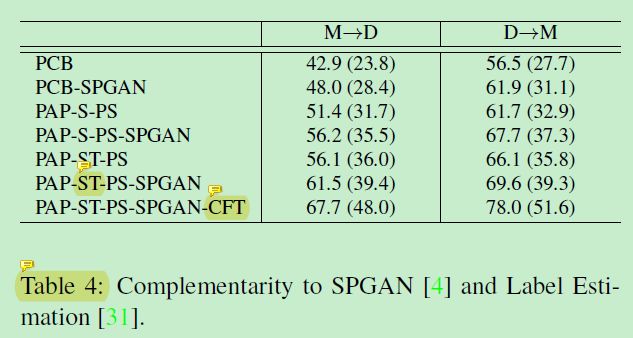
CFT表示使用了伪标签且微调了。
单域SOTA实验如下

跨域SOTA实验如下:
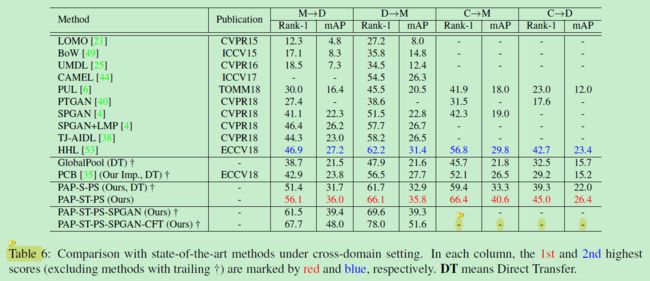
MSMT17的分离实验如下:

嵌入层的size分离实验如下:

问题
这个EANet[1]是题眼,但文章全程在讲PAP和PS,里面就没出现过EANet。。。这个EANet意义何在?
PAP想法很好,但是需要通过额外训练pose estimation model来找关键点,这个过程还不是端到端的,训练过程就很复杂,太麻烦,额外增加训练时间。
PS的问题也是一样,无法落地,且不说加不加入GAN 风格迁移到COCO这一步,就光是要找一个语义分割网络在COCO上训练,再生成target的伪标签,这一步就足够繁琐了。如果扩充了target domain的数据,又要重新生成语义分割的伪标签。有这闲工夫还不如直接GAN造图来的方便,所以个人认为实用价值不大。
参考文献
[1] Sun Y, Zheng L, Yang Y, et al. Beyond part models: Person retrieval with refined part pooling (and a strong convolutional baseline)[C]//Proceedings of the European Conference on Computer Vision (ECCV). 2018: 480-496.
[2] Huang H, Yang W, Chen X, et al. EANet: Enhancing alignment for cross-domain person re-identification[J]. arXiv preprint arXiv:1812.11369, 2018.